Microsoft Patents an Ontology-Driven RAG System That Structures Docs as Hypergraphs
Most AI retrieval systems treat documents like bags of sentences — Microsoft's new patent wants to treat them like structured knowledge maps, using a formal ontology to extract relationships and a hypergraph to capture context no single sentence can hold.
What Microsoft's hypergraph RAG actually does for AI answers
Imagine asking an AI assistant a question about a complex business contract. A typical AI system would search for sentences that sound similar to your question and hand those to the model — but it might miss the clause that only makes sense if you already know three other facts buried elsewhere in the document.
Microsoft's patent describes a different approach. Before the AI ever answers a question, the system reads your documents through the lens of a predefined ontology — essentially a schema that says, "in this domain, the things that matter are entities like companies, contracts, and obligations, and these are the relationships between them." It uses that schema to extract structured facts and build a hypergraph, a kind of relationship map that can link more than two things at once (unlike a standard graph, which only connects pairs).
When you ask a question, the system finds the most relevant clusters of connected facts in that hypergraph and feeds the whole cluster to the language model — not just matching sentences. The idea is that the model gets richer, more coherent context rather than isolated text snippets.
How the ontology maps documents into hyperedges
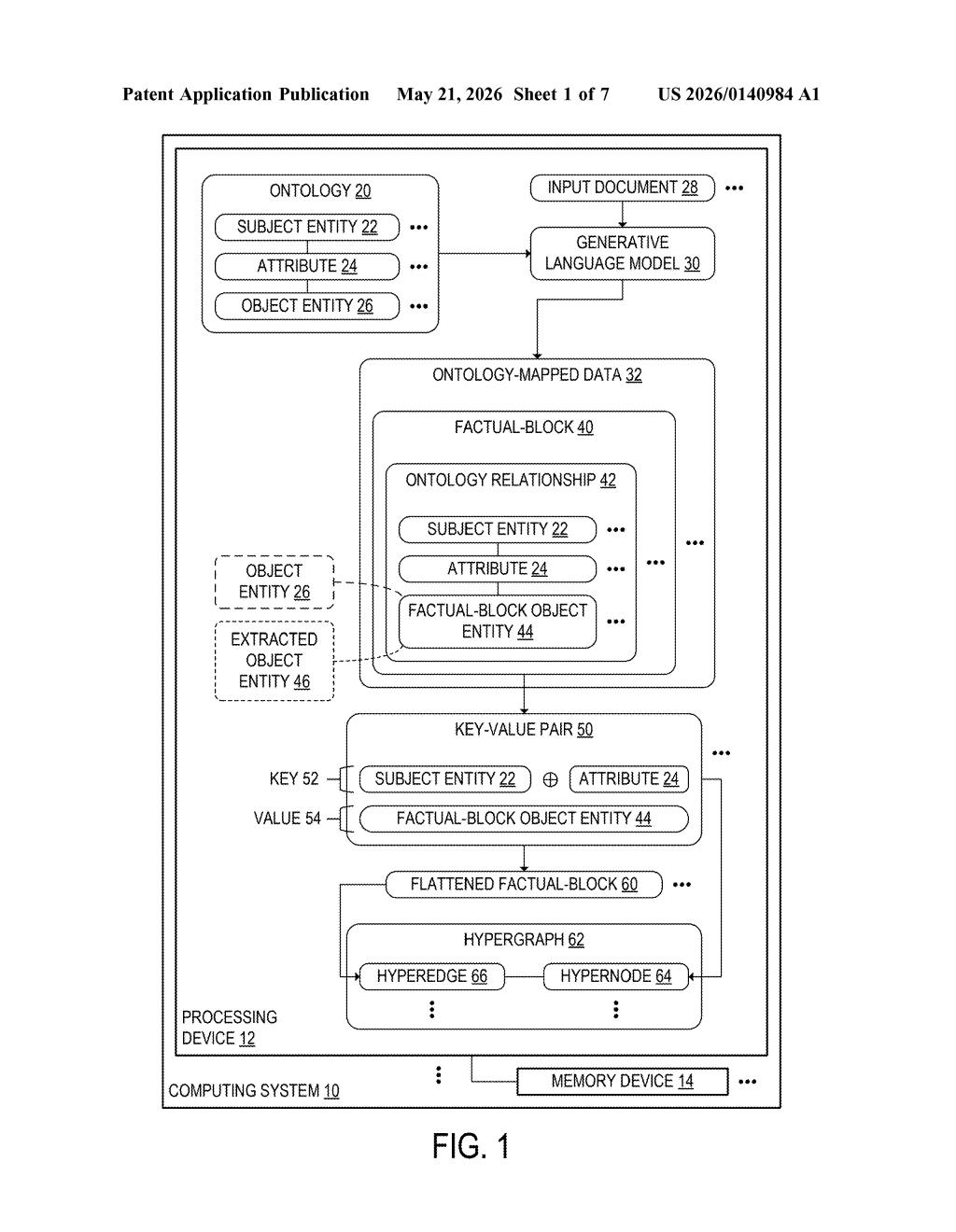
The system has four main stages that work in sequence before you ever see an answer.
Stage 1 — Ontology-mapped extraction: The system ingests an ontology (a formal vocabulary defining entity types, attributes, and relationships for a domain — think of it as a data contract for the subject matter). It reads input documents and extracts only facts that fit the ontology, producing structured key-value pairs organized into what the patent calls "factual blocks" — each one anchored to a subject entity, attribute, and value.
Stage 2 — Hypergraph construction: Those factual blocks are "flattened" and assembled into a hypergraph. Unlike a normal graph where each edge connects exactly two nodes, a hyperedge can connect many nodes at once — useful for capturing a fact like "Company A acquired Company B in Deal C for Price D" as a single relationship rather than a chain of pairs.
Stage 3 — Similarity matching: When a query arrives, the system performs similarity matching (likely embedding-based vector search) against the hyperedges — not raw text — to surface the most contextually relevant clusters of structured facts.
Stage 4 — Grounded generation: The retrieved hyperedges (and their connected hypernodes) are passed as context to a generative language model, which produces an answer grounded in structured, schema-validated information rather than raw passage snippets.
Why structured retrieval could beat vanilla RAG for enterprise AI
The core problem with standard RAG (retrieval-augmented generation) is that similarity search over raw text chunks is noisy — you get fragments that sound relevant but lack the surrounding context needed to reason correctly. Grounding retrieval in an ontology means the system only surfaces facts that are structurally coherent with the domain, reducing the hallucination risk that comes from half-relevant passages.
For enterprise use cases — legal analysis, financial document review, clinical records, supply chain data — this kind of structured retrieval could be a real step up from generic RAG pipelines. If you're building AI tools on top of domain-specific document corpora, having a schema-aware retrieval layer is the difference between a chatbot that sometimes gets it right and one you can actually trust with high-stakes queries.
This is a genuinely interesting engineering approach to a real problem, not a routine filing. The hypergraph framing addresses a known limitation of vector-similarity RAG — that flat text chunks lose relational structure — and the ontology-grounding step adds a layer of domain specificity that most off-the-shelf RAG pipelines lack. Whether it's commercially practical depends heavily on how much work building and maintaining that ontology requires, which the patent conveniently doesn't address.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.