AMD Patent Uses Boolean Matrix Factorization to Shrink AI Models for FPGA Deployment
Running AI directly on a programmable chip is already a tight squeeze. Xilinx has filed a patent for a technique that compresses those AI models further, trading a tiny bit of accuracy for a meaningful cut in chip resources.
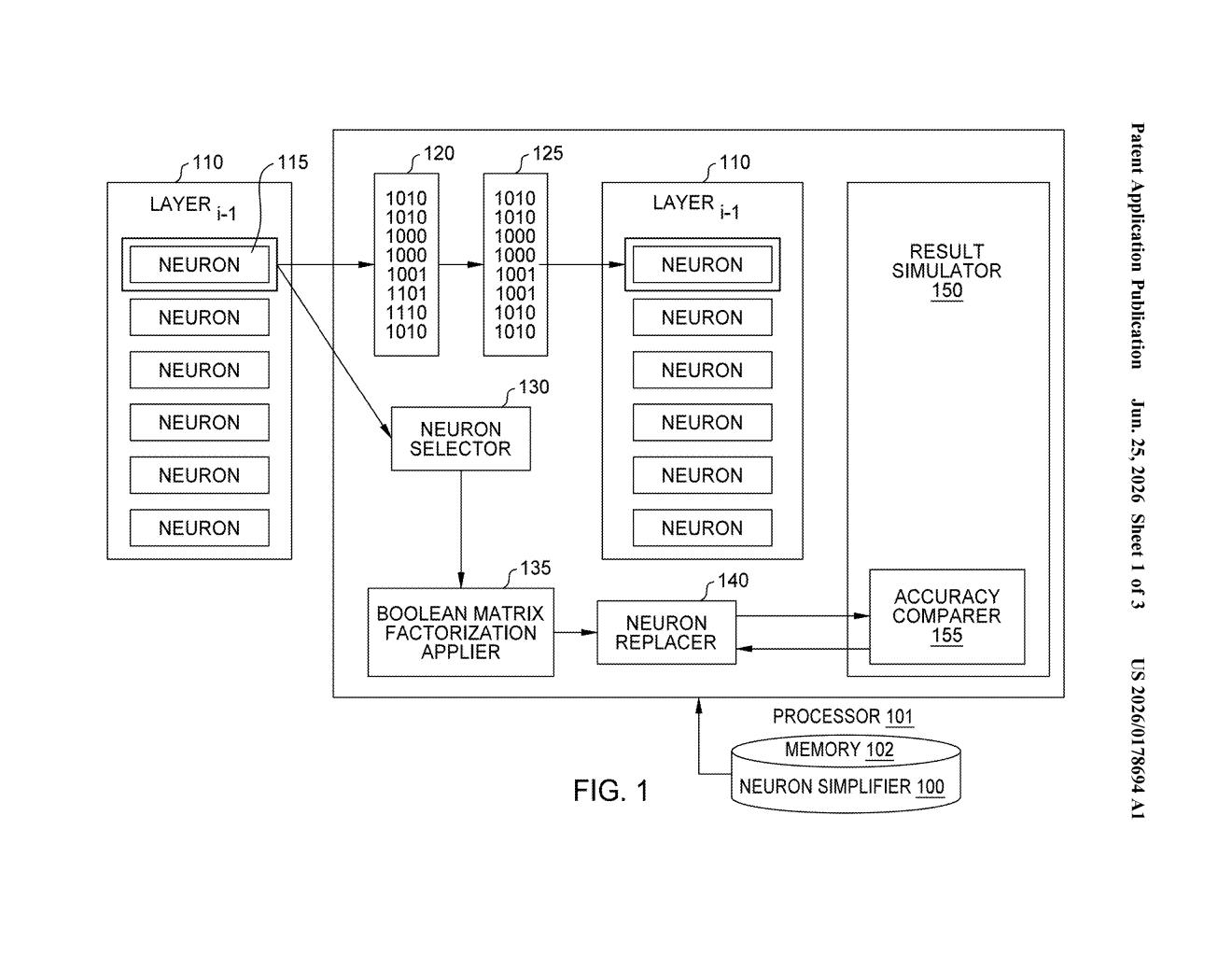
What Xilinx's chip-native AI compression actually does
Imagine trying to fit a complex recipe into an index card. You'd cut steps that don't change the final dish much, keeping only what really matters. That's roughly what this patent does for AI running on Xilinx's field-programmable chips.
Most AI models run on general-purpose processors or graphics cards. But Xilinx specializes in programmable chips (called FPGAs) that can be wired up to run a specific task extremely fast and with very little power. One way to put AI on these chips is to represent each neuron as a simple lookup table, basically a cheat sheet that maps every possible input combination to an output.
The problem is those lookup tables can get large. This patent describes a method to automatically shrink them using a math technique that finds a simpler version of the table that gets close enough to the same answer. The system then tests whether the simplified version still meets an accuracy target, and only keeps the swap if it does.
How Boolean matrix factorization simplifies a neuron's logic table
The patent targets a specific class of neural networks called LUT-based neural networks, where each artificial neuron is encoded as a truth table (a complete list of every input-output combination, like a logic gate in digital hardware). These networks are designed to run natively on FPGAs, which are chips whose internal logic can be reconfigured.
The core operation is called Boolean Matrix Factorization (BMF), a technique that takes a large binary table and approximates it using two smaller binary matrices multiplied together (in Boolean algebra, where everything is either 0 or 1). The result is a second, simplified truth table that is an approximation of the original neuron's behavior.
The process works like this:
- Pick a neuron from the network and read its truth table.
- Run BMF to generate a compressed approximation of that table.
- Swap the original table for the new one in the network.
- Simulate the updated network and measure its cost using a cost function (a formula that balances prediction accuracy against how many chip resources are consumed).
- If the cost is within an acceptable threshold, keep the swap; otherwise, revert it.
The net effect is that individual neurons can be made cheaper to implement on chip without gutting the overall model's accuracy.
What this means for AI running on edge hardware
FPGAs are increasingly popular for edge AI, meaning AI inference that runs locally on a device rather than in a remote data center. Think industrial sensors, medical imaging equipment, or network switches that need instant responses. In those settings, chip area and power consumption are hard limits, not just preferences.
A method that automatically trims AI models to fit tighter onto these chips, while checking that accuracy doesn't fall below a set floor, is genuinely useful for engineers trying to deploy AI in constrained hardware. It removes a manual tuning step that currently requires a lot of expert iteration. For , the end user, this could mean faster and cheaper AI-powered devices that don't need a cloud connection.
This is fairly deep infrastructure work, the kind of thing that matters a lot to FPGA engineers and almost nobody else. But Xilinx (now part of AMD) is one of the main players in edge AI chips, and any technique that makes LUT-based neural networks cheaper to deploy is a real contribution to that ecosystem. It won't make headlines outside the hardware community, but it's the kind of quiet engineering that eventually shows up in products you use.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.