Google Patents a Multi-Step Reasoning System for Complex Image-and-Text AI Queries
When you ask an AI a genuinely hard question — one that mixes a photo with a layered follow-up — a single-shot answer often falls flat. Google's new patent describes a system that detects when a query is too complex for a direct response, then automatically splits it into smaller reasoning steps before generating a final answer.
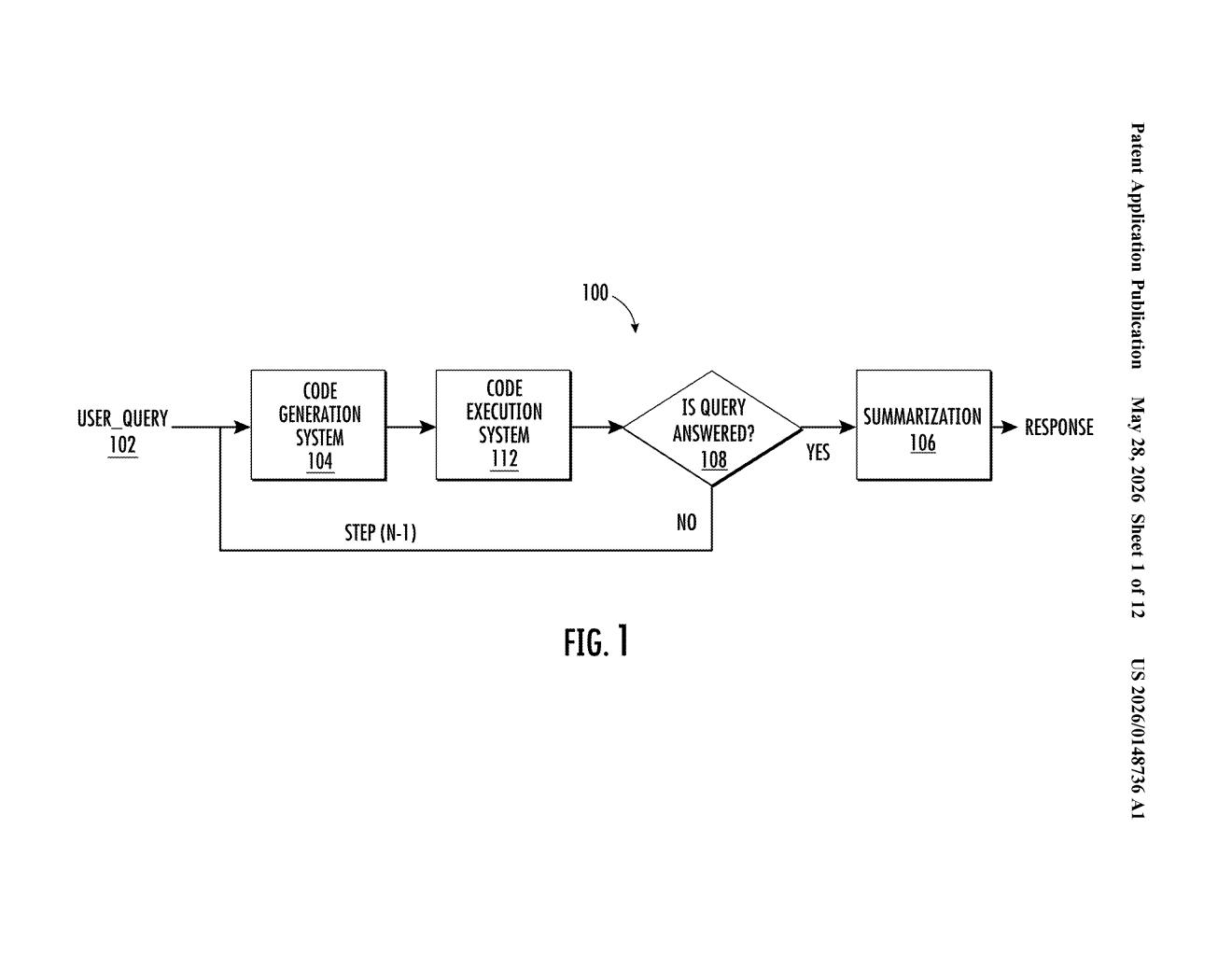
What Google's multi-step query reasoning actually does
Imagine you take a photo of a nutrition label and ask your AI assistant: "Given my daily calorie budget and the fact that I've already had breakfast, how many servings of this can I eat today?" That's not one question — it's several nested ones. A simple AI just tries to answer all of it in one go and often gets it wrong.
Google's patent describes a system that first asks itself: is this query too complex to answer directly? A classification model scores the incoming question — including any image attached — against a complexity threshold. If it clears that bar, the system automatically generates a plan of sub-steps, executes smaller sub-queries, collects intermediate results, and only then assembles a final answer.
Think of it like a chef who reads an entire recipe before touching a pan, rather than winging it one ingredient at a time. The result is a more deliberate, structured path to answering questions that mix visual content with multi-part reasoning.
How Google's system breaks queries into subqueries and intermediate steps
The system has three main moving parts:
- Query classification model: When a multimodal input (text + image) arrives, a lightweight classifier decides whether the query exceeds a complexity threshold. Simple queries skip the pipeline entirely and get a direct response. Complex ones get routed into the multi-step process.
- Step generation and subquery execution: For complex queries, the system generates a plurality of processing steps — essentially a task plan. At least one of those steps is a subquery: a focused, smaller question derived from the original that can be answered independently. Results from each step become intermediate data.
- Synthesis and final response: The intermediate data is assembled into a structured model input, which is then passed to a query response model (the main LLM) to produce the final output. That output is sent back to the user's device for display.
The patent specifically calls out image content as part of the input — meaning the pipeline is designed to handle visual reasoning alongside text, not just text alone. The summarization node visible in the patent's diagram suggests the system may also compress intermediate results before feeding them to the final model, helping keep context windows manageable.
What this means for Google's AI assistant and Search ambitions
This is essentially chain-of-thought reasoning (the technique where AI models reason step by step before answering) baked directly into an infrastructure-level system, rather than left to prompt engineering. By making the routing and decomposition automatic — triggered by a classifier, not a user instruction — Google would be building this capability into the plumbing of its AI products.
For users, this could translate to more reliable answers on the kinds of questions that currently frustrate AI assistants: complex comparisons, multi-condition lookups, or anything that requires synthesizing what's in an image with what's in a follow-up question. Given Google's push to integrate AI deeply into Search and Google Assistant, a scalable approach to handling hard multimodal queries has obvious strategic value.
This patent isn't flashy, but it's doing real architectural work. Automatically detecting query complexity and routing to a multi-step reasoning pipeline — rather than relying on users to prompt correctly or models to spontaneously chain their thoughts — is the kind of system-level thinking that separates research demos from production AI. It's worth watching as a signal of how Google intends to make its AI assistants reliably useful on hard questions, not just easy ones.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.