Microsoft Patents a Traffic-Aware ML System for Predicting Cloud Capacity Shortfalls
Instead of waiting for a server to buckle under load, Microsoft's new patent trains a per-service ML model to spot rising traffic early and pre-emptively add — or trim — cloud resources before an outage can happen.
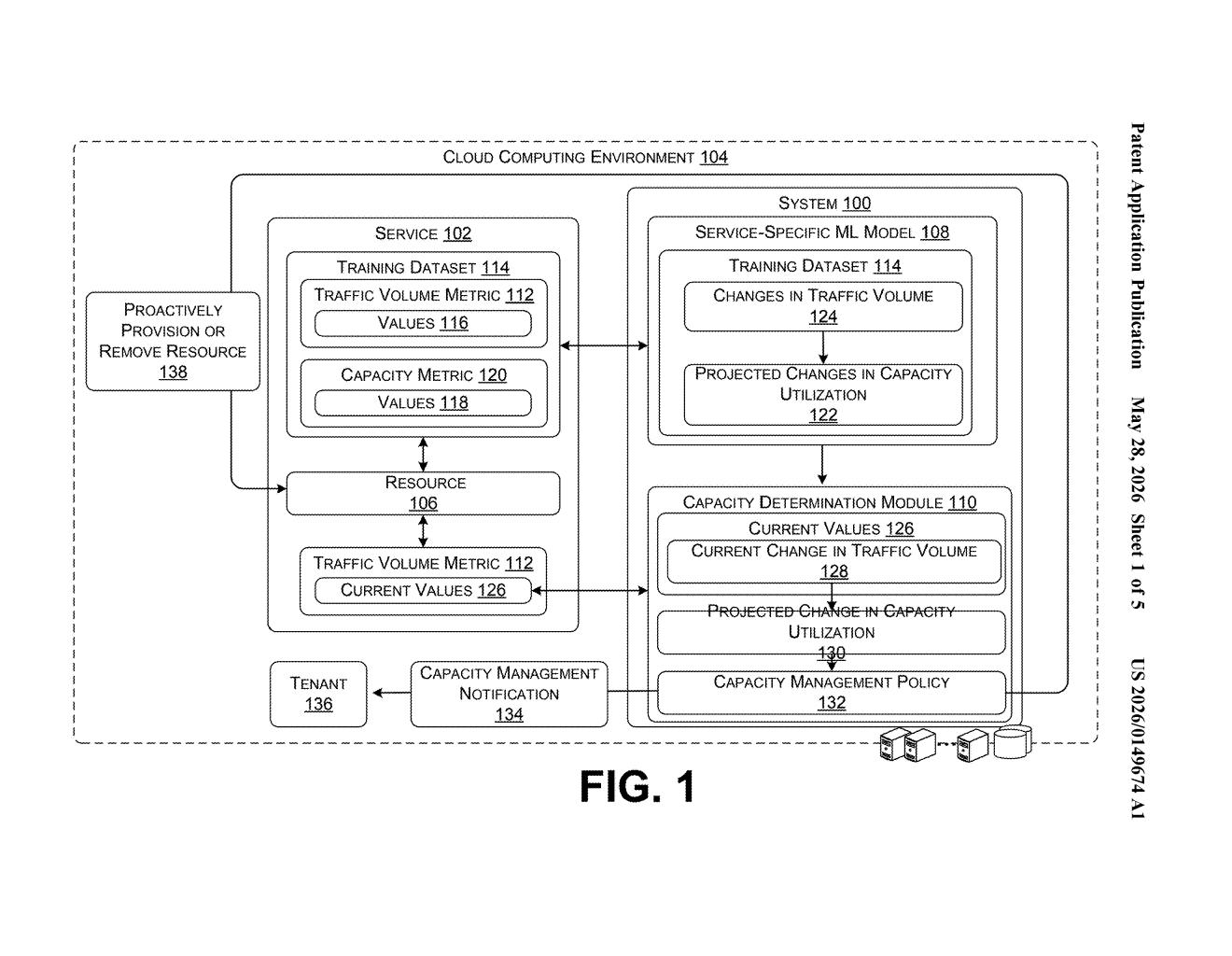
How Microsoft's traffic-signal approach to cloud scaling works
Imagine your favorite app slows to a crawl every Monday morning because the servers weren't ready for the rush. That's an under-provisioning problem, and it's frustratingly common in cloud environments where capacity decisions are often reactive rather than proactive.
Microsoft's patent describes a system that watches traffic volume for a specific cloud service and uses it as an early-warning signal. A dedicated machine learning model — trained on that service's own historical traffic and resource data — learns the relationship between incoming request patterns and how hard the underlying hardware actually works. When traffic starts climbing in a way that suggests the resource is about to hit its limit, the system automatically provisions more capacity. If traffic drops, it can scale back down to avoid wasting money.
The key word here is proactive. Rather than reacting when CPU or memory is already saturated, the model acts on the traffic trend itself, giving the infrastructure time to respond before users ever notice a problem.
How the service-specific ML model projects capacity shifts
The system builds a service-specific ML model — meaning one model per service, trained on that service's own historical data rather than a generic fleet-wide model. The training dataset pairs two streams: traffic volume metrics (how many requests are hitting the service) and capacity utilization metrics (how hard the underlying resource — compute, memory, storage — is actually working). The model learns the causal relationship between the two.
At runtime, the system continuously reads current traffic volume values and feeds them into the trained model to project upcoming changes in capacity utilization. This projection step is the core novelty: it's forward-looking, not just a live dashboard.
The output is compared against a capacity management policy — essentially a set of rules defining acceptable utilization thresholds. If the projection suggests a policy violation is coming (either too little capacity to handle demand, or too much wasted capacity), the system fires off an automated action:
- Provision additional resource units (scale out) to prevent under-provisioning.
- Remove existing resource units (scale in) to prevent over-provisioning and cut costs.
- Optionally, generate a capacity management notification to alert the tenant operating the service.
Because the model is trained per-service, it can capture idiosyncratic traffic patterns — a SaaS app with Monday morning spikes behaves very differently from a batch-processing pipeline, and the system treats them accordingly.
What this means for Azure's auto-scaling reliability
For Azure tenants, this kind of predictive scaling could meaningfully reduce both outages and over-provisioning waste — two problems that currently require either engineering heroics or expensive headroom buffers. The per-service model design is particularly interesting: it suggests Microsoft is betting that generic, fleet-wide autoscalers leave too much performance on the table because they can't learn service-specific traffic shapes.
For end users, the practical upside is fewer slow-load moments during traffic surges. For the businesses running services on Azure, it's the promise of tighter cost control — you don't pay for standby capacity you don't need, and you don't get surprise bills when a campaign drives a traffic spike your infrastructure wasn't ready for.
This is solid, practical infrastructure work — the kind of thing that doesn't make headlines but quietly makes cloud platforms more reliable and cost-efficient. The per-service ML model framing is a meaningful design choice over generic autoscalers, and it fits squarely into the direction Azure's infrastructure team has been heading. It's not a moonshot, but it's the kind of patent that probably ships.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.