Microsoft Patents a Way to Stop AI Hardware from Running on the Wrong Settings
Every time you run an AI model on a GPU or custom accelerator, someone had to figure out the exact configuration settings that make that hardware go fast — a tedious, expensive process called kernel tuning. Microsoft's new patent wants to automate that search at scale.
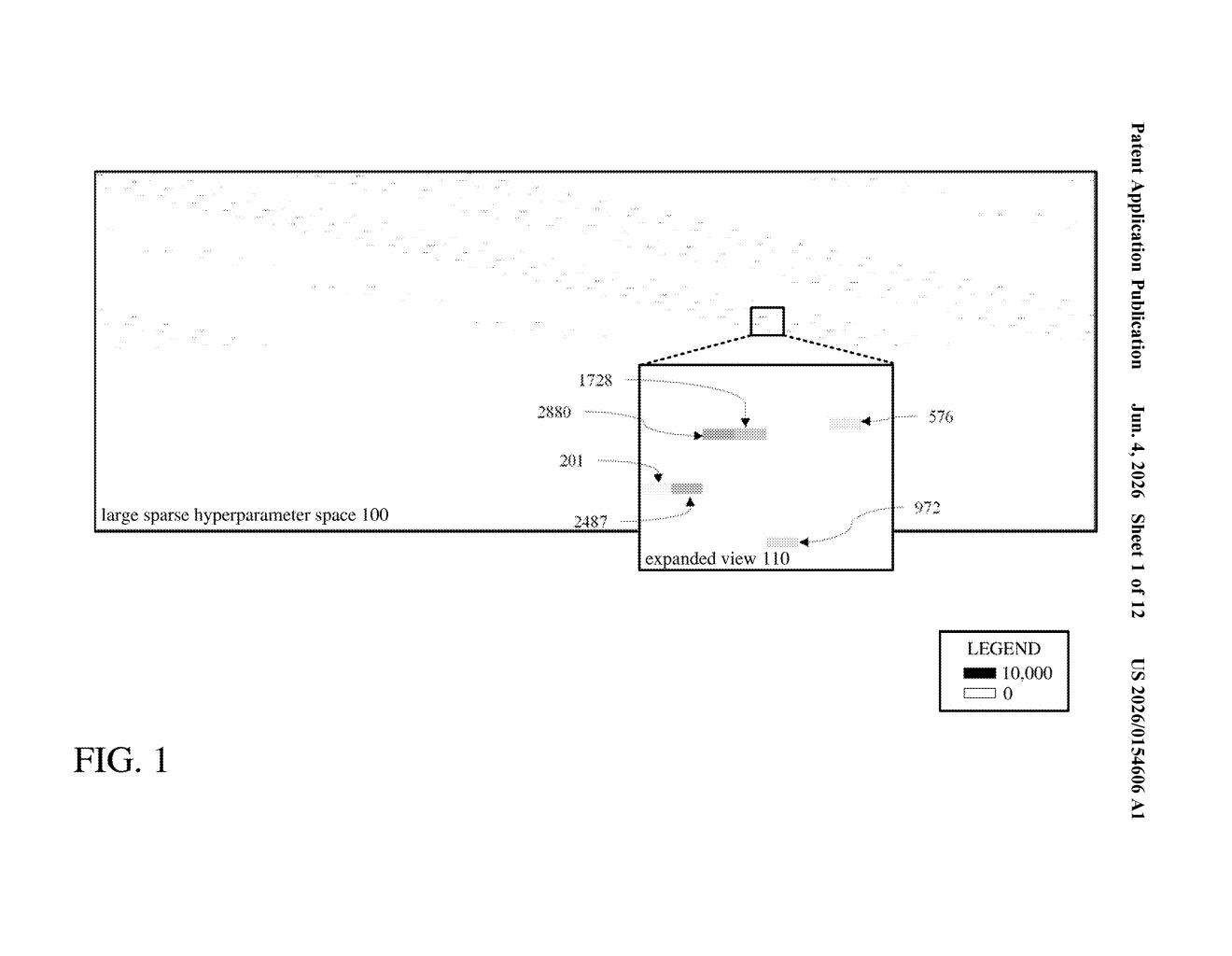
What Microsoft's kernel autotuner actually does
Imagine you're trying to find the perfect combination of settings on a complicated piece of audio equipment — hundreds of knobs, each with dozens of positions. Testing every possible combination would take forever, but guessing randomly might miss the sweet spot. Microsoft's autotuner solves exactly this kind of problem, but for AI hardware.
When AI models run on accelerator chips (like GPUs or custom AI processors), the underlying code — called a kernel — has dozens of configuration knobs called hyperparameters. The right combination can make the chip run dramatically faster; the wrong one wastes time and energy. Finding the best combo in a space of millions of possibilities is genuinely hard.
This patent describes a system that splits that enormous search space into smaller batches, farms them out to worker processes running in parallel, and uses an intelligent optimization technique to avoid testing every single combination. Each worker finds the best settings within its chunk, and a main process picks the overall winner from among those local champions.
How the batch-and-optimize search loop works
The system has a two-level architecture: a main process that divides the full hyperparameter space into batches, and multiple worker processes that each tackle one batch independently.
Inside each worker, the search happens in two phases:
- Initial sampling: a small random (or structured) set of hyperparameter combinations is evaluated — think of it as taking a handful of measurements to get a feel for the landscape.
- Optimization-guided selection: an optimization tool (the patent points to techniques like Bayesian optimization — a method that builds a probabilistic model of which settings are likely to be good, then picks the most promising untested ones) chooses a second round of combinations to evaluate based on what the first round revealed.
- Local winner selection: the worker picks the best-performing combination from both rounds combined.
The main process collects each batch's local winner and runs a final comparison to crown the overall-leading hyperparameter combination. The number of combinations tested in each phase is itself configurable — so the tuner can be dialed for speed vs. thoroughness depending on available compute budget.
The key insight is that the hyperparameter space is described as sparse — meaning most combinations are invalid or unpromising — which makes exhaustive search wasteful. The batch-and-optimize structure avoids that waste.
What this means for AI hardware performance tuning
For companies running large-scale AI inference or training, kernel tuning is a real cost center. Poorly tuned kernels can cut accelerator throughput by 30–50% compared to a well-tuned one — that translates directly into more chips needed and higher cloud bills. An automated, parallelized tuner that intelligently skips dead-end configurations could meaningfully reduce that overhead.
This is also relevant as custom AI accelerators (Microsoft's Maia chips, for example) proliferate. Each new hardware generation means a fresh tuning problem — making a robust, automated tuner more valuable over time, not less. If you're deploying models on Azure or Microsoft's internal infrastructure, this kind of tooling quietly determines how much of the hardware's potential you actually get to use.
This is unglamorous but genuinely useful infrastructure work — the kind of thing that doesn't ship as a product feature but quietly makes every AI workload on Microsoft's hardware run better. The parallel batch approach combined with guided optimization is a sensible engineering solution to a real problem. It's not a research breakthrough, but the teams maintaining Azure's AI accelerator stack will care about it.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.