Nvidia Patents a Vision-Language System That Spots and Reports Road Hazards Automatically
Nvidia is patenting a system that lets a vehicle's cameras and sensors automatically identify road hazards — potholes, debris, accidents — and push that information to navigation apps in real time, without a human ever filing a report.
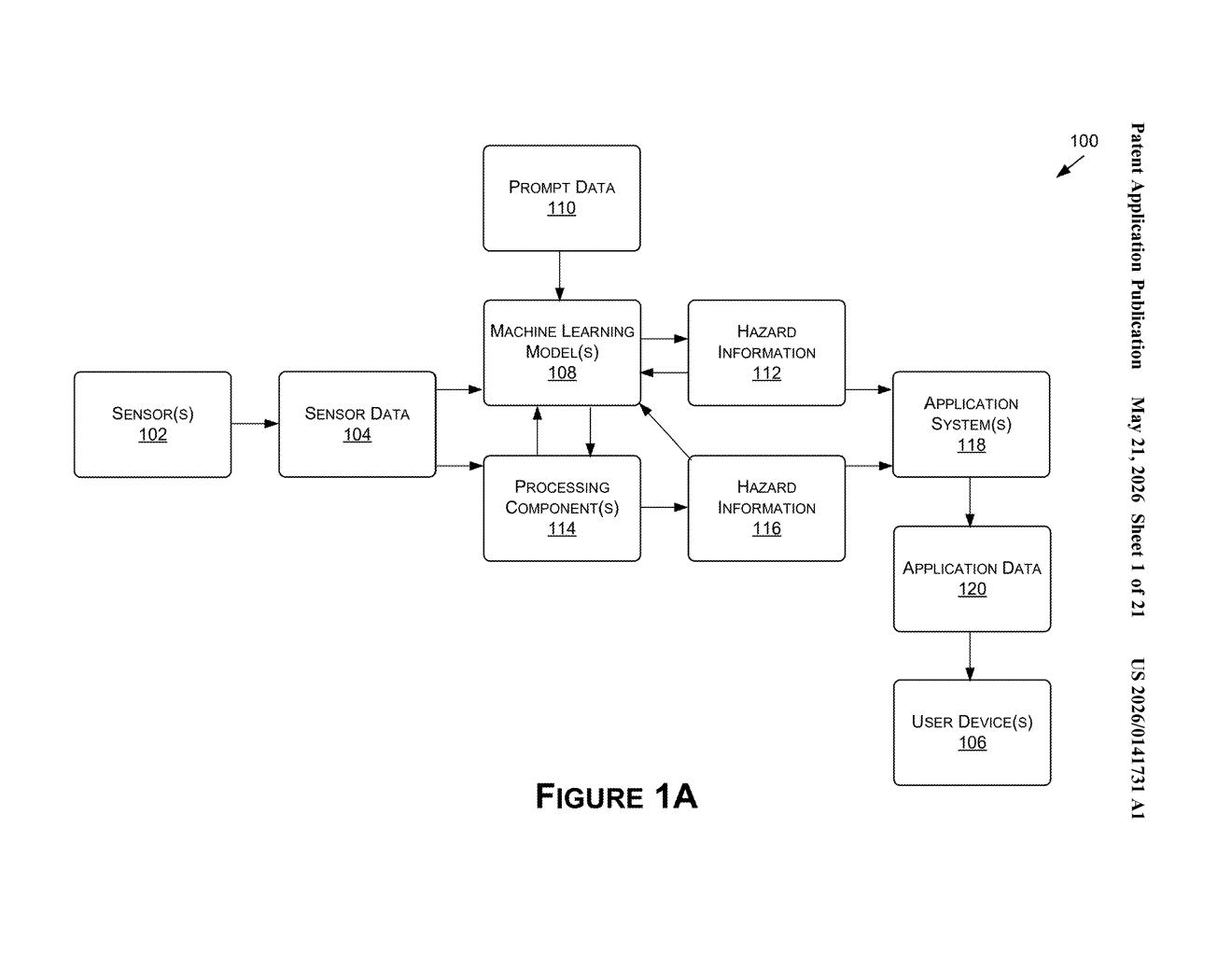
How Nvidia's AI turns dashcam footage into hazard alerts
Imagine driving down the highway when your car's cameras spot a piece of tire tread in the lane ahead. Instead of waiting for a road crew to notice it or a human to report it on Waze, your vehicle automatically identifies the hazard, figures out exactly where it is, and sends that information to a mapping service — all before you've even swerved around it.
That's essentially what Nvidia's new patent describes. A machine learning system — specifically a vision-language model, the same kind of AI that can look at a photo and describe what's in it — processes live camera and sensor feeds from a vehicle. It identifies hazards on the road and generates structured information about them: what the hazard is, where it is, and any other relevant details.
That data then gets pushed to external apps or systems — think navigation platforms or traffic services — so other drivers and autonomous vehicles can be warned automatically. It's like crowdsourced road reporting, but handled entirely by AI with no human in the loop.
How the vision-language model identifies and tags road hazards
The patent describes a pipeline with three main stages: localization, hazard detection, and reporting.
First, the system uses data from one set of sensors — likely GPS, lidar, or odometry — to pin down the vehicle's precise location within an environment. This gives any detected hazard a real-world coordinate to attach to.
Second, image data from a separate set of sensors (cameras, most likely) is fed into one or more vision-language models (VLMs) — AI models that can process visual input and produce natural-language descriptions or structured outputs. Crucially, the patent mentions prompt data being passed alongside the image data. This means the model isn't just watching passively; it's being actively asked questions like "Is there a road hazard in this image? If so, what kind and where?" That prompt-driven approach helps the model focus on safety-relevant details rather than describing the entire scene.
Third, the structured output — hazard type, location, severity, and other details — gets packaged and sent to one or more external systems. The patent specifically mentions updating applications, which points toward integration with navigation or fleet management platforms.
- Sensor fusion for precise location tagging
- Vision-language model inference on live camera feeds
- Prompt-guided hazard classification
- Automated data push to downstream mapping or safety apps
What this means for real-time mapping and autonomous driving
For autonomous vehicles and advanced driver assistance systems, the ability to detect and share hazard data without human intervention is a foundational capability. Today, most road hazard data relies on crowdsourced human reports (Waze, Google Maps) or expensive municipal road surveys. A system like this could dramatically accelerate how quickly hazard data propagates to other vehicles on the road.
For Nvidia specifically, this fits squarely into its DRIVE platform strategy — providing the AI compute and software stack that automakers and robotaxi companies build on. If vision-language models become a standard part of the in-vehicle inference pipeline, Nvidia's GPUs and software are the natural home for running them. This patent suggests Nvidia is thinking about the full loop: not just detecting the world, but acting on that detection at a network level.
This is a genuinely useful patent, not a defensive land-grab. Vision-language models are good at open-ended scene understanding, and using prompt-guided inference to focus them on road safety is a sensible application. The interesting design choice is treating hazard reporting as a network-level function — vehicles as mobile sensors feeding a shared map — which is exactly where autonomous driving infrastructure needs to go.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.