Google Patents a Self-Tuning Analytics Engine That Adjusts Mid-Batch
Most database engines pick a query strategy before they start and stick with it, even if it turns out to be wrong. Google's new patent describes a system that learns from the first few queries in a batch and quietly reconfigures itself for everything that comes after.
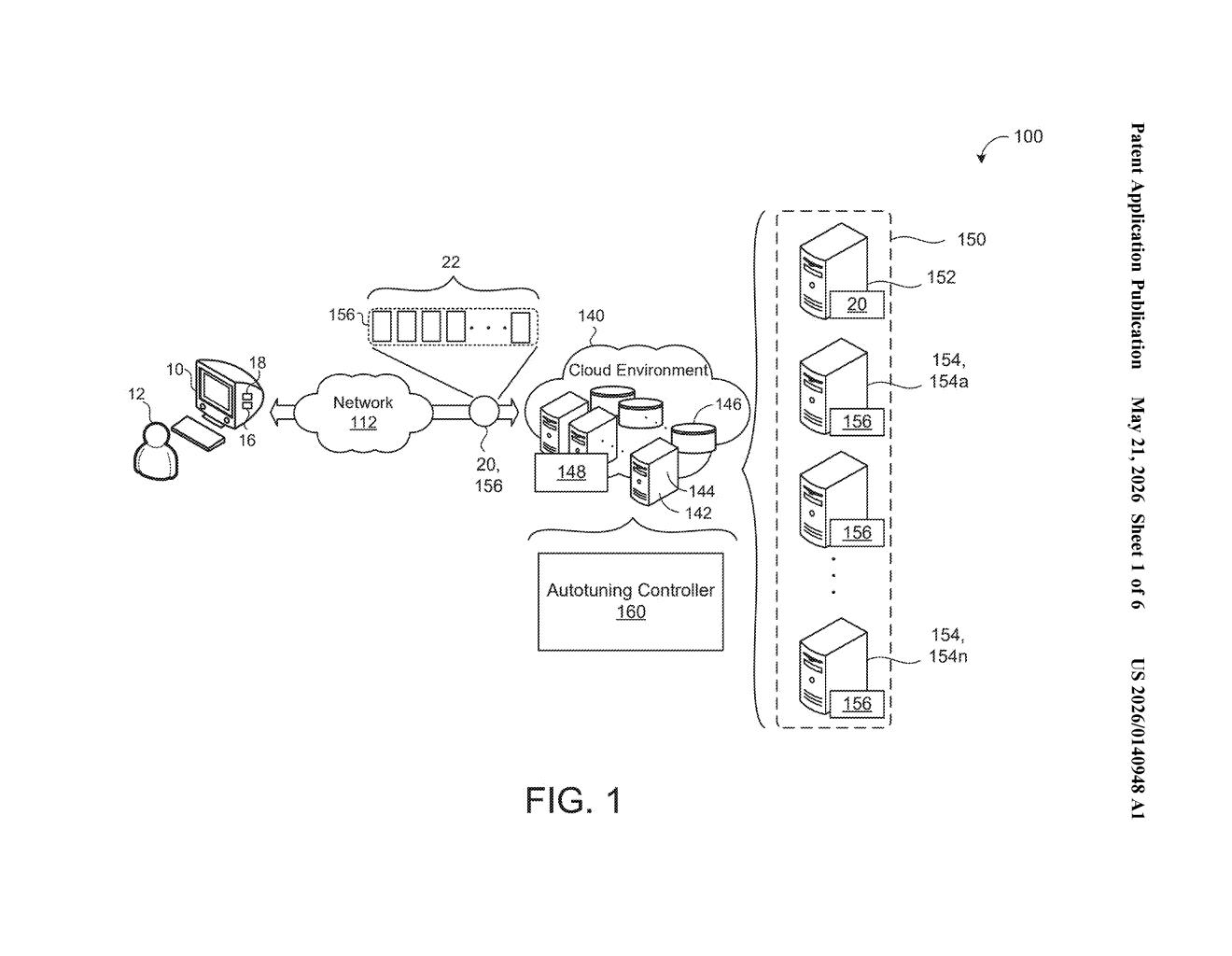
What Google's mid-batch query autotuning actually does
Imagine you're running a long to-do list through a factory. The factory starts with a default setup — say, a particular conveyor belt configuration — and runs the first few tasks. Halfway through, a manager reviews what worked and retunes the machines before tackling the rest. Google's patent applies exactly that idea to database query processing.
When you submit a big batch of data queries (called a cohort of workloads), Google's analytics engine doesn't just execute them all with the same fixed settings. Instead, it runs the first portion using a default configuration, watches how those queries perform, and then updates its strategy — specifically, how it handles "join" operations, which are the most expensive part of combining big tables of data.
The second half of your batch then runs with those improved settings. You get all the results together at the end, but the engine has effectively learned on the job. It's a bit like a chef tasting the first few dishes and adjusting the seasoning before finishing the rest of the order.
How the join configuration updater rewires queries on the fly
The core mechanic here is adaptive join configuration. In distributed query engines, a "join" is when two or more large datasets are combined — think merging a table of user IDs with a table of purchase records. Choosing the wrong join strategy (broadcast join vs. hash join vs. sort-merge join, for example) can cause a query to run 10x slower than necessary because the engine misjudges data sizes or skew.
Traditionally, an analytics engine picks a join strategy at query-planning time using statistics about the data — statistics that are often stale or incomplete. This patent takes a different approach:
- A cohort (an ordered batch of related workloads) is submitted by the user.
- The engine runs the first portion using a default join configuration.
- A Join Configuration Updater module analyzes execution telemetry from those completed queries — things like actual row counts, shuffle sizes, and memory pressure.
- It produces an updated join configuration that better reflects the real characteristics of the data.
- The remaining workloads in the cohort run with the new configuration, without the user needing to intervene.
Critically, the serial execution order of the cohort is preserved throughout — the system isn't reordering your queries, just changing how it executes them.
What this means for BigQuery and large-scale data workloads
For anyone running large-scale analytical workloads on a platform like BigQuery, this kind of mid-batch adaptation could meaningfully cut both query latency and compute cost. The expensive part of distributed SQL isn't reading data — it's shuffling it across machines during joins. Getting that wrong on a 500-query batch job means paying the penalty hundreds of times over.
The broader significance is that this moves part of the query tuning burden away from the user. Right now, data engineers spend real time tweaking join hints and optimizer flags. A system that auto-corrects itself after seeing real execution data is a step toward analytics infrastructure that's less fussy to operate — which matters a lot as data workloads scale up.
This is solid, unsexy infrastructure work — exactly the kind of thing that makes enterprise cloud databases quietly better over time. It won't headline a Google I/O keynote, but if it ships in BigQuery, it's the sort of improvement that saves data engineering teams hours of manual tuning every week. Worth paying attention to if you care about the managed analytics space.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.