Qualcomm Patents a Way to Batch CPU Instructions Before They Hit the AI Accelerator
Every time a CPU and an AI accelerator talk, there's overhead. Qualcomm's new patent proposes a buffer that bundles multiple instructions into one fat packet before they make the trip — cutting that overhead down significantly.
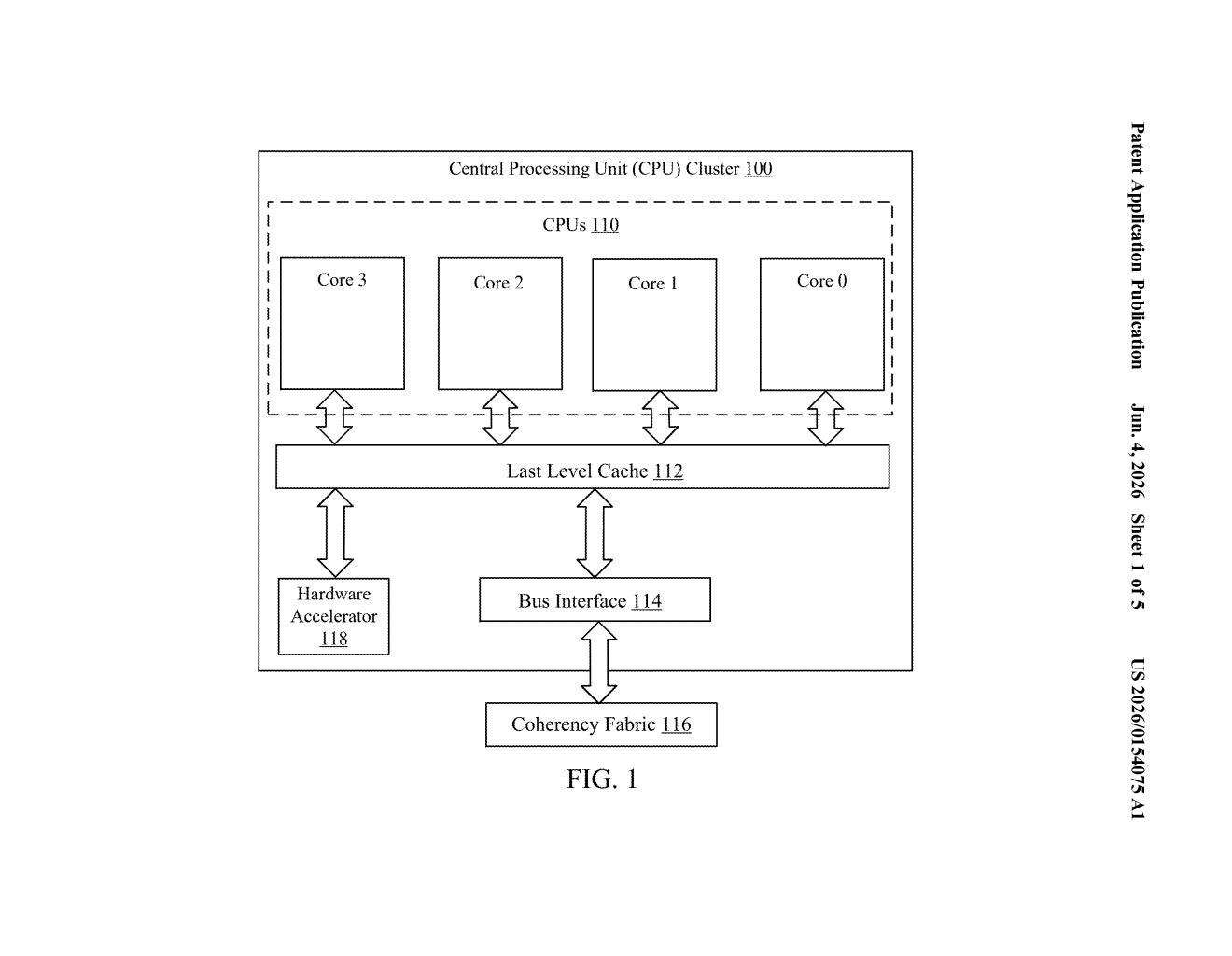
What Qualcomm's instruction-batching trick actually does
Imagine every time you needed to tell a coworker something, you had to walk across the office, deliver one sentence, walk back, then repeat. That's roughly what happens when a CPU sends instructions to a hardware accelerator one at a time — lots of trips, lots of wasted effort.
Qualcomm's patent describes a smarter mailroom approach. Instead of dispatching each instruction the moment it arrives, a small buffer collects multiple instructions and merges them into a single package before sending it on to the accelerator. The accelerator gets more work to do in one shot, and the communication channel between the two chips stays less congested.
This is particularly relevant for matrix math operations — the kind of heavy lifting done during AI inference tasks on a phone or laptop chip. By batching those requests, the accelerator spends more time computing and less time waiting on the next instruction to arrive.
How the CPU buffer merges requests into a single packet
The patent focuses on a class of CPU instructions called Scalable Matrix Extension (SME) requests — ARM architecture instructions designed to handle large matrix multiplications efficiently, which are the core operations in neural network inference.
The core mechanism works like this:
- A first SME instruction arrives at a CPU-side buffer rather than being dispatched immediately.
- A second SME instruction lands in the same buffer shortly after.
- The buffer merges both instructions into a single unified request packet.
- That consolidated packet is then sent to the hardware accelerator (think an NPU or DSP) as one transaction.
The key insight is that reducing the number of discrete transactions across the CPU-to-accelerator bus lowers latency and raises effective throughput — the accelerator gets more work per delivery. Think of it like switching from sending individual emails to bundling them into a single digest.
The patent doesn't specify a hard limit on how many instructions can be merged, which suggests the buffer depth and merge policy could be tunable based on workload characteristics.
What this means for mobile AI chip throughput
On a mobile SoC — the kind inside a flagship Android phone — the bandwidth between the CPU and the NPU is a real bottleneck for sustained AI inference. Every unnecessary handshake eats into the budget for performance and battery life. A batching layer at the CPU buffer level is a low-overhead fix that doesn't require redesigning the accelerator itself.
For you as an end user, this kind of optimization is what the difference between a responsive on-device AI assistant and a laggy one often comes down to. It's not glamorous, but instruction throughput improvements compound quickly in workloads that fire off thousands of matrix operations per second.
This is firmly in the 'plumbing' category of patents — nobody is going to write a press release about a CPU buffer merge scheme. But Qualcomm's Snapdragon chips live and die by this kind of microarchitectural efficiency work, and patents like this are the unglamorous scaffolding that makes on-device AI actually usable. Worth a footnote if you follow mobile chip architecture.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.