Nvidia Patents a Way to Run an AI's Math in Fewer Steps
Every time an AI model crunches through its math, it fires off dozens of individual operations one after another. Nvidia's new patent describes a single API call that can kick off a whole chain of those operations at once — less overhead, cleaner code.
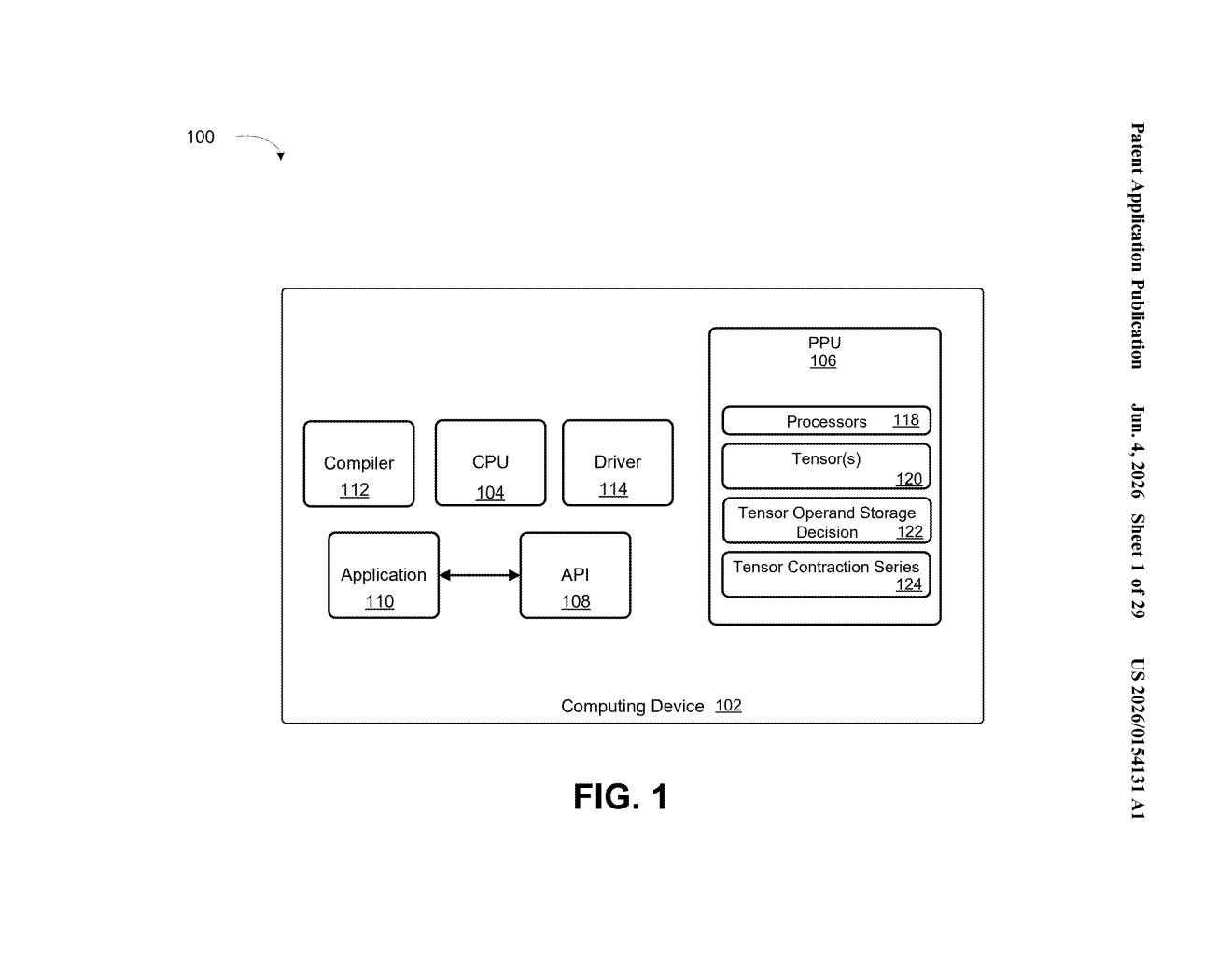
What Nvidia's chained tensor API actually does for AI
Imagine you're cooking a complex meal. Instead of calling the kitchen every time you need one ingredient chopped, you hand a single prep list to the chef and walk away. That's roughly what this patent is doing for the math that powers AI.
Right now, AI frameworks typically issue individual calls for each mathematical operation they need the GPU to run. Nvidia's patent describes an API (a programming interface, essentially a standardized way for software to ask hardware to do something) that lets you bundle multiple of these operations — specifically a class called tensor contractions — into a single request.
Tensor contractions are the core arithmetic behind neural networks: multiplying and summing multi-dimensional arrays of numbers. Being able to chain several of them through one API call means less back-and-forth between software and hardware, which can translate to faster, more efficient AI computation.
How the API batches tensor contractions under one call
The patent describes a processor with circuits designed to execute an API capable of triggering two or more tensor contractions in sequence based on input parameters passed to that single API call.
Tensor contractions (think of them as generalized matrix multiplications — operations that take two multi-dimensional arrays and produce a new one by summing over shared dimensions) are the workhorses of deep learning. Normally, each contraction is its own discrete operation call, which introduces scheduling and dispatch overhead each time.
By accepting multiple contractions as parameters of one API invocation, the system can:
- Reduce the number of round-trips between the calling software and the GPU's execution engine
- Allow the underlying hardware or driver to fuse or reorder the operations for better memory locality and throughput
- Simplify the code that AI framework authors have to write when expressing complex multi-step tensor math
The claim is deliberately broad — it covers any processor with circuits that implement this kind of batched-contraction API, which means it could apply to GPU kernels, dedicated AI accelerators, or future tensor processing units.
What this means for GPU efficiency in AI model training
For AI researchers and framework developers, the practical win here is reduced dispatch overhead. Every time software asks a GPU to do something, there's a small but real cost in latency and CPU cycles. When a model has hundreds of layers each firing multiple tensor ops, those costs stack up. A single API that handles a chain of contractions in one shot is a clean way to attack that problem.
More strategically, this kind of API design gives Nvidia's compiler and driver stack more visibility into what the application intends to do next — which opens the door to smarter scheduling and kernel fusion. If CUDA or a successor runtime knows you need three contractions in a row, it can plan memory placement and execution overlap in ways that are simply impossible when each call arrives separately.
This is unglamorous but genuinely useful infrastructure work. Batching tensor operations through a unified API is the kind of optimization that quietly shaves milliseconds off training runs at scale — and at Nvidia's customer base, milliseconds times millions of GPU-hours add up fast. It's not a flashy AI demo, but it's exactly the plumbing that keeps Nvidia's CUDA ecosystem ahead of alternatives.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.