Amazon Patents a GPU Resource Sharing System for Multi-Project ML Workloads
Running three ML training jobs at once shouldn't mean one hogs the GPUs while the others wait. Amazon's new patent describes a system that watches GPU usage across all your projects in real time and automatically lends idle capacity to whoever needs it most — without breaking your predefined resource budgets.
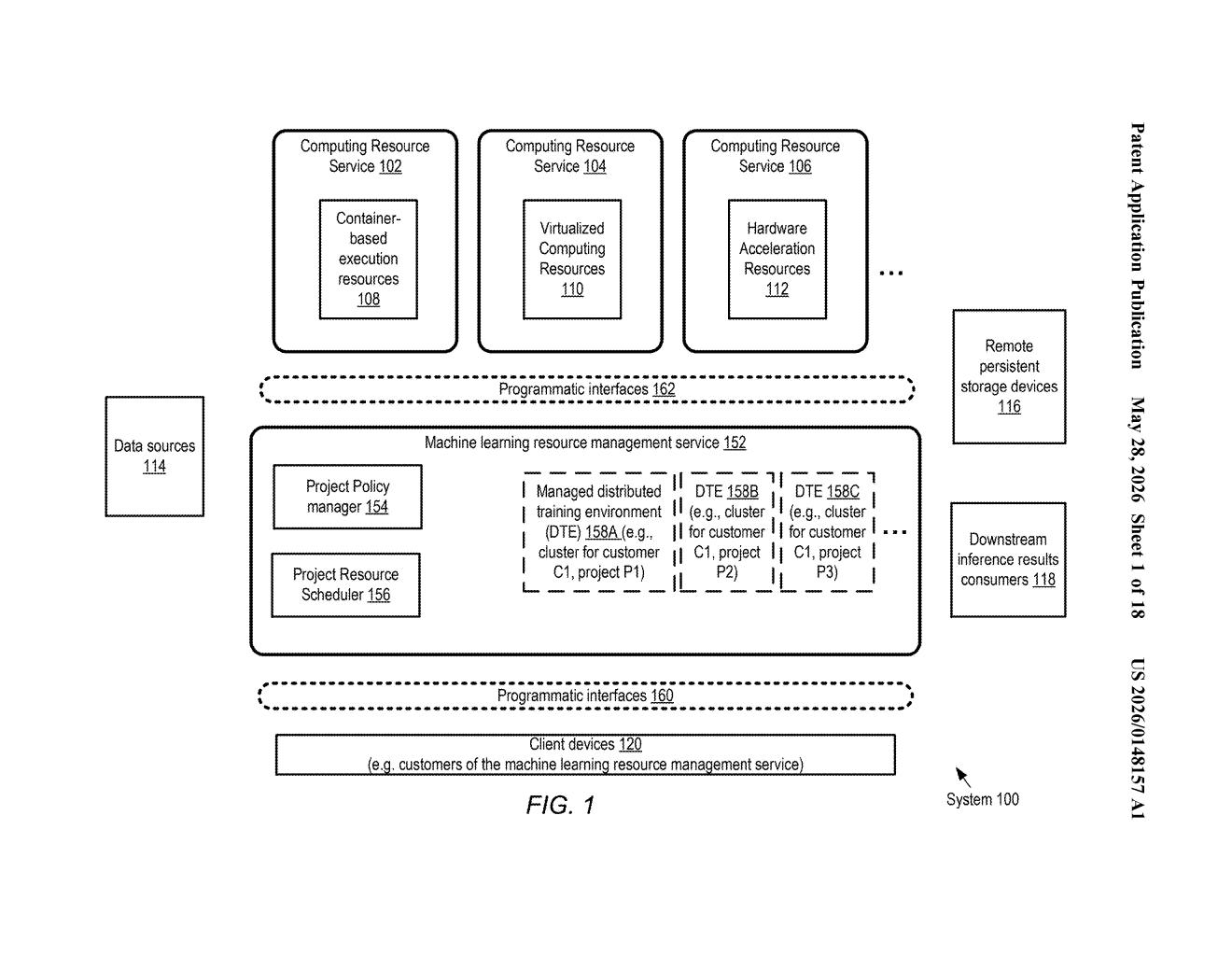
What Amazon's ML resource-sharing system actually does
Imagine you're a company training three different AI models at the same time — one for fraud detection, one for product recommendations, and one for demand forecasting. You've told your cloud provider each project gets a certain share of the GPU cluster. But what happens when the fraud model finishes a big batch run and sits idle for an hour while your recommendation engine is desperate for more compute? Right now, that spare capacity often just... sits there.
Amazon's patent describes a service that fixes this. You define your projects and their resource quotas up front, and the system automatically redistributes unused GPU capacity — called "burst capacity" — to whichever project needs it at that moment. Once the originally assigned project comes back to life, its resources are returned.
Critically, the system also tracks how much burst capacity each project has borrowed over time, so no single project can quietly hoard the slack. It's a fairness layer baked into the scheduler itself.
How the policy manager and scheduler divide GPU capacity
The patent describes two core software components working together inside a machine learning resource management service.
First, a policy manager exposes APIs that let customers define their ML projects and attach resource policies to each one — essentially setting the rules for how much compute each project is entitled to and under what conditions it can borrow more.
Second, a resource scheduler does the ongoing work:
- It identifies the pool of available ML resources (specifically virtualized compute with GPU access).
- It sends initial allocation instructions to the underlying cloud compute APIs, carving up GPUs per the customer's policies.
- It continuously monitors usage metrics — how much each project is actually consuming vs. what it was allocated.
- When it detects underutilization in one project, it automatically issues updated configuration instructions to loan that spare capacity as burst to a busier project.
The system also tracks cumulative burst usage across projects to enforce fair sharing — so a low-priority project can't silently consume weeks of slack GPU time that a high-priority project might need later. Think of it as a cloud-level GPU time-bank with a ledger.
What this means for AWS customers running multiple ML projects
For AWS customers running multiple concurrent ML workloads — which is basically every mid-to-large enterprise doing serious AI work — wasted GPU time is a real and expensive problem. Reserved GPU instances are not cheap, and idle capacity that goes unrecycled is money left on the table. This patent describes exactly the kind of infrastructure-layer automation that makes a cloud platform stickier: once your resource policies are defined inside Amazon's managed service, switching to a competitor means rebuilding all that scheduling logic yourself.
From a product angle, this looks like foundational plumbing for something like Amazon SageMaker's training job scheduling. The architecture here — a policy layer on top of a live-monitoring scheduler — is the kind of thing that quietly becomes a must-have feature for ML platform teams, even if no one writes a press release about it.
This is unglamorous but genuinely useful infrastructure work. The problem it solves — GPU waste across multi-project ML environments — is real, costly, and currently handled manually or not at all by most teams. The patent isn't describing new AI; it's describing better plumbing for running AI at scale, which is arguably more impactful for AWS customers right now than any model architecture patent.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.