Nvidia Patents a Token-Mapping Table That Lets LLMs Call APIs Without Errors
When an AI agent tries to call an external tool, the gap between 'what the model outputs' and 'what the API actually accepts' is where everything breaks. Nvidia's latest patent is essentially a translation layer designed to close that gap at the hardware level.
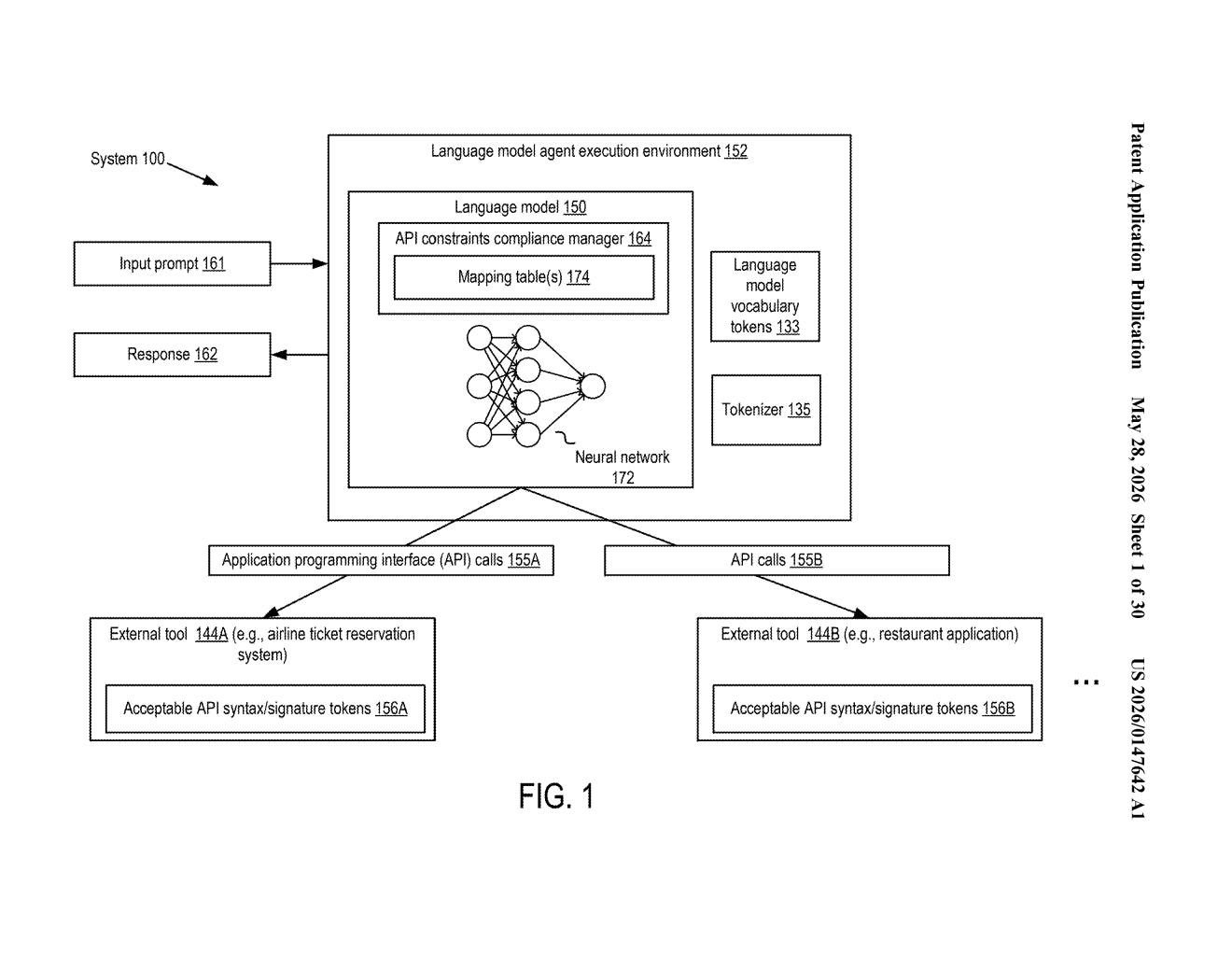
What Nvidia's LLM-to-API token mapper actually does
Imagine you ask an AI assistant to book you a table at a restaurant. Under the hood, the AI has to call a restaurant app's API — a structured interface with very specific rules about what words and formats it will accept. If the AI generates even slightly wrong syntax, the call fails and nothing happens.
Nvidia's patent describes a mapping table that sits between the neural network's outputs and the API it needs to call. Instead of the model having to guess perfectly at valid API syntax every time, the table translates the model's raw output tokens into the exact tokens the API expects. Think of it like a real-time language interpreter making sure the AI always speaks the API's dialect.
This is infrastructure-level plumbing — not a flashy new model — but it directly addresses one of the most frustrating failure modes in AI agent systems today: models that almost get the function call right but not quite.
How the mapping table translates neural tokens to API syntax
At the core of this patent is a hardware circuit (implemented in a processor) that manages one or more mapping tables. These tables take tokens — the small units of text or code that neural networks generate — and translate them into tokens that conform to a target API's expected syntax and signature.
The patent describes a full execution environment for language model agents, including:
- A tokenizer that converts model outputs into discrete tokens
- A neural network generating the raw API call intent
- A mapping table layer that re-encodes those tokens into API-compliant equivalents
- An external tool interface (the patent uses a restaurant application as an example)
The key insight is that LLM vocabularies and API token signatures don't naturally align. An LLM might produce a close-but-wrong function name or argument format. The mapping table acts as a constrained decoding step — essentially forcing or correcting the model's output to match valid API syntax before the call is ever dispatched.
Doing this at the hardware/processor circuit level rather than in software suggests Nvidia is thinking about this as a low-latency, high-throughput primitive for agent inference workloads — not just a software patch.
What this means for reliable AI agent deployments
AI agents that call external tools are only as reliable as their ability to generate syntactically correct API calls. Right now, a lot of that reliability depends on prompt engineering, fine-tuning, or runtime retries — all of which are expensive and brittle. A hardware-level mapping table built into the inference processor would make every API call from an LLM agent structurally valid by definition, eliminating an entire class of agent failures.
For Nvidia, this fits neatly into its broader push to own the full AI inference stack — from the GPU silicon through the software runtime. If your inference chip natively handles token-to-API translation, you're not just selling compute anymore; you're selling a reliability guarantee for agentic AI workloads. That's a meaningful moat.
This is a narrow but genuinely useful patent that targets a real, well-documented pain point in LLM agent deployments. It's not about making models more capable — it's about making their outputs more predictably correct when interacting with structured systems. If Nvidia ships this as part of its inference stack, expect it to become a quiet default that developers take for granted within a few years.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.