Nvidia Patents ML-Driven Road Hazard Detection Using Stereo Camera Disparity
Nvidia has filed a patent for a machine learning system that detects road hazards — potholes, debris, obstacles — by comparing tiny pixel mismatches between two cameras mounted on a self-driving vehicle. It's a clever twist on how stereo vision already works, turned into an active safety net.
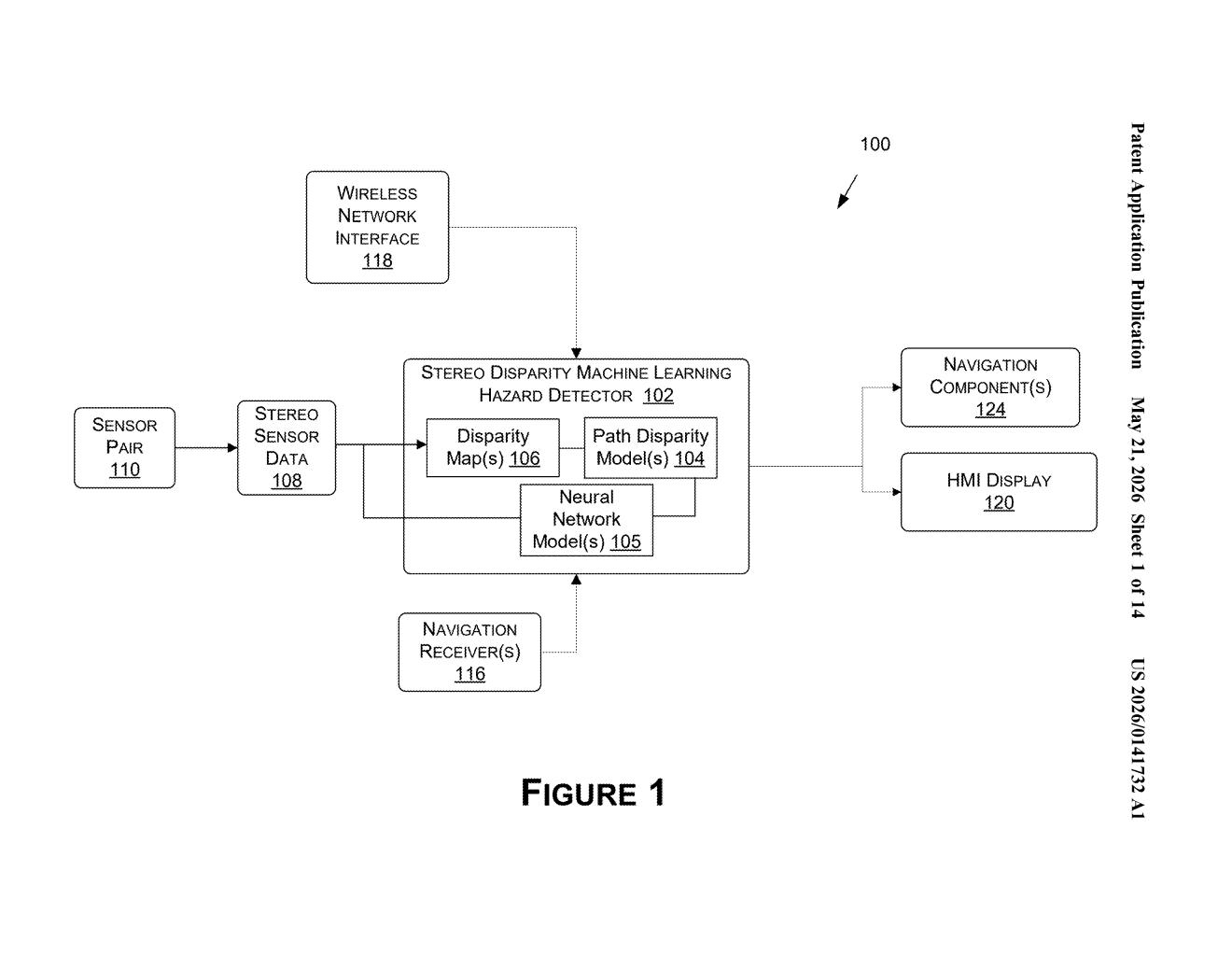
How Nvidia's stereo-camera hazard detector spots danger
Imagine holding your hand in front of your face and closing one eye, then the other. Your hand appears to jump sideways — that shift is called disparity, and your brain uses it to judge depth. Self-driving cars do the same thing with two cameras mounted side by side.
Nvidia's patent takes that idea one step further. Instead of just measuring depth, it builds a baseline model of what the road ahead should look like through those two cameras. If a pixel pair from both cameras doesn't match the baseline — say, because there's a pothole or a rock in the way — the system flags it as a potential hazard.
Once suspicious pixels are identified, nearby flagged pixels get grouped together to form a coherent picture of the hazard. That information then feeds directly into the vehicle's navigation and control systems, so the car can steer around the problem or slow down in time.
How disparity deviation flags hazard pixels on the road
The system starts by ingesting a stereo image pair — two slightly offset images from cameras with overlapping fields of view. It calculates disparity values (the pixel-level offset between matching features in both images) to build a path disparity model: essentially a learned expectation of what the drivable surface should look like in disparity space.
A machine learning classifier then compares real-time disparity readings against that model. When a pixel's disparity deviates from the expected road surface by more than a set threshold, it's tagged as a hazard pixel. The key insight is that the ML model uses feature vector similarity metrics — mathematical representations of local image texture and structure — so it can still match corresponding pixels even when lighting, color, or surface conditions make them look slightly different to a naive comparison.
The patent also describes an optional optimization: projecting the disparity data into a V-space disparity map, where one axis represents disparity values and the other represents pixel rows. This compressed 2D representation makes it faster to estimate the road surface model without processing every pixel individually.
- Hazard pixels are clustered with neighboring flagged pixels to form coherent obstacle regions.
- Those regions feed directly into planning, navigation, and control operations for the ego-vehicle.
- The approach handles wet roads, shadows, and low-contrast surfaces better than simple depth thresholding alone.
What this means for autonomous vehicle safety pipelines
For autonomous vehicles, detecting low-lying hazards — a shredded tire on the highway, a shallow pothole, spilled gravel — is genuinely hard. Lidar can miss flat debris, and monocular cameras struggle with depth. Stereo vision is already common in AV sensor stacks, so a system that repurposes existing stereo hardware for active hazard detection rather than just depth mapping is an efficient win.
For Nvidia, whose DRIVE autonomous vehicle platform competes directly with Mobileye, Qualcomm, and others, this kind of perception IP helps differentiate its stack at the software and model level — not just the chip level. If this approach gets baked into DRIVE inference pipelines, it could quietly raise the bar on what a "standard" AV perception suite is expected to handle.
This is solid, practical AV perception work rather than a moonshot idea. The V-space disparity map optimization in particular is the kind of engineering trade-off that signals this came from people actually running inference on constrained automotive hardware. It won't make headlines at a consumer keynote, but it's exactly the type of low-level safety IP that matters when you're trying to certify a self-driving system.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.