Samsung Patents a Way to Automatically Caption Video Frames Using Speech and Documents
Training a vision-language AI model requires mountains of matched image-text pairs — and building those pairs by hand is brutally expensive. Samsung's new patent describes a system that generates them automatically by mining synchronized video, speech, and related documents at the same time.
How Samsung turns lecture videos into labeled training data
Imagine a university lecture video: a professor talks over a slide deck, and there's a PDF syllabus on the course website. Right now, if you wanted to turn that into labeled data for an AI model, someone would have to watch the video, pick key frames, and write captions by hand. That's slow and pricey.
Samsung's patent describes a system that does this automatically. It watches a video, identifies a meaningful moment (say, the frame where a diagram appears), grabs the speech happening at that moment, and then cross-references a related document — like those lecture slides or a PDF — to pull in extra context. The result is a matched pair: one representative frame image, one rich descriptive caption.
The goal is to produce image-text pairs — the fundamental ingredient for training multimodal AI models that understand both pictures and words. By automating this pipeline, Samsung could generate enormous training datasets from existing video and document libraries without human labelers in the loop.
How speech, frames, and documents get matched and merged
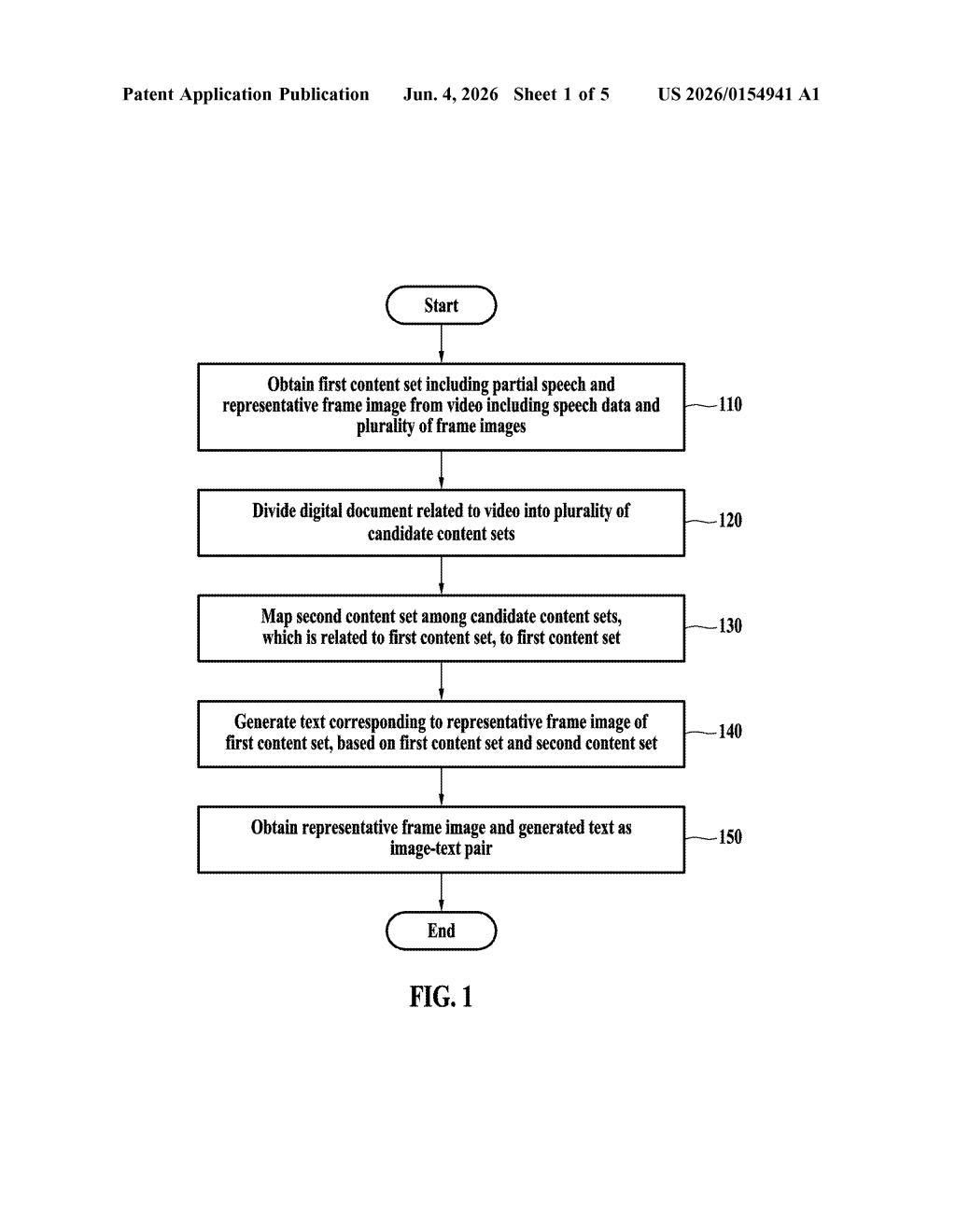
The system takes two inputs at once: a video (which includes both visual frames and an audio/speech track) and a digital document related to the video's content — think a matching PDF, slide deck, or transcript.
From the video, it extracts a first content set: a segment of speech paired with a representative frame image (the single best frame to capture a given moment). It then chops the document into candidate content sets — discrete chunks that might correspond to different parts of the video.
Next, it performs mapping: it finds which document chunk (the "second content set") is most relevant to the video segment it just extracted. This is essentially a cross-modal alignment step — matching spoken words and visual frames to the right paragraph or slide in the accompanying document.
Finally, with both the video-derived content and the aligned document chunk in hand, it generates text describing the representative frame — drawing on both the speech context and the document text for richer, more accurate captions. The output is a clean image-text pair ready for use in model training or indexing.
What this means for AI training data pipelines
The hunger for high-quality image-text pairs is one of the biggest bottlenecks in training vision-language models (VLMs) — the kind of AI that powers tools like image search, document understanding, and visual question answering. If Samsung can automate this pipeline using existing corporate or educational video libraries, they get a scalable data flywheel that doesn't depend on expensive human annotation.
For Samsung specifically, this fits neatly into their push to build on-device and cloud AI capabilities across Galaxy devices. A robust internal data pipeline for multimodal training would be a meaningful competitive advantage — especially if the system can be applied to Samsung's own product documentation, tutorial videos, or support content to build more capable on-device assistants.
This is unglamorous infrastructure work, but it's exactly the kind of patent that matters in the long run. The real war in AI right now is over data quality and data scale, and whoever automates the labeling pipeline best wins more training cycles. Samsung quietly building this capability is worth paying attention to.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.