Google Patents a Tool That Browses the Web and Completes Tasks for You
What if you could tell your browser 'book me the cheapest flight to Chicago next Friday' and it just... did it? That's exactly the kind of task Google's new patent is designed to handle.
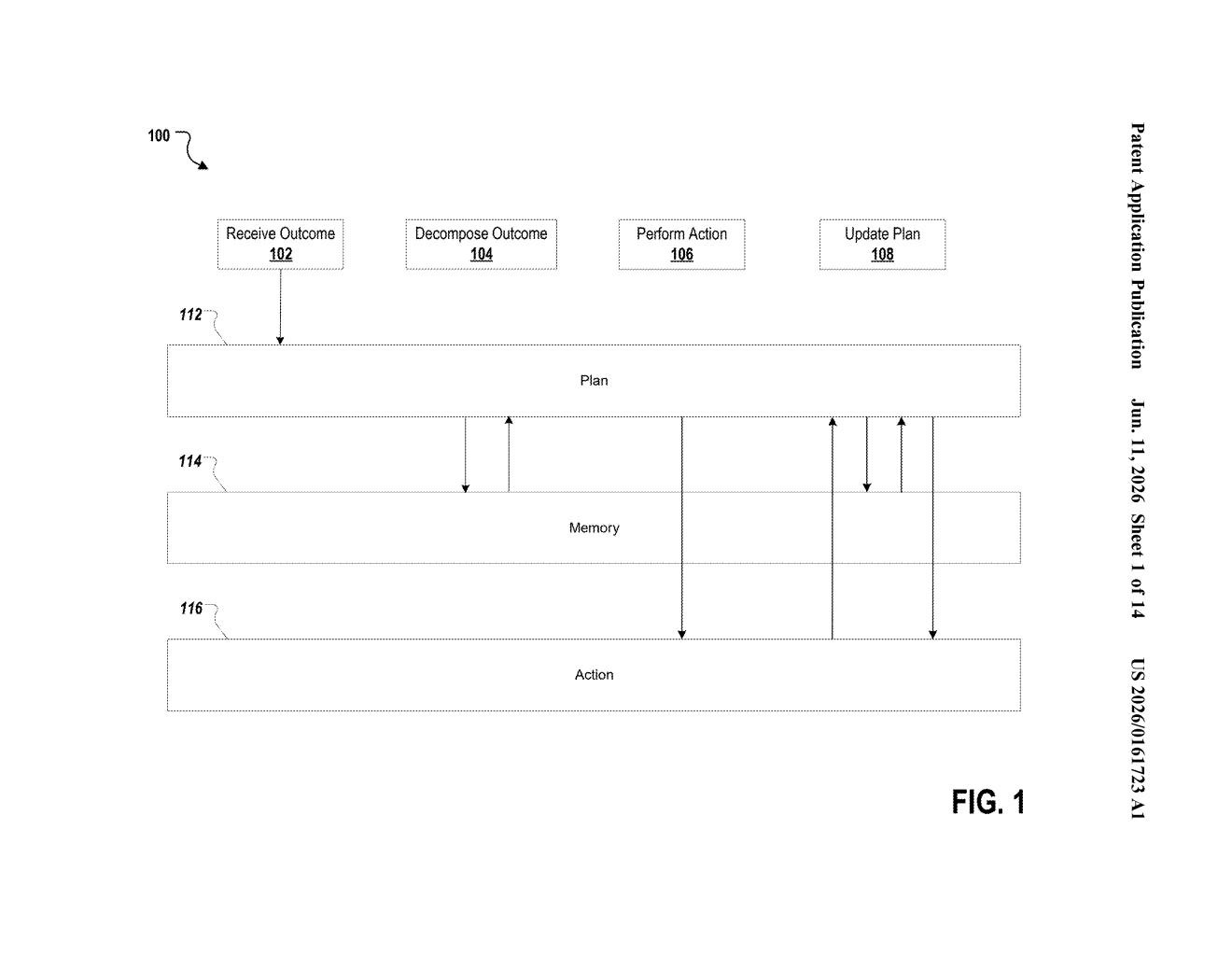
What Google's browser AI agent actually does for you
Imagine typing a request into your browser — 'find me a hotel near the conference center for under $200 a night and check availability' — and watching it actually complete the task for you, clicking through sites, filling in forms, and reporting back when it's done. That's the core idea behind this Google patent.
Google's browser-based agent sits inside your browser and acts like a capable assistant who knows how to operate the web. You give it an instruction, and it figures out what steps are needed, visits the right sites, and takes the necessary actions — all on its own. Crucially, it can run several of those steps at the same time, so it doesn't have to wait for one thing to finish before starting the next.
The result shows up in a separate part of your browser interface, confirming when the job is done. You stay in the loop without having to do the legwork yourself.
How the planning model breaks tasks into parallel actions
The patent describes a two-layer AI system embedded directly in a browser. The first layer is a planning model — think of it as a project manager. It reads your instruction and your current browser context (what tabs are open, what pages you've visited, your browsing data), then breaks the task into an ordered sequence of steps.
What makes this notable is that the planning model can designate certain steps to run in parallel (simultaneously, rather than one-after-another). If your task requires checking three different websites for price comparisons, it doesn't have to visit them one by one — it can query them all at once, cutting total time significantly.
The second layer is an action model — the worker who actually does the clicking. It translates the plan into low-level browser interactions: things like clicking buttons, scrolling, filling in form fields, and reading page content. This happens automatically, using live content from real websites.
The flow looks roughly like this:
- You type an instruction into a browser interface element (think: a side panel or address-bar-style input)
- The planning model maps out what needs to happen and in what order
- The action model executes each step on real websites
- A confirmation appears in a second interface element when the task is complete
What this means for how we use browsers day-to-day
Browser-based AI agents are one of the most actively contested areas in tech right now — OpenAI, Anthropic, and Microsoft are all building similar capabilities. Google filing a patent here signals it's serious about owning this interaction model, particularly inside Chrome, where it has a structural advantage: direct access to browser data that external agents don't have.
For you as a user, the practical upshot is a browser that stops being a passive display of web pages and starts acting like a capable assistant. The parallel-execution detail is especially worth noting — it suggests Google is engineering for speed, not just novelty, which is what it would take for people to actually trust and use this for real tasks.
This patent is a direct shot at the emerging 'computer use' AI category that OpenAI and Anthropic have been racing to define. Google's structural advantage here is Chrome's massive install base and its ability to integrate the agent at the browser engine level rather than as a bolt-on. The parallel-action execution detail isn't just an engineering footnote — it's the thing that would make this actually usable for complex, multi-step tasks.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.