Salesforce Patents a Cache That Feeds Old AI Answers Back Into New Prompts
Salesforce has figured out a way to get twice the mileage out of every answer an AI gives — either serving it directly from cache or recycling it as a teaching example for the next similar question.
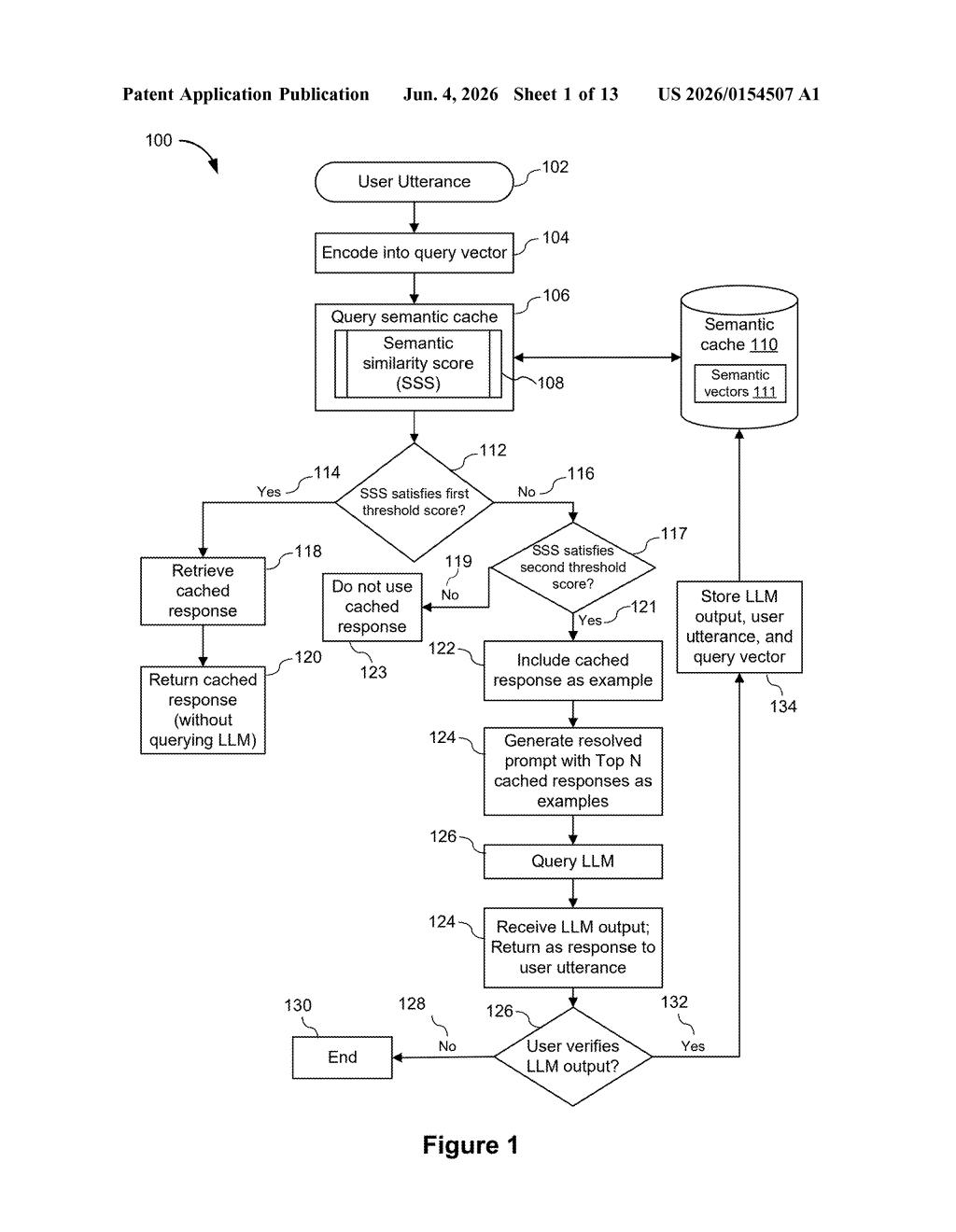
What Salesforce's semantic answer cache actually does
Imagine your company's AI assistant gets asked the same sales question dozens of times a day. Right now, most systems just forward every single one to the AI model — which is slow and expensive. Salesforce's patent describes a smarter shortcut.
When a new question comes in, the system checks a "semantic cache" — basically a memory bank of past questions and their verified answers. If the new question is close enough to a stored one, it just returns the old answer immediately, no AI needed. That's the fast path.
Here's the clever part: if the question is somewhat similar but not close enough to reuse directly, the system doesn't give up on the cache — it pulls the old answer out and hands it to the AI as a worked example. The AI sees "here's a similar question and what a good answer looked like," then crafts a fresh response. You get speed and consistency without starting from zero every time.
How the similarity score decides which path a query takes
The system works as a two-stage routing layer that sits in front of a large language model.
First, every incoming user query is encoded into a vector — a list of numbers that represents the query's meaning in high-dimensional space (think of it as a fingerprint for the question's intent, not just its words). That vector is compared against a semantic cache: a stored library of vectors from previous queries, each paired with a verified response.
For each stored vector, the system calculates a semantic similarity score (a measure of how close two meaning-fingerprints are — cosine similarity is the standard approach). Then the routing decision happens:
- High similarity (above threshold): The cached response is returned directly. The LLM is never called.
- Moderate similarity (below threshold but still relevant): The cached response is retrieved and injected into a few-shot prompt — a prompt format where you show the model example question-answer pairs before asking your real question. The LLM uses the cached answer as a reference example and generates a tailored response.
The phrase "few-shot prompting" refers to a well-established technique where giving the model 1–5 examples dramatically improves output quality and consistency, especially in domain-specific contexts like CRM or customer support. Salesforce is essentially automating the curation of those examples from real, previously-verified traffic.
What this means for enterprise LLM costs and consistency
For enterprise software — Salesforce's core market — LLM API costs and response latency are real operational concerns at scale. A semantic cache that bypasses the model entirely for near-duplicate queries can cut inference costs meaningfully. The few-shot fallback path is the more interesting angle: instead of degrading gracefully to a cold LLM call, the system actively improves the LLM's output by seeding it with domain-relevant context from real past usage. Over time, the cache becomes a self-reinforcing quality layer.
For you as an end user of a Salesforce product, this could mean faster, more consistent AI responses that stay on-brand for your company's specific terminology and use cases — without someone manually curating prompt templates.
This is pragmatic infrastructure work, not a headline AI research breakthrough — but it's the kind of thing that actually ships and saves money. The two-threshold routing architecture is genuinely clever: most semantic caching systems only do the direct-hit case, and Salesforce's contribution is the "near miss becomes a training example" path. Worth tracking for anyone building enterprise AI tooling.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.