Nvidia Patents AI Speech Recognition That Timestamps Every Single Word
Most speech recognition just gives you text. Nvidia's new patent produces text and a precise timestamp for each word — simultaneously — by treating time markers as a kind of vocabulary the model learns to speak.
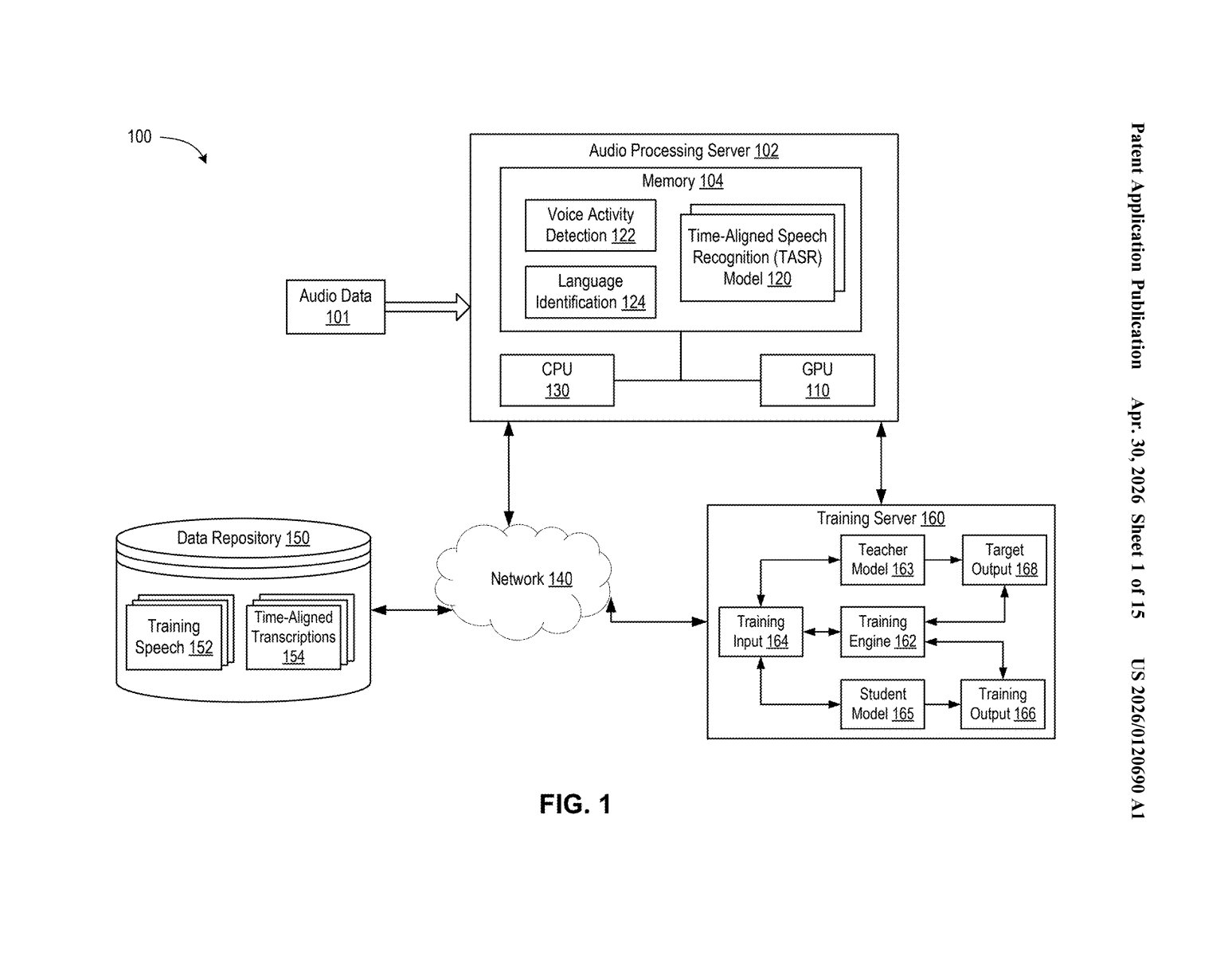
What Nvidia's word-level speech timestamping actually does
Imagine watching a two-hour meeting recording and wanting to jump directly to the moment someone said a specific phrase. That's easy if your transcript knows exactly when each word was spoken — but most AI transcription tools don't track that with word-level precision.
Nvidia's patent describes a speech recognition system that doesn't just convert audio to text — it also pins every transcribed word to the exact moment it appeared in the audio. The model learns to output both regular words and special timestamp markers as part of the same recognition process, rather than adding timing as a clumsy afterthought.
The result is a "timed transcription" where you get your words and their positions in time, baked together from the start. That's genuinely useful for anything that needs to sync text with audio — subtitles, meeting search, voice-controlled editing, or AI agents that need to know when something was said, not just what.
How the ASR model scores words and timestamps in parallel
The core idea is that the ASR model processes chunks of audio — called audio frames — and for each unit of transcription it's working on, it produces two parallel sets of probability scores simultaneously.
- First set (vocabulary tokens): The probability that this chunk of speech corresponds to a particular word or subword in the model's vocabulary — standard speech-to-text stuff.
- Second set (timestamp tokens): The probability that this chunk corresponds to a special time-marker token, which maps back to a specific position in the audio timeline.
The model picks whichever option scores highest — a word or a timestamp — at each step. Because timestamp tokens are mapped directly to audio frames, the system knows not just what was said but when in the recording it was said, down to the frame level.
The clever part is that timestamps aren't computed as a separate post-processing step — they're baked into the same decoding pass that produces the transcript itself. This is similar in spirit to how modern language models learn to output structured data (like JSON) alongside natural language — the model just learns that time markers are part of the "vocabulary" it can emit.
What this means for real-time transcription and AI pipelines
Word-level timestamps are already a selling point for premium transcription services like Whisper, Deepgram, and AssemblyAI — but they typically require an extra alignment step after transcription. Nvidia's approach integrates timing into the core recognition pass, which should make it faster and potentially more accurate since the timing information is grounded in the same model that's doing the transcribing.
For Nvidia, this fits squarely into its push to own the AI inference stack — if you're running speech pipelines on Nvidia hardware and software, having a tightly integrated, GPU-optimized ASR system with built-in timestamping is a meaningful differentiator. Expect to see this kind of capability show up in NeMo, Nvidia's open-source conversational AI toolkit, or in its enterprise speech APIs.
This is genuinely solid engineering, not a flashy moonshot. Collapsing word transcription and timestamp prediction into a single decoding pass is the kind of quiet optimization that actually ships in production systems. It's the speech-AI equivalent of replacing two database queries with one — less glamorous than a new model architecture, but meaningfully better in the real world.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.