Nvidia Patents an API That Lets GPUs Load Only Part of a Matrix at a Time
Matrix multiplication is the backbone of almost every AI model — and Nvidia just filed a patent for a new programming interface that lets a processor skip loading the parts of a matrix it doesn't need yet.
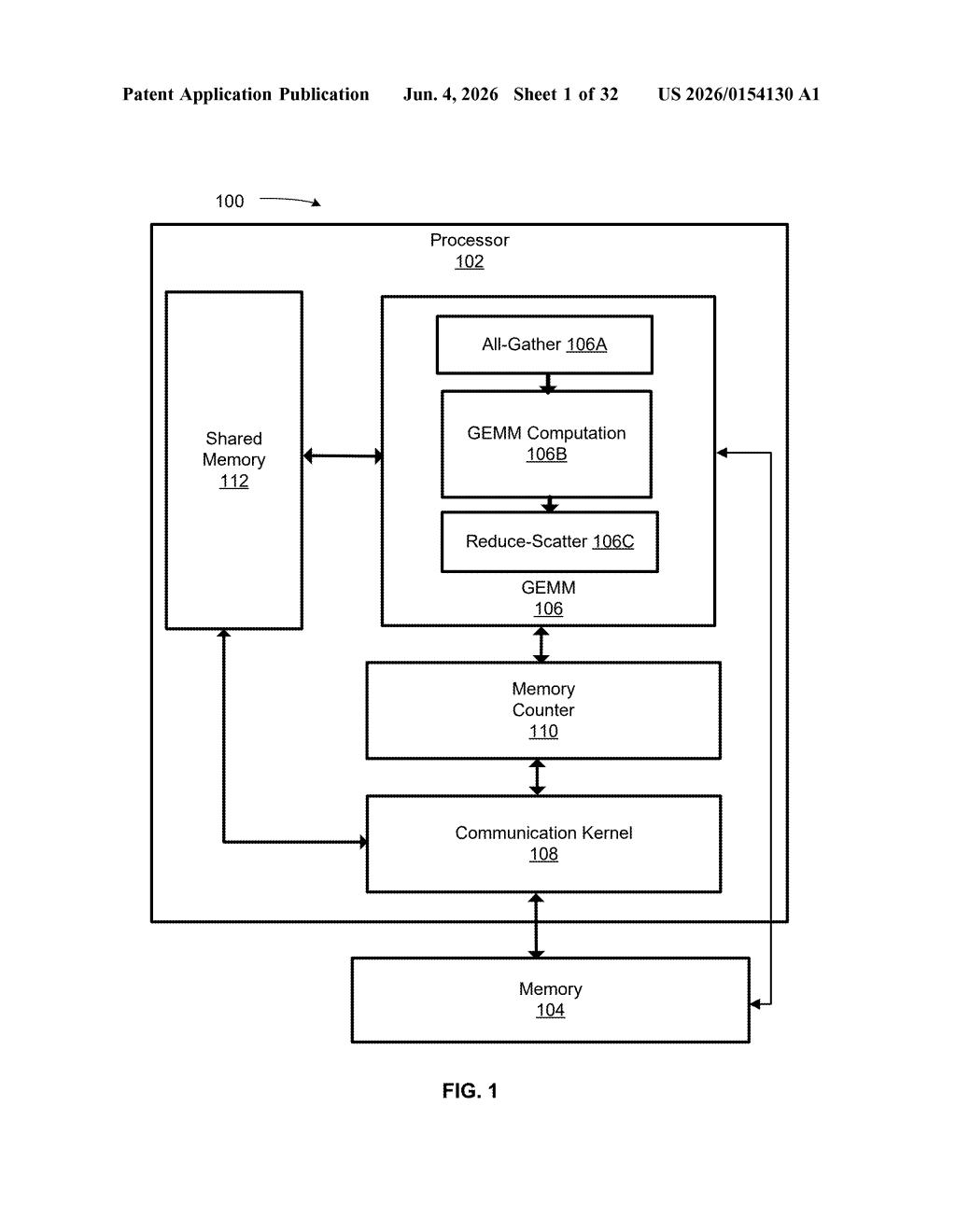
What Nvidia's partial matrix loading API actually does
Imagine you're baking a huge batch of cookies, but your counter only has room for a few ingredients at a time. Instead of hauling out every bag and bottle at the start, you grab only what you need for the next step. Nvidia's patent describes a similar idea for the math that powers AI.
Almost everything a GPU does in AI — training a neural network, running inference, rendering — comes down to matrix multiplication: multiplying giant tables of numbers together. These matrices can be enormous, and loading all of them into fast memory at once is expensive and slow.
This patent describes an API (a software interface programmers use to give instructions to hardware) that tells a processor which pieces of a matrix operation need to be loaded right now versus later. The idea is to avoid wasting fast, scarce memory on data the chip isn't ready to use yet.
How the API signals which operands to partially load
At the core of modern AI hardware is the GEMM operation — General Matrix Multiply — a standardized way of describing the multiply-accumulate math that neural networks run billions of times per second. GEMMs have multiple operands (the input matrices, typically labeled A, B, and C/D), and all of them need to be in memory for the operation to proceed.
This patent covers an API that explicitly signals whether one or more of those operands should be partially loaded rather than fully staged in memory before compute begins. That's a fine-grained control layer sitting between software (like a CUDA kernel or a deep learning framework) and the hardware scheduler.
The practical implication is a form of lazy loading for matrix data: instead of pre-staging full matrices in registers or shared memory — which can be thousands of elements wide — the processor can begin work on the parts it has while the rest arrive. This maps naturally onto techniques like:
- Pipelining — overlapping data fetch with computation
- Tiling — breaking matrices into smaller chunks processed sequentially
- Streaming workloads — where input data arrives continuously rather than all at once
The API itself is what's being patented here: the programmable interface that makes this partial-load behavior something a developer or compiler can explicitly request and control.
What this means for GPU memory and AI workload efficiency
For AI training and inference at scale, memory bandwidth is often the real bottleneck — not raw compute. Any mechanism that reduces how much data has to be resident in fast memory at once — even temporarily — can translate to meaningfully better throughput on large models. This kind of API gives compiler writers and framework developers (think PyTorch, TensorRT, JAX) a new lever to pull when optimizing how matrix ops are scheduled on Nvidia hardware.
It's also a sign that Nvidia is continuing to push programmability deeper into the hardware stack. Rather than leaving memory-staging decisions entirely to microarchitecture, this exposes that control to software — which means smarter compilers can make smarter tradeoffs at runtime.
This is unglamorous but genuinely useful infrastructure work. The headline story in AI hardware is always about FLOPS and new architectures, but the real optimization surface is increasingly in how data moves — and an API that gives programmers explicit control over partial operand loading is exactly the kind of low-level knob that differentiates Nvidia's software ecosystem from competitors. Don't expect a press release, but do expect this to quietly show up in a future CUDA toolkit.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.