Nvidia Patents a User-Configurable Compiler System for Agentic AI Pipelines
Most AI infrastructure tools give you a black box — you plug in your agent pipeline and hope for the best. Nvidia's new patent describes a system where you can actually dial in performance trade-offs and have the compiler reshape your AI agent's execution graph accordingly.
What Nvidia's agentic AI compiler tuning actually does
Imagine you're running a multi-step AI assistant — one that searches the web, summarizes documents, and drafts emails all in sequence. How that pipeline runs under the hood matters enormously: it affects speed, cost, and reliability. Right now, most developers have limited control over how those internal steps are scheduled or optimized.
Nvidia's patent describes a system where users can set configurable parameters — think sliders for latency vs. throughput, or memory vs. speed — and a compiler automatically reshapes the AI agent's internal execution plan to match your priorities. It's a bit like telling your GPS whether you want the fastest route or the most fuel-efficient one, except for AI pipelines.
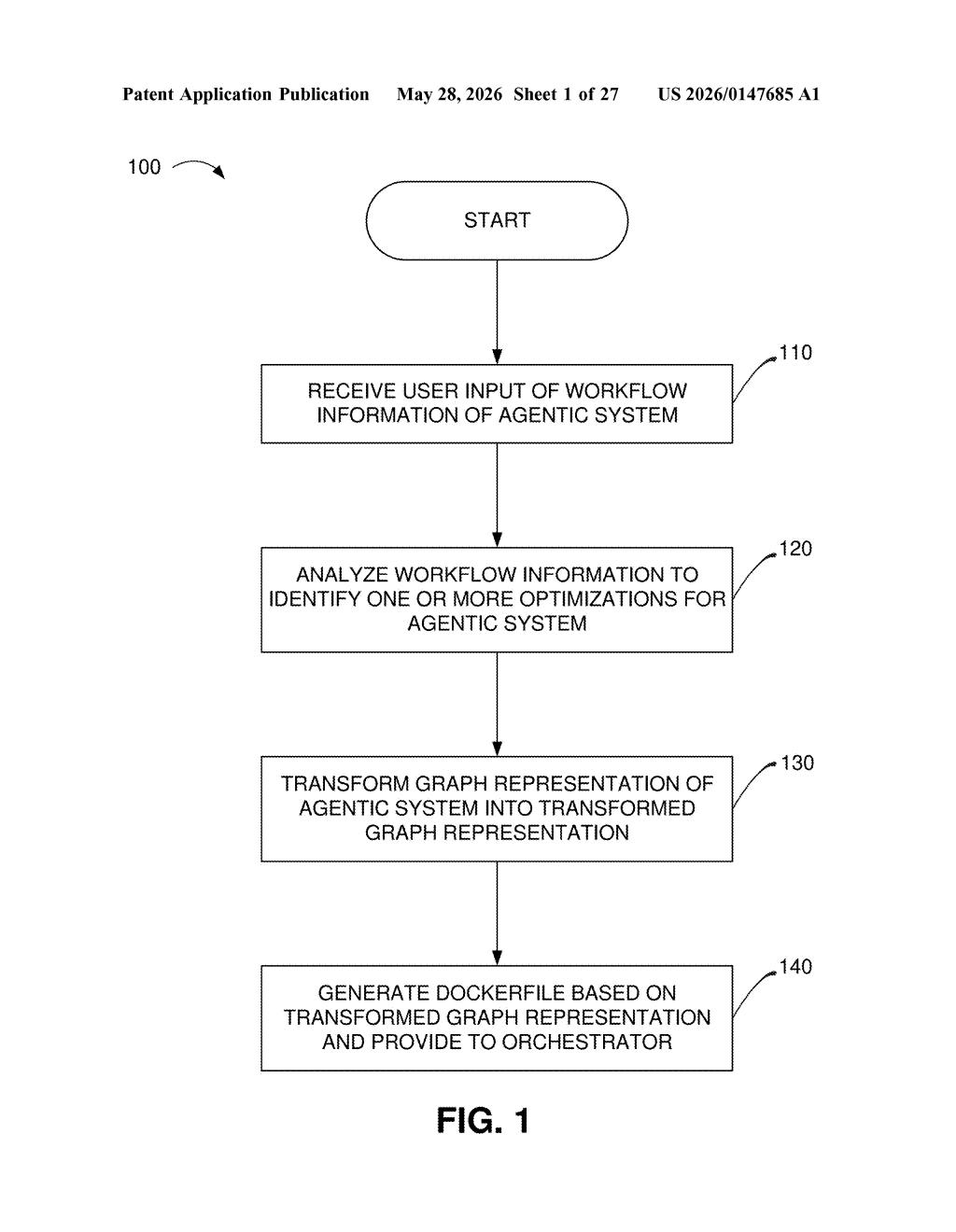
The output is a transformed graph representation of the agent system, which gets packaged into a Dockerfile (a standard container blueprint) and handed off to an orchestrator — the system that actually runs everything. So your tuning preferences flow all the way through to deployment.
How the graph compiler turns parameters into optimized Dockerfiles
The patent centers on a compiler-driven optimization loop for agentic AI systems — AI setups where multiple models or tools work together to complete multi-step tasks.
At the core is a graph representation of the agentic system: a structured map of how tasks, models, and data flows connect. The system analyzes this graph alongside performance metrics (things like latency, memory usage, or throughput) and uses user-configurable parameters to decide how to reshape it. Think of those parameters as compile-time flags — you're telling the optimizer what you care about most before it locks in the execution plan.
The workflow described in the patent looks like this:
- Analyze workflow information to identify candidate optimizations
- Transform the graph representation of the agentic system into an optimized variant
- Generate a Dockerfile (a containerization recipe) based on the transformed graph and deliver it to an orchestrator for execution
The orchestrator — a runtime manager that schedules and runs containerized services — then deploys the tuned agent configuration. The key novelty is that optimization decisions are made at compile time based on explicit user intent, rather than being fixed defaults or purely runtime heuristics.
What this means for enterprise agentic AI deployments
Agentic AI systems are quickly becoming real enterprise infrastructure — think multi-model pipelines for customer support, code generation, or data analysis. Right now, optimizing how those pipelines actually run is mostly a manual, expert-only process. A system that lets users express performance preferences and have the compiler handle the rest could meaningfully lower the bar for deploying well-tuned agentic workloads.
For Nvidia, this fits squarely into its push to own the full agentic AI stack — from GPUs to orchestration software. If your compiler lives in Nvidia's toolchain, your optimization choices get expressed through Nvidia's infrastructure. That's a significant point of platform lock-in, and it's worth watching as agentic AI moves from demos to production deployments.
This is solid infrastructure work, not a flashy research breakthrough — but that's exactly why it's worth paying attention to. Nvidia is quietly building the compilers, runtimes, and orchestration glue that enterprise teams will depend on as agentic AI scales up. Whoever owns the optimization layer owns a lot of leverage over how these systems run.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.