Adobe Patents a Pipeline That Builds 3D Models From One Photo
Take one photo of an object, and Adobe's patented system reconstructs a full 3D model of it — no turntable, no depth camera, no multi-angle shoot required.
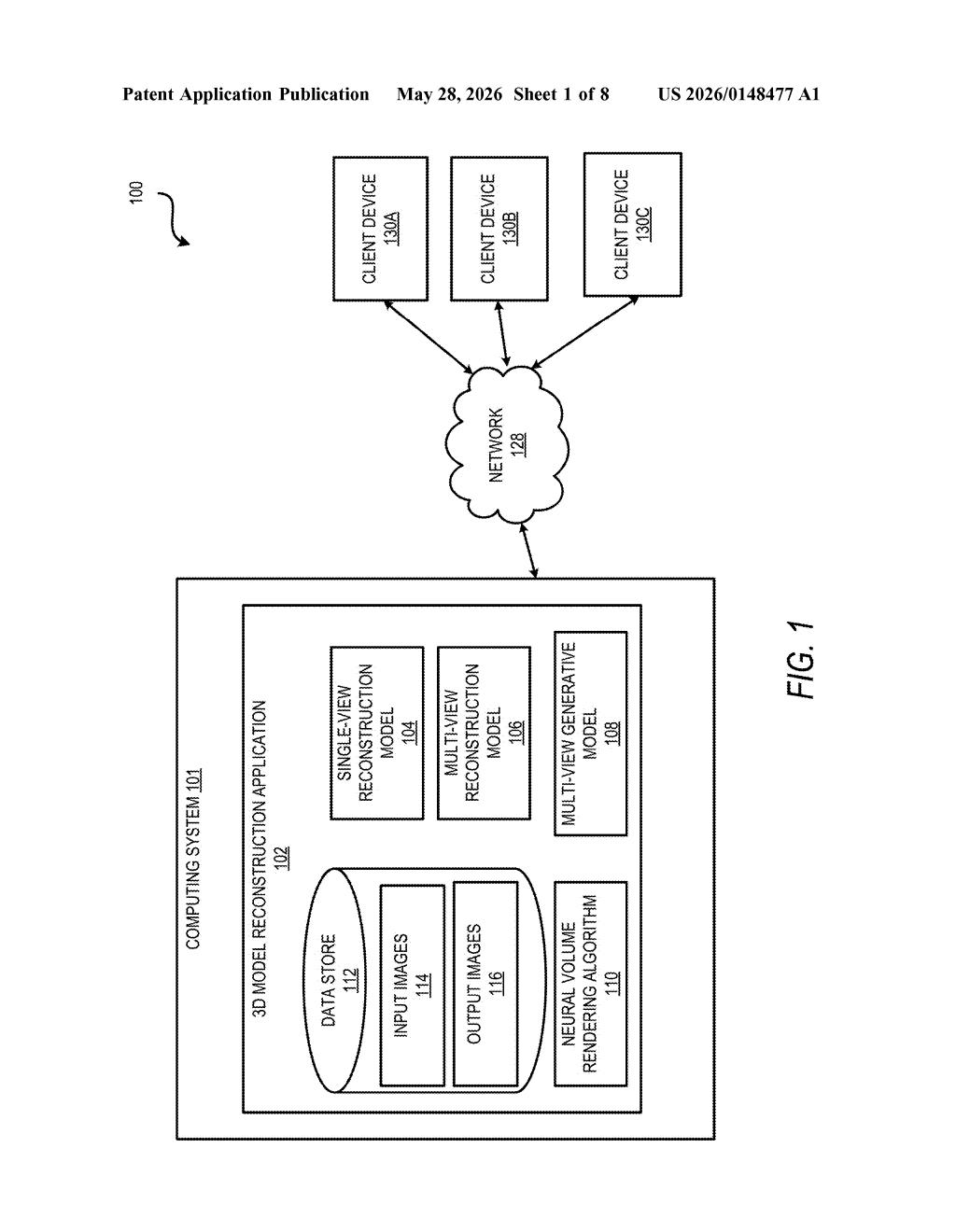
What Adobe's single-image 3D reconstruction actually does
Imagine you snap a single photo of a chair, a product, or a person, and your software instantly generates a full 3D model you can rotate, re-light, and render from any angle. That's the core idea here.
Adobe's patent describes a system that takes one ordinary photo and runs it through a chain of AI models. The first model figures out the shape and structure of whatever is in the picture. The second — a generative model — fills in the parts the camera never saw, essentially imagining what the back and sides look like. A third step, called neural volume rendering, stitches it all into a proper 3D object you can view from any angle.
The result is a set of output images of your subject from any viewpoint you choose, all generated from that single starting photo. No 3D scanner, no photogrammetry rig — just one image in, rotatable 3D out.
How Adobe's pipeline goes from one photo to a 3D volume
The system chains together three distinct AI components to get from a 2D image to a 3D representation.
- Single-view reconstruction model: Takes the input photo and encodes it into a feature representation — a compact, structured description of the subject's shape, texture, and spatial layout as seen from that one angle.
- Pre-trained multi-view generative model: Takes that single-view feature representation and expands it into a multi-view feature representation — essentially synthesizing what the object would look like from many other angles, even ones the camera never captured. This is the hardest part: the model is filling in occluded geometry from learned priors about how objects typically look.
- Neural volume rendering: Uses the multi-view features to compute a 3D representation of the target (likely a NeRF-style or similar implicit volume). Neural volume rendering works by casting virtual rays through a learned 3D field and integrating color and density values — producing photorealistic images from any camera position.
The final step renders one or more output images from arbitrary viewpoints based on that 3D representation. The whole pipeline is differentiable, meaning it can be trained end-to-end on large image datasets without requiring paired 3D ground-truth data for every example.
What this means for Adobe's creative and design tools
For creative professionals, the friction of getting objects into 3D has always been the bottleneck — you either need expensive scanning hardware or hours of manual modeling. A reliable single-image-to-3D pipeline would make 3D content creation dramatically more accessible inside tools like Photoshop, Illustrator, or Adobe Firefly.
Adobe's broader push into generative 3D is the real context here. This patent fits into a larger pattern of Adobe building AI-native creative workflows. If this works well in practice, your product photos, character sketches, or even stock images could become the raw material for 3D scenes — no specialist skills required.
Single-image 3D reconstruction is one of the genuinely hard problems in computer vision, and a lot of smart teams are working on it — so this isn't Adobe staking out empty territory. What's worth watching is how Adobe integrates this into actual products: a pipeline that works in a research demo and one that ships reliably in Photoshop are very different things. The patent is solid foundational work, but the proof will be in the product.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.