Nvidia Patents a Privacy-Routing System That Decides Which LLM Sees Your Query
Not every question you ask a chatbot should go to the same model — Nvidia's new patent describes a system that automatically sniffs out whether a query is sensitive, then routes it accordingly, keeping private data away from models that might leak or log it.
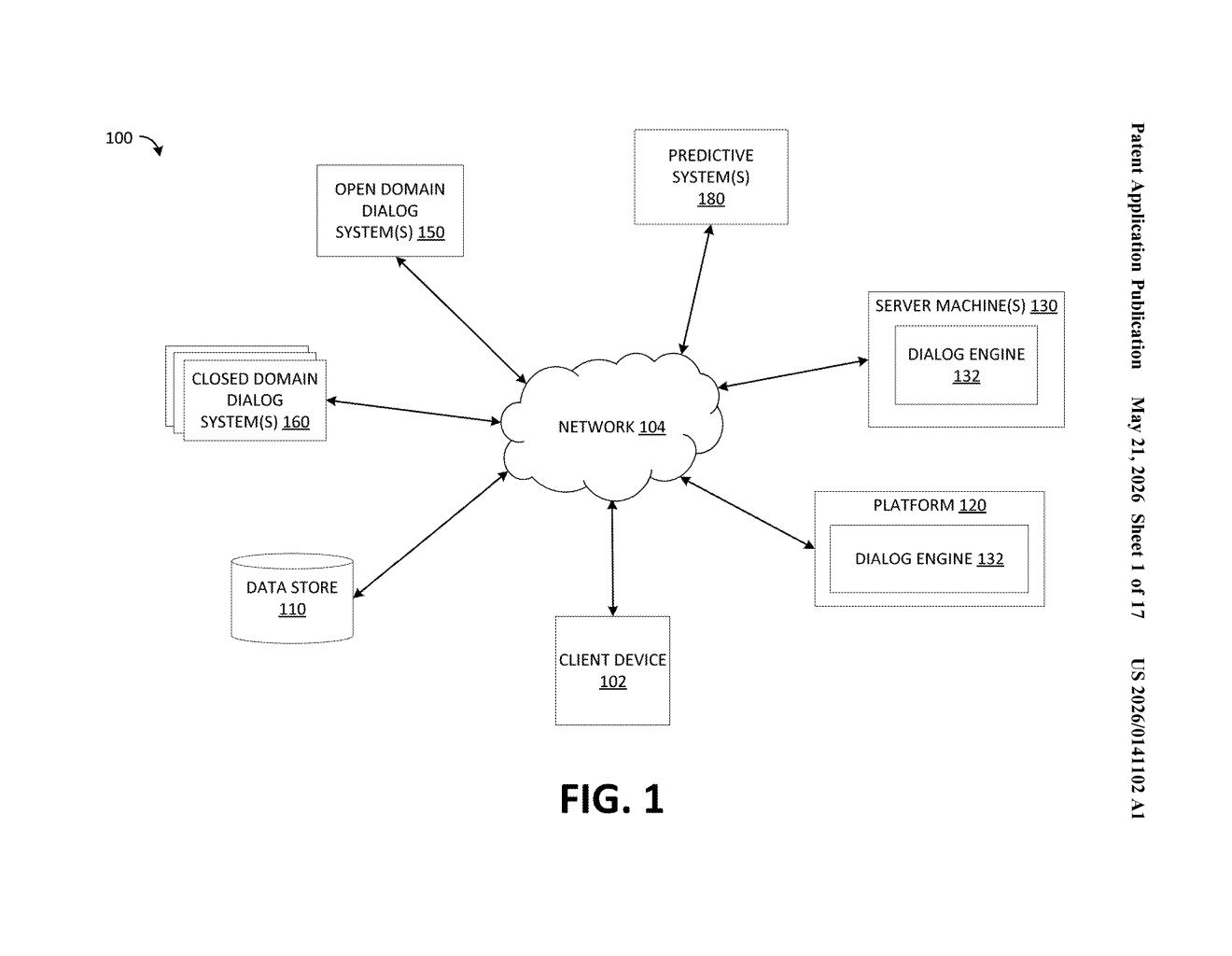
How Nvidia's system keeps sensitive queries off public AI
Imagine your company uses an AI assistant for everything from answering general how-to questions to processing confidential HR records. The problem: you probably don't want your private salary data or medical history going through the same public-facing AI model that cheerfully answers questions about the weather.
Nvidia's patent tackles this by building a privacy-aware traffic cop into the AI pipeline. Before your query goes anywhere, the system figures out how sensitive it is. If it's low-stakes, it gets sent to an open domain model — basically a general-purpose AI that can pull from broad knowledge. If it's sensitive, it gets routed to a closed domain model that's more locked down and purpose-specific.
There's a bonus wrinkle: the system can also use the query-and-response pairs as training data, but only when the privacy rules allow it. So your private data doesn't accidentally end up teaching a shared model things it shouldn't know.
How the privacy router splits queries between model pools
The patent describes a dialog system with two distinct model pools. Open domain models handle general-purpose conversation — think broad knowledge retrieval, casual Q&A, or publicly available information. Closed domain models are task-specific and restricted, designed for sensitive or proprietary contexts like internal business data or regulated industries.
At the center is a privacy status determination step. When a query arrives, the system evaluates it — the patent doesn't fully specify the classification mechanism, but the output is a privacy label that drives the routing decision. That label tells the dialog controller (a routing layer sitting above both model pools) which set of models should handle the request, or whether to split the query across both.
The architecture also includes:
- A Natural Language Understanding (NLU) module that parses the incoming query before routing
- A dialog manager that maintains conversation state and policy
- A task-based dialog interface for structured, goal-oriented responses
- A conditional training feedback loop — query/response data is only fed back as training data when the privacy status permits it
The conditional training piece is notable. It means the system is designed to learn and improve over time without violating whatever data governance rules are in place — private queries simply don't contribute to shared model training.
What this means for enterprise LLM deployments
For enterprise AI deployments, data governance is the unglamorous thing that kills or delays every project. If you're a company using an LLM for internal tooling, you need hard guarantees that confidential queries won't contaminate shared training pipelines or get exposed to a model that logs externally. Nvidia's routing approach is a direct answer to that problem — and it maps neatly onto the kinds of compliance requirements you'd see in healthcare, finance, or government contexts.
Nvidia's positioning here is interesting. This isn't just a model patent — it's infrastructure for how LLMs get deployed responsibly at scale. Given that Nvidia sells the hardware and increasingly the software stack that runs enterprise AI, owning the privacy-routing layer too is a logical extension of that strategy.
This is solid, unsexy enterprise plumbing — the kind of patent that won't make headlines but could end up quietly embedded in NeMo or a future Nvidia AI Enterprise offering. The conditional training loop based on privacy status is the genuinely interesting bit: it acknowledges that real-world AI systems need to learn continuously without becoming compliance liabilities. Worth watching if you care about where Nvidia's software stack is headed.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.