Apple Patents a Programmable Chip That Bakes CNN Layers Directly Into Hardware
Apple is exploring a chip design where each layer of a convolutional neural network gets its own dedicated slice of programmable hardware — complete with its own memory buffers sitting right next door. It's a bet that specialization, not generalism, is the right path for AI inference at the edge.
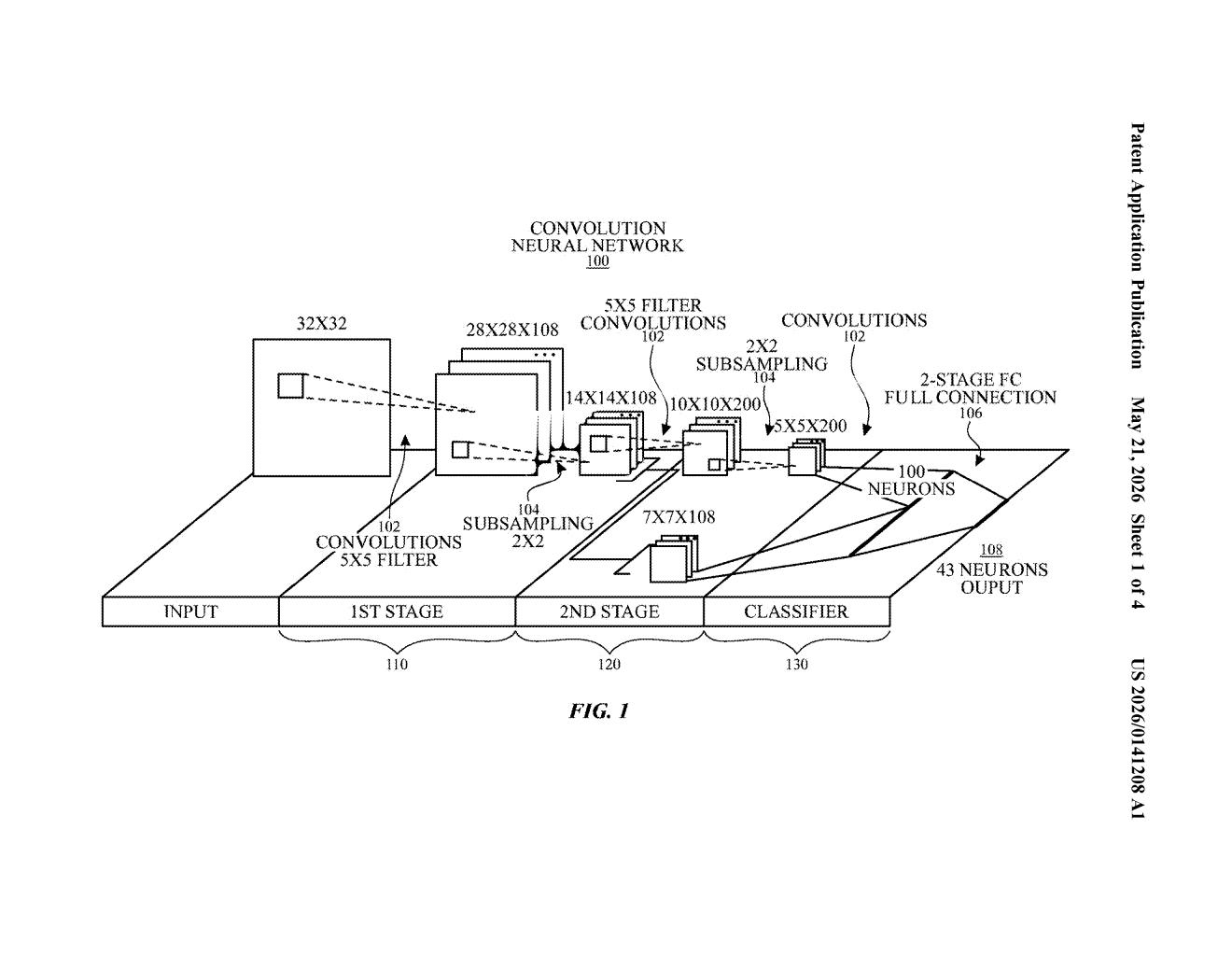
What Apple's CNN-on-a-chip design actually does
Imagine your phone running an image-recognition task — say, identifying what's in a photo. Normally, the AI model bounces data back and forth across shared memory and general-purpose processors, which takes time and burns battery. Apple's patent describes a different approach: bake each step of the AI's decision-making process directly into a programmable chip, so every stage has its own dedicated processing unit and its own local memory stash.
The chip described here uses a programmable logic device (PLD) — think of it like a chip you can reconfigure for a specific job, rather than a one-size-fits-all processor. Each "compute block" on this chip handles exactly one layer of the neural network. Right next to it sit two memory blocks: one acts as a scratchpad buffer for passing data through, and the other holds the model's learned parameters (the weights that make the AI actually work).
The result is an AI chip that's tuned to a specific neural network model, keeping data movement short and fast. Less shuffling data around means less power wasted and faster results — exactly what you want for anything running locally on a device.
How Apple maps each CNN layer to a dedicated compute block
The patent describes a hardware architecture for running convolutional neural networks (CNNs) — the family of AI models widely used for image recognition, object detection, and similar visual tasks — on a programmable logic device (PLD). A PLD is a chip whose internal logic circuits can be reconfigured after manufacture, making it more flexible than a fixed ASIC but more power-efficient than running AI on a general CPU.
The core idea is a strict one-to-one mapping between CNN layers and hardware compute blocks. In a typical CNN, the network processes an image through a series of convolution layers (each one detecting increasingly abstract patterns), subsampling layers (which shrink the data), and fully-connected layers (which make the final classification). Apple's design gives each of those layers its own dedicated compute block on the PLD.
Critically, each compute block has two memory blocks placed physically adjacent to it:
- A buffer memory that temporarily holds the output from the previous layer as it flows through
- A parameter memory that stores the model-specific weights and filters for that particular layer
This proximity matters. Moving data across a chip consumes energy and time. By keeping the compute and memory tightly coupled for each layer, the architecture minimizes data travel distance — a well-known efficiency strategy in AI hardware design called near-memory computing. The "customizable" part of the title refers to the fact that the PLD can be reprogrammed to match different CNN architectures or model sizes.
What this means for Apple's on-device AI ambitions
On-device AI is one of the clearest trends in consumer hardware right now, driven by privacy concerns, latency requirements, and the cost of sending everything to the cloud. Apple already ships the Neural Engine in its A-series and M-series chips, but this patent explores a more configurable approach — using programmable logic that could be tuned to a specific model rather than a fixed neural accelerator block.
For you as an end user, this kind of architecture could mean faster, lower-power AI inference for things like real-time camera processing, on-device translation, or health sensing — all without a round trip to Apple's servers. Whether Apple ever ships a consumer product with a PLD-based AI engine is an open question, but the research direction signals that the company is actively exploring how far it can push AI performance per watt at the chip level.
This is a solid, substantive AI hardware patent — not a vague software claim, but a specific architectural approach with clear engineering rationale. The near-memory computing angle and the layer-to-block mapping are both real ideas that show up in academic AI hardware research, so Apple isn't just patent-farming here. Whether it ends up in a shipping product or stays an internal research artifact is unclear, but it's worth following if you care about where on-device AI silicon is headed.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.