Nvidia Patents a Text-Prompt Pipeline That Builds Full 3D Scenes Object by Object
Nvidia has filed a patent describing an AI pipeline that takes a plain text prompt — think "a living room with a couch near a window" — and produces a full 3D scene by generating a layout image, identifying every object in it, and building each one as an individual 3D asset before assembling the whole thing.
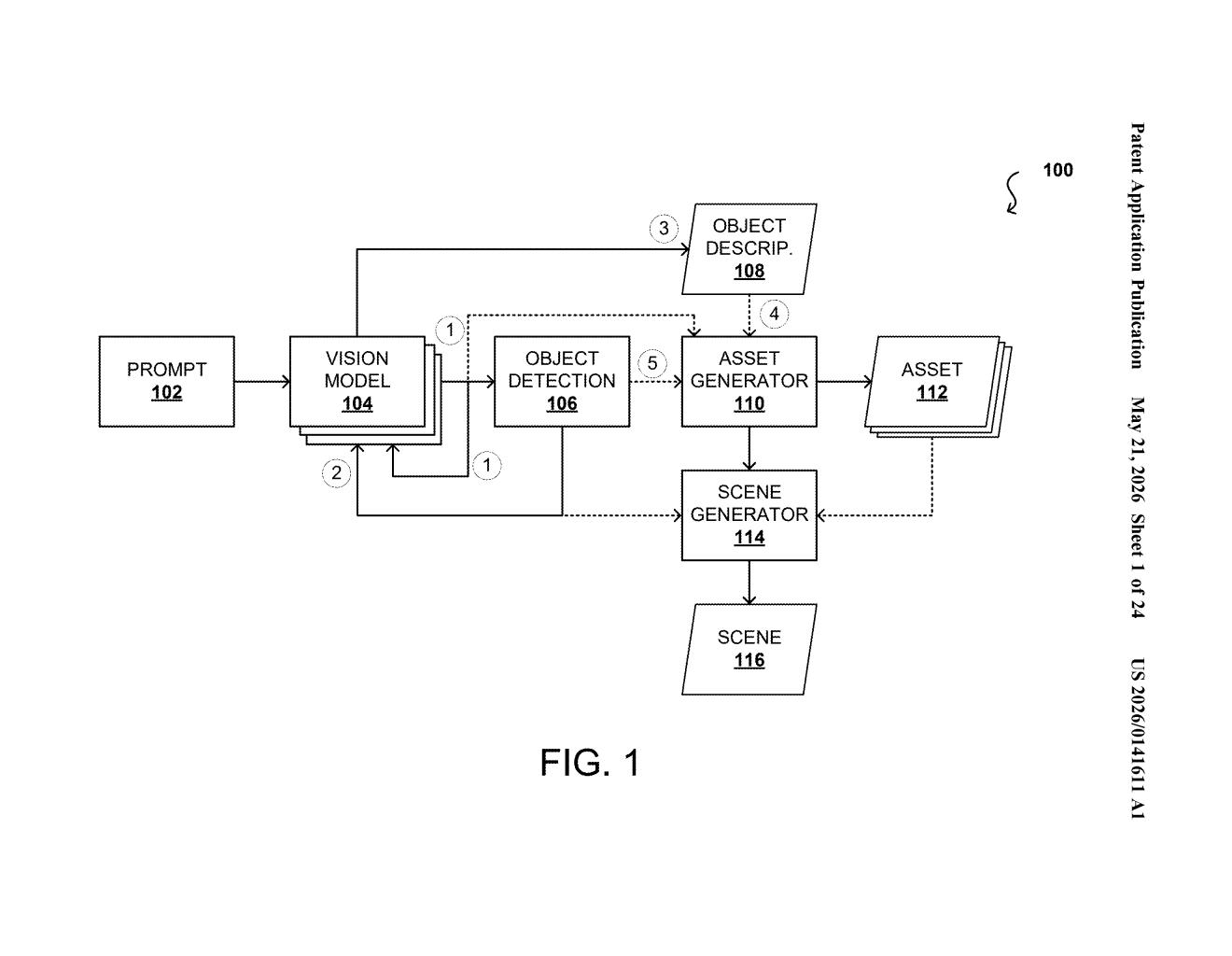
How Nvidia turns a sentence into a 3D world
Imagine typing a description of a scene — "a cluttered kitchen with a wooden table and hanging plants" — and having a computer build you a fully three-dimensional version of it, ready to drop into a game engine or a virtual environment. That's the core idea here.
Nvidia's patent describes a step-by-step AI pipeline that breaks the problem into manageable chunks. First, it turns your text into a 2D layout image — basically a bird's-eye or perspective sketch of the scene. Then it figures out what objects are in that layout and where they sit. Each object gets its own written description, and a separate AI model turns that description into a standalone 3D model.
Finally, all those individual 3D objects get assembled back together using their original location information, recreating the scene your prompt described. The result is a composable 3D scene rather than one undifferentiated blob — which matters a lot if you ever want to move, swap, or re-light individual objects later.
How the pipeline goes from prompt to placed 3D assets
The patent claims a processor-based system with circuits that carry out five distinct steps in sequence.
- Layout generation: Given an input text prompt, the system produces one or more layout images — 2D representations that sketch out the spatial arrangement of a scene.
- Object localization: The system determines the position of each object depicted in the layout image (its location information — where it is in 3D space, how large it is, its orientation).
- Per-object description: For each identified object, the pipeline generates an individual textual description — essentially re-prompting with something like "a worn leather armchair, slightly turned left."
- 3D asset generation: Each object description (and optionally a cropped image of the object from the layout) is fed into a model that produces a standalone 3D representation — geometry, likely with texture.
- Scene assembly: All the individual 3D assets are placed back into the scene using the location data captured earlier, producing a coherent 3D scene that matches the original prompt.
The key architectural insight is decomposition: rather than trying to generate the whole scene at once (which AI models currently do poorly), the system isolates each object, generates it individually, then recomposes. This mirrors how humans might build a 3D scene in software — place the room, add the furniture, position each piece.
What this means for real-time 3D content creation
The bottleneck in 3D content creation today isn't raw compute — it's artist time. Building a single photorealistic 3D asset can take hours; building a full scene takes days. If a pipeline like this can produce layout-aware, individually-editable 3D scenes from text, it collapses that workflow dramatically. That's directly relevant to Nvidia's ambitions in Omniverse, its industrial 3D simulation platform, as well as to game studios and generative AI tooling broadly.
The object-by-object approach also means the output is structurally clean — you end up with discrete, repositionable assets rather than a fused mesh you can't easily edit. For anyone building virtual worlds, sim environments, or AR/VR content, that composability is the feature that makes generated 3D actually usable rather than just visually impressive.
This is one of the more architecturally coherent text-to-3D patents to come out of a major lab — the decompose-then-recompose structure is the right instinct for making generated 3D actually production-ready. Whether Nvidia ships this as a standalone tool or quietly bakes it into Omniverse's scene generation tooling, the underlying approach is sound and worth tracking.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.