Google Patents a System That Hides Sensitive Objects From Its AI Before They're Processed
Before Google's AI even looks at your image to answer a question, this patent describes a gatekeeper that quietly removes certain objects from the picture — so the AI never has a chance to process, describe, or mention them.
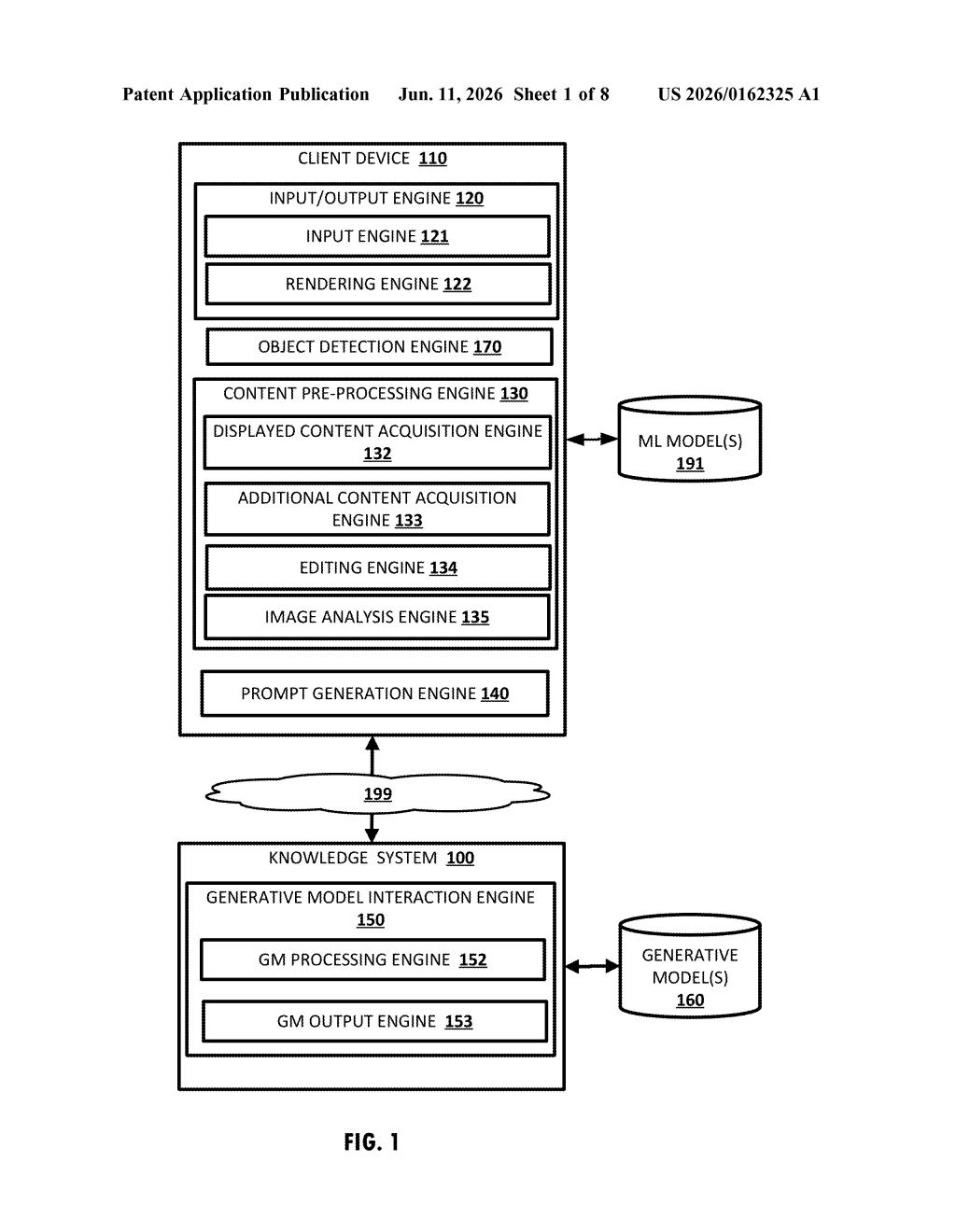
What Google's image-scrubbing AI filter actually does
Imagine you take a photo of your desk and ask an AI assistant to help you organize it. Your desk also has a sticky note with a password on it, or a confidential document, or maybe a person's face. You didn't mean to include those things — but the AI would see them anyway.
Google's patent describes a system that intercepts the image before it reaches the AI. It scans the photo, identifies any objects that fall into restricted categories — things a company might flag as sensitive — and either removes them from the image or rewrites the description so those objects are never mentioned. The AI then gets a cleaned-up version to work with.
The result: the AI generates a response as if the sensitive objects were never there. Your confidential information stays out of the model's context entirely, rather than relying on the AI to politely ignore what it has already seen.
How the pipeline strips objects before the AI prompt is built
The system sits between a user's image request and a generative AI model, acting as a content filter at the image level.
When a request arrives with an attached image, the pipeline runs the image through an object detection step — essentially asking: does this photo contain anything on the restricted list? That list could include things like faces, license plates, branded logos, proprietary documents, or any other category a deploying organization defines.
If a restricted object is found, the system takes one or both of two actions:
- Updates the image data — generating a version of the image with the flagged object removed or masked
- Updates the textual description — if the image is converted to a text description (a common step before feeding images into language models), the description is rewritten to omit any mention of the restricted object
That cleaned image and/or description is then used to build the input prompt — the instruction sent to the generative model. The model never receives the restricted content in any form, so it cannot include it in its output, reference it, or inadvertently surface it. The final generated response goes back to the user as normal, just without any trace of the sensitive material.
What this means for AI privacy and enterprise image tools
For businesses deploying AI assistants on top of real-world image data — think warehouse management, healthcare records, retail floor tools, or enterprise productivity apps — this kind of filter is a serious compliance need. You can't un-see something, and relying on a language model to self-censor after it has already processed sensitive content is not a reliable data governance strategy. Google's approach removes the data before it enters the model's context, which is architecturally cleaner and easier to audit.
For everyday users, the more immediate implication is that AI tools built on this system could become safer to use in situations where accidental data exposure is a risk — photographing a workspace, scanning a document, or sharing a scene that contains more information than you intended to hand over.
This is genuinely useful infrastructure work, not a flashy AI trick. The insight — that filtering should happen before the model sees anything, not after — is the right engineering instinct, and it solves a real problem that enterprises have been wrestling with since multimodal AI went mainstream. Whether Google ships this as a configurable feature in Vertex AI or Workspace is the interesting question.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.