Red Hat Patents a System for Making AI Models Forget Specific Data
When an AI learns something it shouldn't have — say, your personal data — deleting that data from a database doesn't erase it from the model's brain. Red Hat is patenting a way to fix that.
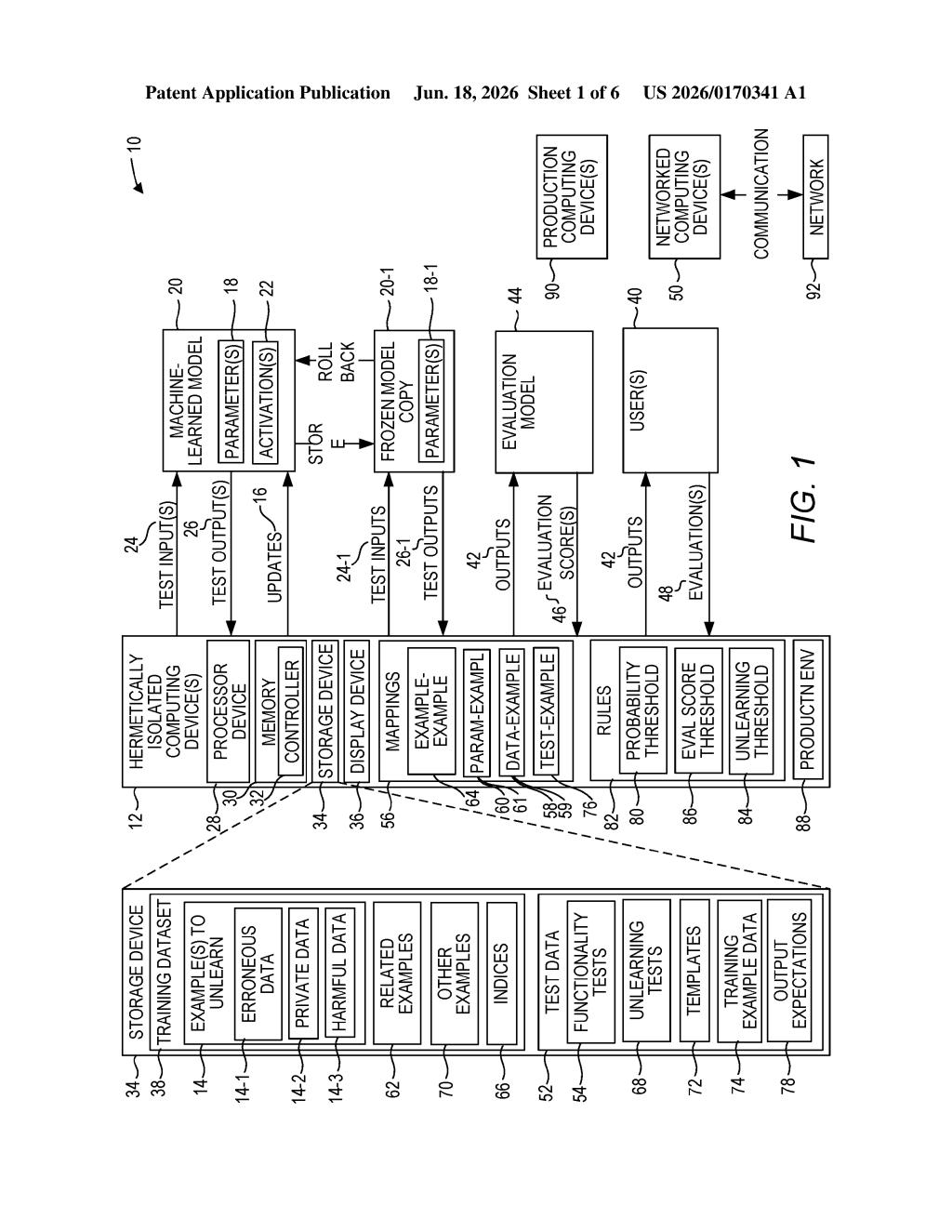
What Red Hat's AI 'unlearning' system actually does
Imagine a doctor trained on thousands of patient records. Even if you delete one patient's file from the hospital's system, the doctor still remembers what they learned from it. AI models have the same problem — once they've trained on a piece of data, that data's influence is baked into the model, even after you delete the original.
Red Hat's patent describes a method for making an AI model actively forget a specific piece of training data, not just remove it from a database. The system adjusts the model's internal settings to reduce the influence of that particular example, then tests whether the forgetting actually worked by feeding the model a question based on that same data.
If the model still seems to "remember" something it shouldn't, the system can keep adjusting. Think of it like a memory-erasure process with a built-in quiz at the end to make sure it took.
How the model tests its own forgetting before finishing
The patent describes a multi-step machine unlearning process — a field of AI research focused on selectively removing the influence of specific training examples from an already-trained model.
Here's how it works:
- Parameter adjustment: The system modifies the model's internal weights (the numerical values that encode what the model has learned) to reduce how much a specific training example affects the model's outputs.
- Verification test: After the adjustment, the system feeds the model a test input derived from the same training example that was supposed to be forgotten — essentially asking the model about what it was told to forget.
- Feedback loop: The model's response to that test is then used to guide further adjustments. If the model still shows signs of remembering, another round of updates follows.
This loop-based approach distinguishes it from simpler unlearning techniques that only perform a single-pass adjustment with no verification step. The goal is to confirm erasure, not just attempt it.
What this means for AI privacy and data-removal rights
Privacy laws like GDPR in Europe and CCPA in California give people the right to request that companies delete their data. But for AI systems, "deleting" a record from a database doesn't actually erase what the model learned from it. That gap between legal compliance and technical reality is a serious problem for any company deploying AI trained on user data.
A working unlearning system would let organizations actually honor those deletion requests in a meaningful way — without retraining an entire model from scratch, which is enormously expensive. For enterprise software, where Red Hat plays, this is a real operational headache. If this approach works reliably at scale, it could become a standard tool in how companies manage AI compliance.
This is genuinely useful infrastructure work, not a flashy AI feature. Machine unlearning is an active and important research area, and the feedback-loop verification step described here is a meaningful addition over naive approaches. Whether Red Hat's specific implementation is novel enough to survive patent scrutiny is another question, but the underlying problem it addresses — making AI forget responsibly — is one the industry needs to solve.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.