Google Patents a Mixture-of-Experts AI System for Smarter Video Compression
Google is patenting an AI-driven video compression system that uses a team of machine learning models — not just one — to decide how to shrink each block of video more intelligently by looking at what changed between frames.
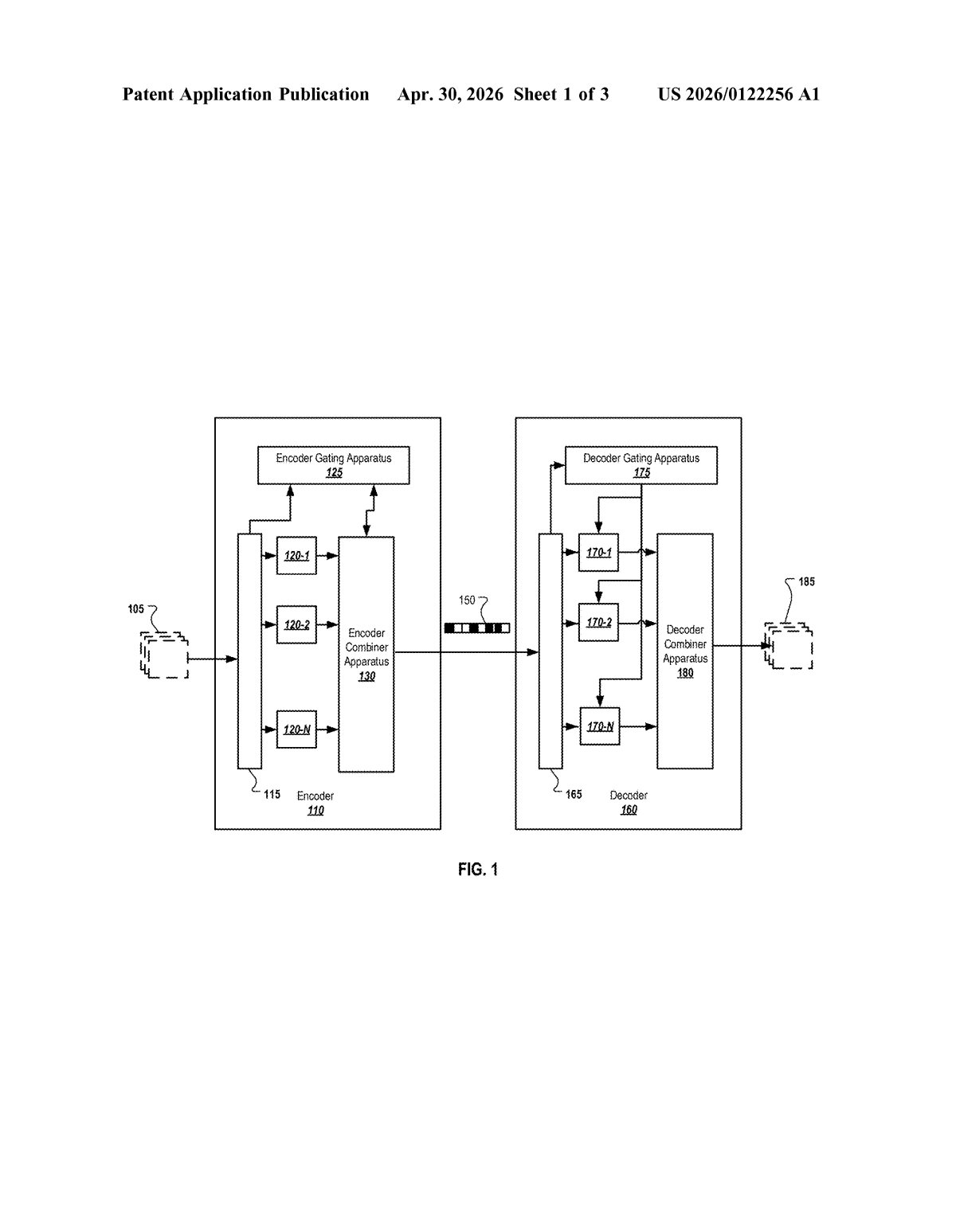
What Google's AI video compression actually does
Imagine you're watching a video call and the background barely moves, but your friend's hand is waving around. A smart compression system shouldn't treat those parts of the video the same way — the still background can be compressed aggressively, while the moving hand needs more detail preserved.
That's the core idea behind Google's new patent. Instead of applying a single, one-size-fits-all compression rule, it uses an ensemble of machine learning models (a so-called "mixture of experts") to analyze each small block of a video frame. Each model specializes in different kinds of content or motion patterns.
Critically, the system doesn't just look at the current frame in isolation. It compares each block to the same region in the previous frame, using the edges and borders of those blocks as key signals. That lets it make smarter predictions about what information actually needs to be transmitted — and what can be inferred.
How the ensemble model compares blocks across frames
The patent describes a video codec (compression/decompression system) built around a mixture-of-experts (MoE) architecture — a design where multiple specialized ML models each handle different parts of a problem, and a routing mechanism decides which expert to use for a given input.
The system divides each video frame into a grid of blocks (small rectangular regions, a standard approach in video codecs like H.264 or AV1). It then processes frames in sequential pairs — always looking at the current frame alongside the prior frame.
For each block, the prediction model receives four key inputs:
- The first and second borders (edges) of the current block in the current frame
- The first and second borders of the corresponding block in the prior frame
- The actual pixel content of the prior frame's block
By feeding in border information from both frames, the model can infer how a region has changed — capturing motion and texture shifts — without needing to transmit every pixel. The ensemble approach means different experts can specialize in, say, high-motion blocks versus static backgrounds, potentially outperforming a single monolithic model on diverse video content.
What this means for streaming and video quality
Video compression is one of the most computationally expensive and strategically important problems in tech. Google serves YouTube — one of the world's largest video platforms — and any efficiency gain in its codec translates directly into lower bandwidth costs and better quality at the same bitrate for billions of streams. Even a few percentage points of compression improvement at YouTube's scale is worth enormous infrastructure savings.
The MoE framing is notable because it mirrors the architecture trend reshaping large language models (think GPT-4 and Gemini). Applying that same "team of specialists" logic to a low-level signal processing problem like video compression is a genuinely interesting crossover. If this approach works well in practice, it could eventually influence open standards like AV2 or future VP-series codecs that Google actively develops.
This is a legitimately interesting patent — not because MoE is a new idea, but because applying it to per-block video prediction is a concrete, testable engineering bet. Google has the YouTube traffic to validate it at scale, and the team includes Debargha Mukherjee, a key figure behind the AV1 codec. Worth keeping an eye on.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.