Google's New Patent Trains AI on Your Data Without Ever Seeing the Full Picture
Google is patenting a way to train AI models on your personal data without any single computer — not even Google's own servers — ever having access to the complete profile. It's a privacy architecture that tries to make 'we never see your data' technically true, not just a policy promise.
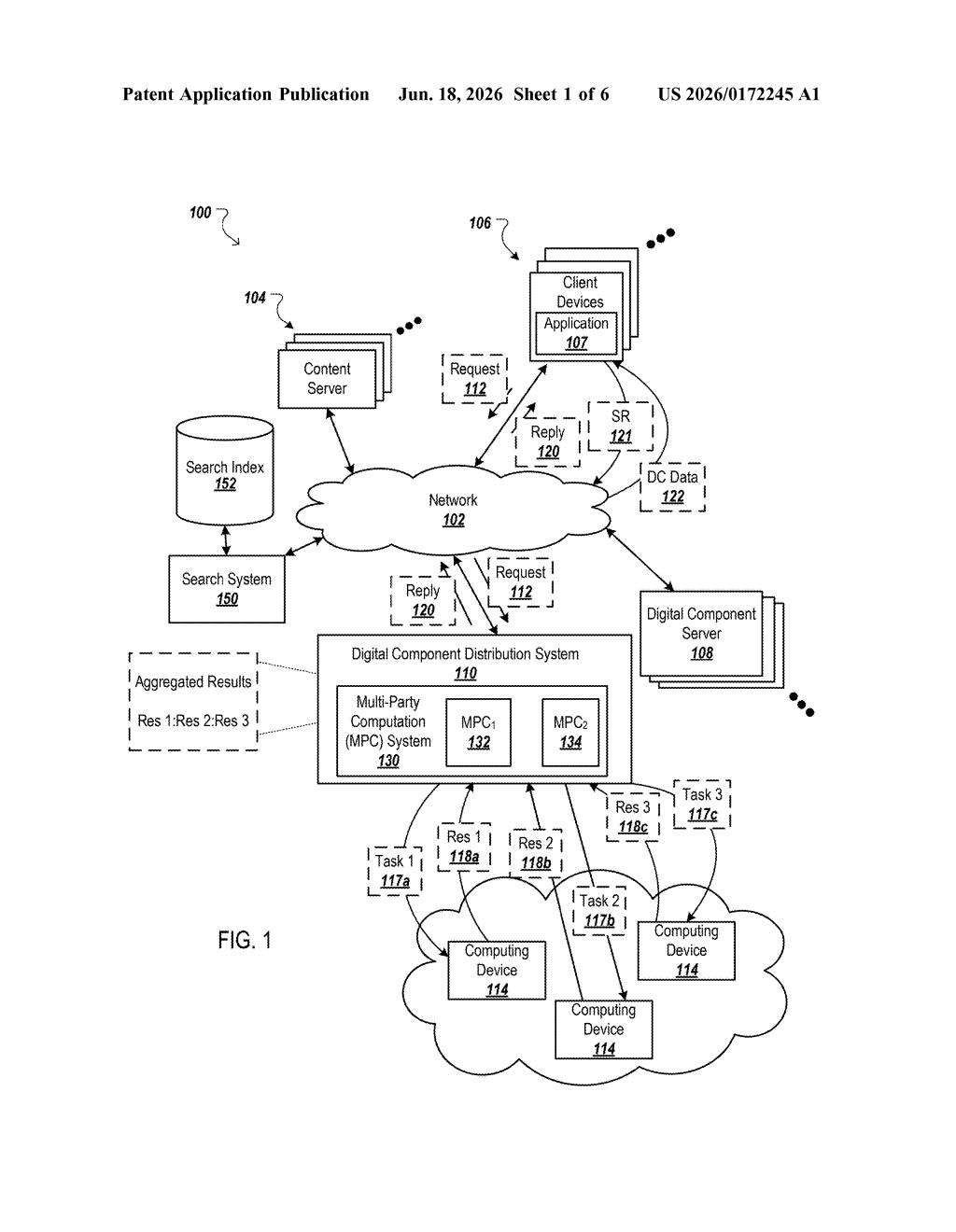
How Google splits user data so no one gets the full picture
Imagine your bank split your credit history in two and gave half to one analyst and half to another — neither analyst could ever reconstruct your full file, but together they could still run the numbers and spot fraud. That's essentially what this patent does with user profiles and AI training.
Google's system divides your data into two pieces and sends each piece to a separate server. Neither server ever holds enough information to know who you are or see your complete profile. But the two servers can still cooperate — using a privacy technique called multi-party computation — to train an AI model and attach labels (like 'interested in travel' or 'likely to buy software') to each person.
The end result lands back with whoever asked the question, but at no point did any single machine have the full picture. It's designed for the kind of ad-targeting and content recommendation that normally requires crunching detailed personal data, built for a world where regulators and users are demanding more meaningful privacy protections.
How the two-server MPC training loop actually runs
The patent describes a multi-party computation (MPC) architecture — a cryptographic technique where two or more servers jointly compute a result without sharing their inputs with each other. Think of it as doing math on secrets without revealing the secrets.
Here's how the training pipeline works:
- A digital component distribution system (Google's ad infrastructure, essentially) splits each user profile into two partial "shares" — fragments that are individually meaningless without the other half.
- The first share goes to Server A; the second share (encrypted so Server A cannot read it) goes to Server B.
- Both servers cooperate to train a machine learning model using only their respective fragments — no single server ever assembles a complete profile.
- Each server independently generates a label (a classification, like an interest category) from its fragment. Server A collects Server B's label and combines both into the final response.
The key security guarantee is that the encryption scheme used on the second share specifically prevents Server A from decrypting or reading it directly. The architecture assumes the two servers do not collude — a standard assumption in MPC system design.
What this means for ad-targeting privacy promises
Ad-tech companies have faced years of regulatory pressure over how they handle user profiles — from GDPR in Europe to state privacy laws in the US. A system where no single server ever holds a complete user profile is a structural answer to that pressure, not just a policy one. If Google deploys something like this in its ad-targeting stack, it would make certain categories of data breach or subpoena far less damaging, because the complete data simply doesn't exist in one place.
For you as a user, this wouldn't change what ads you see or how AI models classify your interests — the output is the same. What changes is the attack surface: a hacker or government order aimed at one server walks away with only half the picture, which is cryptographically useless on its own.
This is serious privacy engineering, not a press-release promise. MPC-based training is a well-studied academic idea, and seeing Google file a detailed implementation patent for ad-labeling specifically suggests this is moving toward production infrastructure. Whether it fully satisfies regulators is a legal question, but architecturally it's a meaningful step beyond 'trust us.'
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.