Samsung Patents a System That Auto-Converts CPU Instructions for Parallel Processing
Most software is written for one kind of processor and runs as-is, even if a faster execution path exists. Samsung's new patent describes a runtime system that automatically detects when scalar CPU instructions can be swapped out for vector equivalents — without the developer doing a thing.
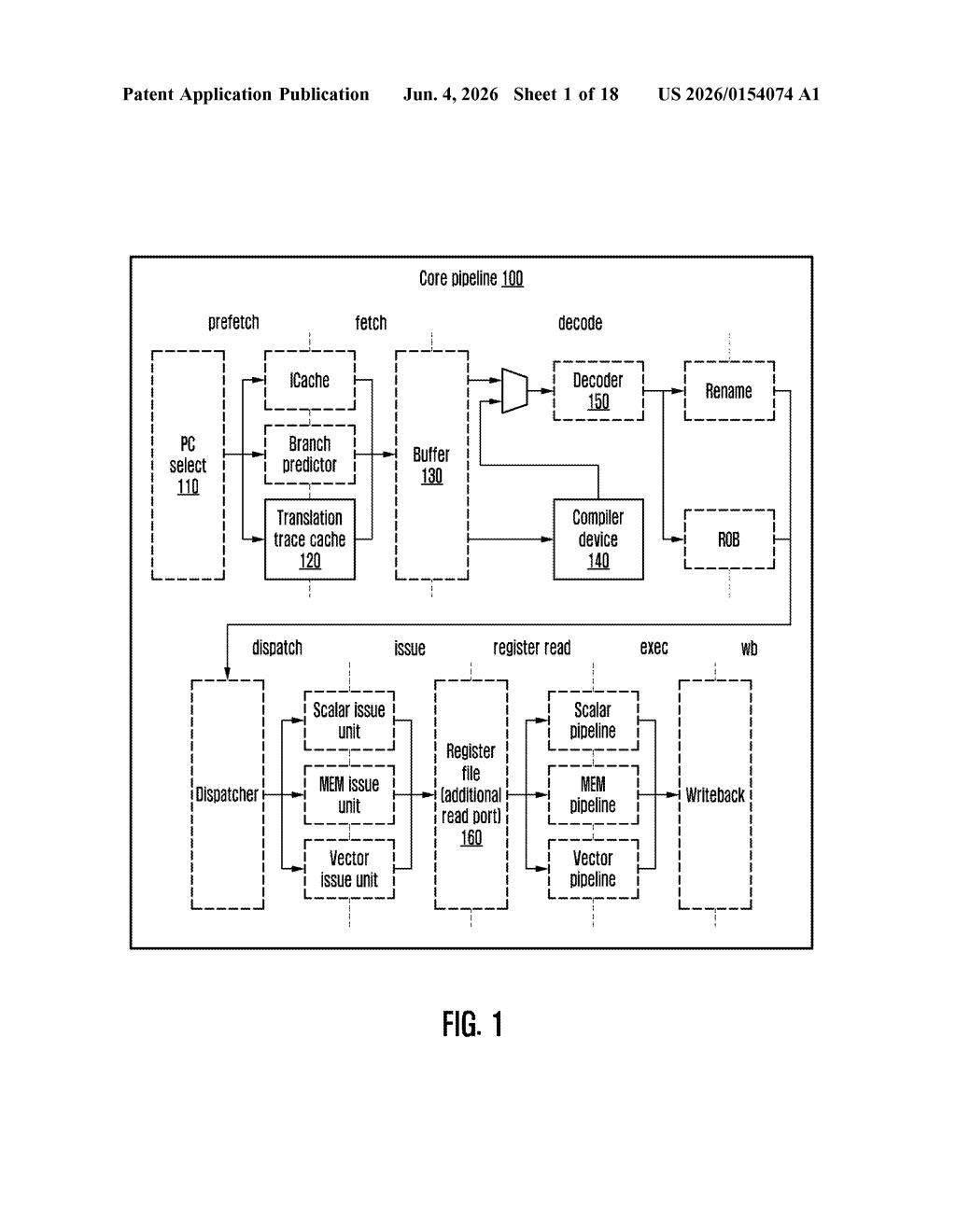
What Samsung's instruction-rewriting trick actually does
Imagine your GPS app was written assuming you'd walk everywhere, but you're actually in a car. It'd still work, just slower than it could be. Something similar happens with software written for one type of processor running on a chip that could handle tasks much more efficiently.
Traditionally, a CPU processes instructions one at a time (scalar). But modern chips — especially Samsung's own Exynos lineup — also have vector units that can crunch multiple pieces of data simultaneously. The catch is that older or cross-compiled software doesn't always know to use them.
Samsung's patent describes a layer that intercepts the instruction stream at runtime, analyzes metadata attached to each instruction, and rewrites eligible scalar instructions into vector instructions on the fly. You don't recompile anything — the hardware or firmware layer handles the translation automatically.
How the translator detects and rewrites scalar to vector code
The system works in a binary translation layer — essentially a runtime interpreter that sits between incoming code and the processor's actual execution units.
When an instruction stream arrives, each instruction carries attached instruction-information (metadata about its type, dependencies, and data patterns). The translator uses this metadata to decide whether a block of scalar instructions can be safely replaced with vector instructions from a different ISA (Instruction Set Architecture — the vocabulary a CPU understands).
- Receive and decode: The system ingests the binary instruction stream along with its metadata.
- Determine translatability: It checks whether instructions meet the criteria for vectorization — for example, whether they operate on independent data lanes that can run in parallel.
- Translate: Eligible scalar instructions are replaced with functionally equivalent vector instructions from a vector-specific ISA, meaning the output is identical but runs faster on hardware with vector execution units.
The key innovation here is the use of per-instruction metadata to drive translation decisions, rather than relying solely on static analysis of the code itself. This makes the process more dynamic and potentially more accurate at runtime.
What this means for cross-architecture software performance
Binary translation is a well-established technique — it's how Apple's Rosetta 2 lets x86 apps run on Apple Silicon, and how Android's ART runtime optimizes apps. What Samsung is adding is a scalar-to-vector dimension: not just translating between CPU architectures, but upgrading the parallelism level of code on the fly. That's a meaningful step toward squeezing more performance out of existing software without requiring developers to rewrite anything.
For Samsung, this could have implications across its chip portfolio — from Exynos mobile processors to its custom server and AI silicon. Software that wasn't optimized for vector execution could automatically benefit from it, which matters a lot in an era where Samsung is competing hard on both mobile and data-center silicon efficiency.
This is solid, pragmatic chip engineering — not flashy, but the kind of infrastructure work that compounds over time. Binary translation layers that auto-vectorize code could quietly close performance gaps on Samsung's own silicon without waiting for the software ecosystem to catch up. It's a smart hedge against the eternal problem of legacy codebases.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.