Red Hat Patents a Traffic-Director for AI Models That Picks the Right One for Each Query
When you have a dozen specialized AI models and an incoming question, how do you know which model should answer it? Red Hat's new patent describes a system that figures that out automatically.
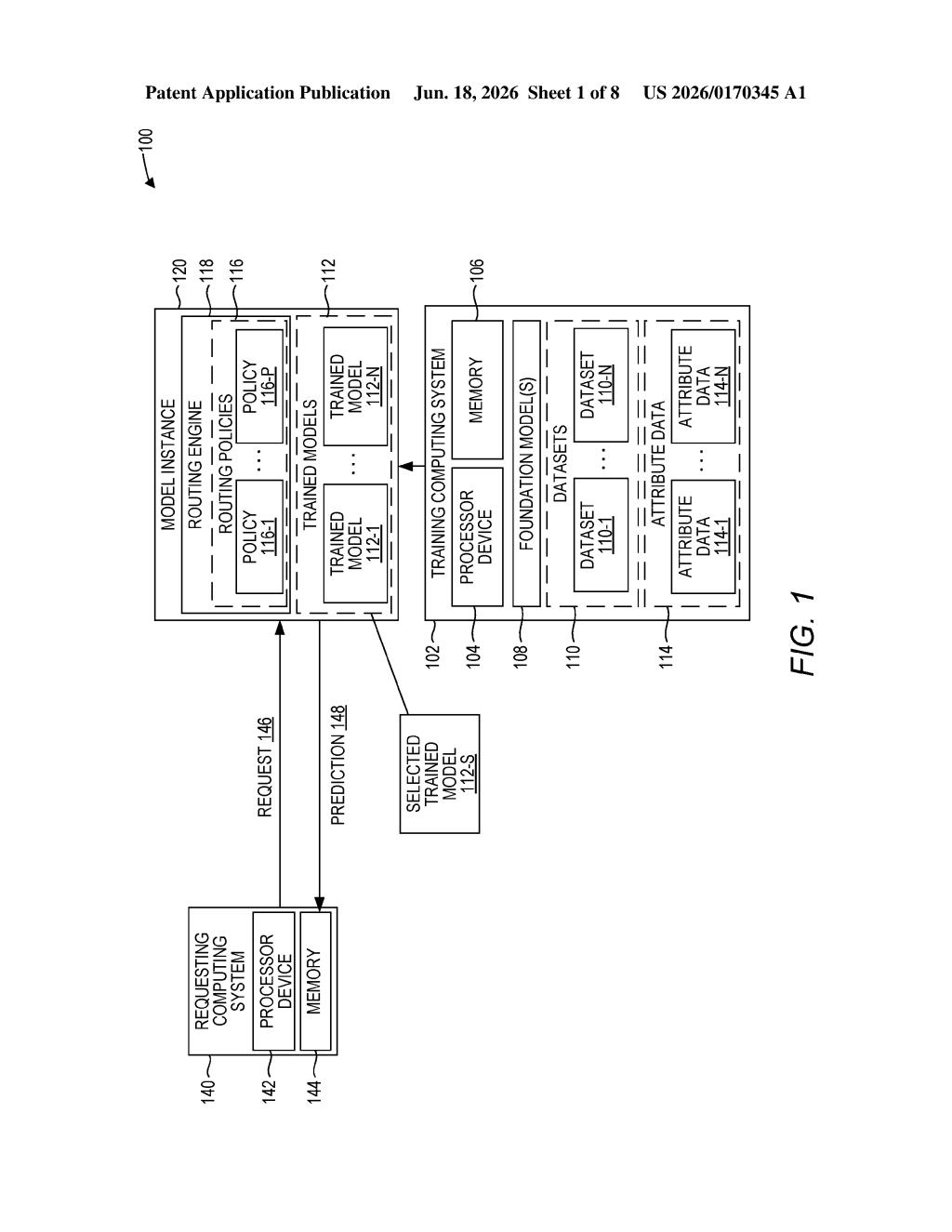
How Red Hat's AI routing system picks the right model
Imagine a hospital with several doctors, each a specialist in a different field. When a patient walks in, a triage nurse looks at their symptoms and sends them to the right doctor — not just any available one. Red Hat's patent describes the software equivalent of that triage nurse, but for AI models.
The idea is that instead of training one giant AI model to handle everything, you train several smaller models on different datasets — one might be trained on financial data, another on medical records, another on legal documents. Each one is better at its specialty than a generalist would be.
When a request comes in, a routing engine reads the nature of the request and consults a set of rules (called routing policies) to decide which trained model should handle it. The right model answers, and you get a more accurate result than you would from a one-size-fits-all approach.
How the routing engine maps requests to trained models
The patent describes a multi-stage system built around a central routing engine that acts as a dispatcher for a collection of AI models.
Here's how it works step by step:
- Train multiple models: A base foundation model (a large pre-trained AI, like the kind that powers chatbots) is fine-tuned on several different datasets. Each dataset has its own attributes — think of attributes as metadata describing what kind of data is in it (industry, language, time period, topic, etc.).
- Catalog those attributes: The system records descriptive data about each dataset's characteristics, so it knows what each resulting trained model is good at.
- Build routing policies: From that catalog, the system generates rules — if a request looks like X, send it to model Y.
- Route incoming requests: When a query arrives, the routing engine matches it against the policies and picks the best-fit model to answer it.
- Return a prediction: The selected model processes the request and returns its output.
The core claim is that routing decisions are driven by the dataset attributes of the training data, not just load-balancing or random assignment. That's what makes it selective rather than just a round-robin queue.
What this means for businesses running multiple AI models
For companies running AI infrastructure at scale — think cloud providers, enterprise software vendors, or large internal IT departments — managing dozens of specialized models is already a real problem. Without smart routing, you either build one bloated generalist model or you make developers manually decide which model to call for each use case. Both options are expensive and error-prone.
Red Hat is an enterprise infrastructure company owned by IBM, so this patent fits squarely into its business of selling AI deployment tools to large organizations. If this system ships as part of a product like OpenShift AI, it could make it meaningfully easier for enterprises to deploy multiple fine-tuned models without writing custom routing logic for every new use case.
This is a practical infrastructure patent, not a flashy AI research one. The underlying idea — route requests to the best-fit model based on training data characteristics — is straightforward, but straightforward ideas that nobody has formally systematized are often the ones that become widely adopted plumbing. Red Hat's positioning in enterprise AI deployment makes this worth tracking.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.