Amazon Patents a Real-Time Streaming Content Moderation System for AI Outputs
Amazon is patenting a way to screen AI-generated text for harmful content on the fly — in chunks, as it streams — rather than waiting until the full response is done. It's essentially a safety net that runs in parallel with the AI itself.
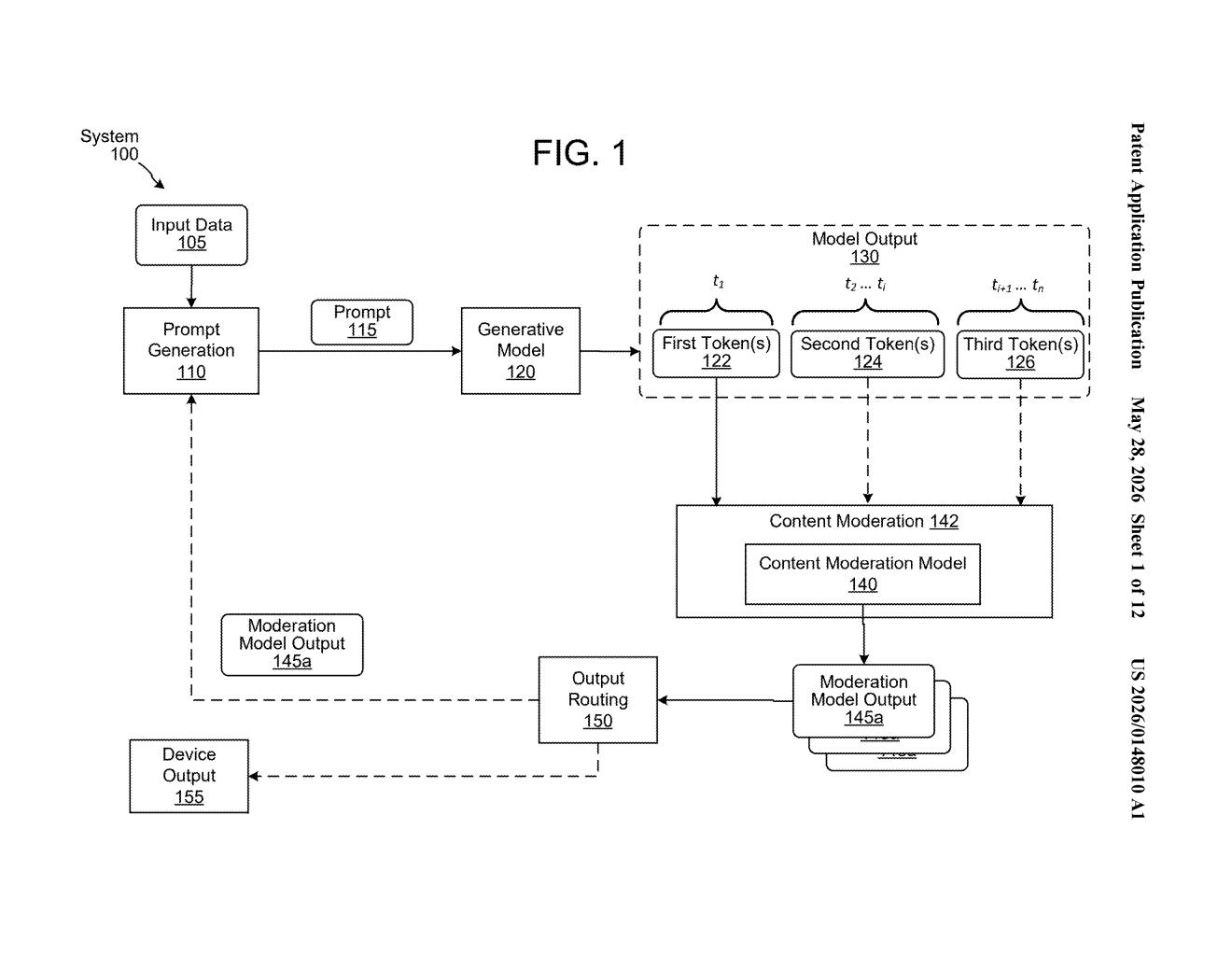
How Amazon's AI checks itself before it wrecks itself
Imagine you ask an AI chatbot a question and it starts typing out an answer word by word, like a human responding in real time. The problem: how do you catch a bad response before the whole thing lands on your screen?
Amazon's approach is to use a second AI — a dedicated content moderation model — that checks the output as it comes out, in overlapping chunks. The first small chunk gets screened immediately. If it's clean, it shows up on your screen. Then a larger chunk gets screened, and so on, with the moderation window growing as the response builds.
The clever part is the variable chunk size: early in a response, you check small amounts to catch problems fast. Later, you can check bigger batches because you've already established context. If anything looks harmful, the system stops and doesn't show it. This way, users get a fast, streaming experience without waiting for a full safety scan to finish first.
How the two-model pipeline scales its token checks
The patent describes a two-model architecture. A first language model (the generative AI doing the actual responding) produces output in a streaming fashion — token by token, like most modern LLMs. A second language model acts as the content moderation layer, running checks on portions of that output as they're produced.
The key mechanism is variable-size processing windows. The system first evaluates a small initial batch of tokens (the "first portion"). If that batch is clean — meaning it doesn't fall into any moderated content category (things like hate speech, explicit content, or dangerous instructions) — those tokens are presented to the user immediately. The system then evaluates a larger second batch, and potentially larger batches after that.
This graduated approach is intentional. Checking tiny chunks early means you can catch a harmful response fast, before much text has been delivered. But checking increasingly larger windows later is computationally smarter — you avoid running a full moderation pass on every single token.
The patent also describes a branching decision tree:
- If a moderated category is detected at any step, output stops.
- If the end-of-output token is reached cleanly, the process completes normally.
- The system dynamically determines how many portions to process next based on prior results.
What this means for AWS AI safety infrastructure
For Amazon, this is core infrastructure for Amazon Bedrock and any AWS-hosted generative AI service. Right now, a common tradeoff in AI safety is latency: full-response moderation means users wait longer, while streaming with no moderation is fast but risky. This patent tries to thread that needle by making the moderation adaptive — small checks up front, bigger checks as the response matures.
For developers building on AWS, this could mean lower-latency guardrails baked directly into the streaming pipeline, rather than bolted on as a post-processing step. The practical implication is that you might be able to ship faster AI experiences without sacrificing the safety reviews that enterprise customers — and regulators — increasingly require.
This is unglamorous but genuinely useful infrastructure work. The variable-window trick is a real engineering insight: most content moderation either blocks the whole stream or adds noticeable lag, and Amazon is trying to solve both problems at once. It won't make headlines, but it's the kind of plumbing that makes or breaks a production AI platform.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.