Xilinx Patents Fine-Grained Task Preemption for Neural Processing Units
When two AI tasks compete for the same chip, the more urgent one usually has to wait its turn. Xilinx's new patent describes a way to make neural processing units interrupt themselves mid-task so a higher-priority job can cut the line.
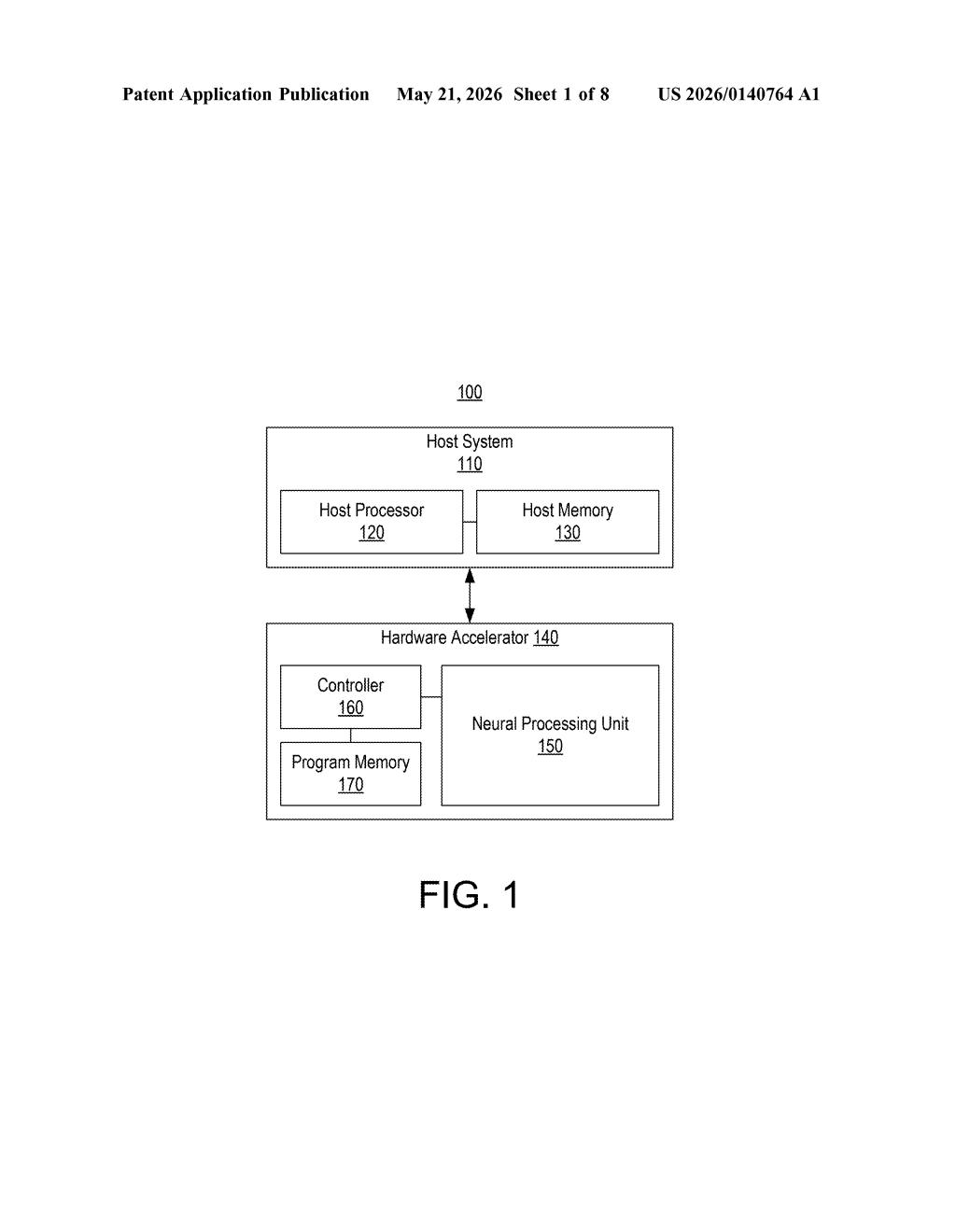
How Xilinx's NPU juggles urgent AI tasks mid-run
Imagine you're printing a long document when an urgent fax comes in — most printers just keep printing and make the fax wait. The same problem happens on AI chips: a low-priority background task can hog the processor while something time-sensitive sits in the queue.
Xilinx's patent describes a fix built directly into how the chip's controller reads its own instructions. Special preemption opcodes — think of them as built-in pause markers scattered through the task's code — let the chip cleanly stop what it's doing at a safe checkpoint whenever a higher-priority task is waiting.
The chip saves the state of the first task, hands control over to the urgent one, and can resume the original job later. That whole handoff is managed by the NPU's controller, and it happens at a much finer level of detail than traditional GPU-style task switching.
How the preemption opcode triggers a context switch
The patent targets neural processing units (NPUs) built on a dataflow architecture — a design where computation flows through a grid of specialized tiles (compute tiles and memory tiles) rather than a single sequential processor. In dataflow chips, pausing mid-execution is tricky because work is spread across many tiles simultaneously.
The solution is a preemption opcode embedded directly in the NPU's control-code. As the controller (the chip's central sequencer) steps through instructions for a running task — called a context — it scans for these special opcodes. When it hits one, it checks whether a second context with a higher priority is waiting. If so, it triggers a context switch: the first task is suspended, and the second takes over the NPU's resources.
Key design elements include:
- Preemption points are author-defined — they're baked into the control-code at logical safe points, not forced at arbitrary clock cycles
- The controller detects the waiting higher-priority context only after encountering a preemption opcode, keeping the switch orderly
- The architecture spans a tiled compute-and-memory grid (the patent shows a 4×5+ tile array), meaning the preemption mechanism must coordinate across distributed state
This is meaningfully different from coarse-grained preemption (waiting for an entire kernel to finish) or GPU-style time-slicing, which doesn't map cleanly onto dataflow NPU topologies.
What priority-aware NPUs mean for real-time AI workloads
For AI inference at the edge or in data centers, latency guarantees matter enormously. A self-driving inference pass, a fraud detection signal, or a voice-assistant wake-word response can't afford to queue behind a batch image-processing job. Without fine-grained preemption, NPU schedulers have to either over-provision hardware or accept unpredictable latency spikes.
Xilinx (now part of AMD) designs FPGAs and adaptive silicon that often run multiple concurrent AI workloads. This patent suggests they're investing in real-time multitasking infrastructure for NPUs — the kind of capability that makes enterprise and automotive customers comfortable deploying mixed-criticality workloads on a single chip.
This is solid, unglamorous systems work — the kind of paper that ships quietly inside a toolchain update and then powers a product differentiator nobody talks about publicly. Fine-grained preemption on dataflow NPUs is a real unsolved problem, and embedding preemption hooks in the control-code is a pragmatic approach that doesn't require redesigning the tile architecture. AMD/Xilinx building this out is a meaningful signal that they're targeting mixed-criticality real-time AI deployments, not just throughput-maximizing data center inference.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.