Google Patent Reveals Voice Cloning Tech That Requires Just a Few Audio Clips
Google has patented a way to teach its text-to-speech AI to mimic a specific person's voice using only a handful of audio recordings, without overhauling the underlying model each time.
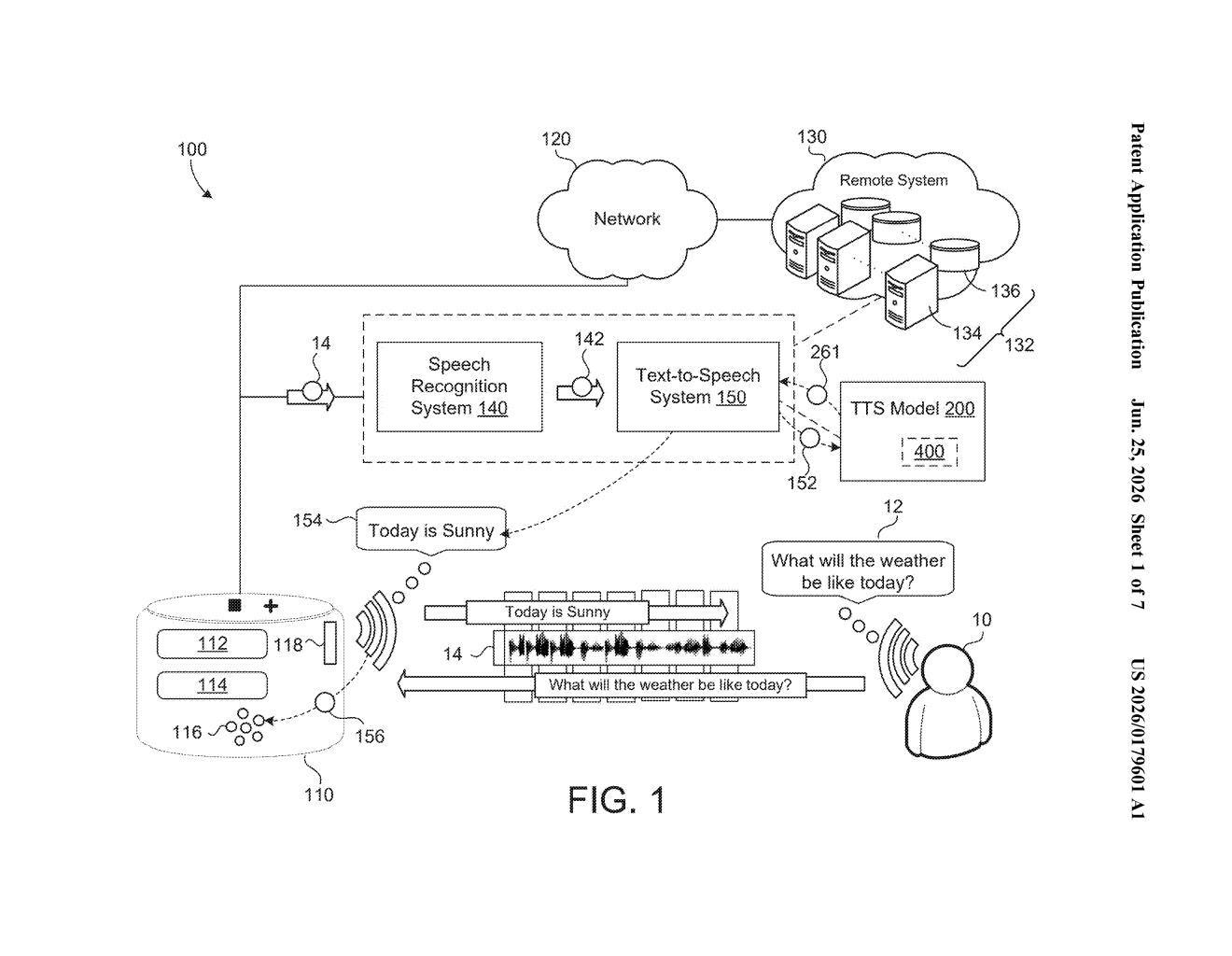
How Google's voice cloning works with minimal audio
Imagine you want a voice assistant that sounds exactly like you, or like a specific narrator, rather than the generic robotic voice that came out of the box. Today, teaching an AI to copy a voice usually means feeding it hours of recordings and running an expensive retraining process. Google's patent describes a much lighter approach.
Instead of rewriting the whole AI, Google's system snaps in small add-on modules called residual adapters around the existing model. You give the system a few short recordings of the target speaker, it tunes only those lightweight add-ons, and the core AI stays untouched. The result is a text-to-speech engine that speaks in your chosen voice.
The system also takes in expressiveness cues, meaning it can carry over the pacing, tone, and rhythm of the original speaker, not just the timbre of their voice. That's the difference between a voice that technically sounds like someone and one that actually feels like them.
How the residual adapters learn a new voice without touching the core model
The patent describes a few-shot speaker adaptation pipeline built on top of a pre-trained text-to-speech model. "Few-shot" means the system needs very little new data (think a handful of spoken sentences, not hours of studio recordings) to learn a new voice.
The core trick is residual adapters: small neural network layers inserted inside the model's transformer-based decoder (the part of the AI that generates speech audio step by step). These adapter layers are the only parts that get updated during voice training. The rest of the model's weights are frozen, meaning they're locked in place, so Google doesn't have to retrain its massive base model every time it wants to support a new voice.
Here's the pipeline the patent lays out:
- An encoder converts the input text into a numerical representation of what to say.
- A variance adaptation module blends that text representation with expressiveness embeddings (mathematical descriptions of speaking style, like how fast or emphatic the target speaker tends to be).
- The frozen backbone model, now augmented with the tuned adapters, generates the final speech audio in the target speaker's voice.
Because only the small adapter modules are optimized per speaker, the process is far faster and cheaper than full model retraining, and multiple speakers' adapters could theoretically be swapped in and out like interchangeable plugins.
What this means for personalized AI voice assistants
The practical appeal here is efficiency. Training a full text-to-speech model from scratch for every new voice is expensive and slow. This approach could let Google (or developers using Google's APIs) add personalized voices to products without the cost ballooning. You can imagine it powering things like a Google Assistant that speaks in a user's own voice, or accessibility tools that let someone preserve their natural voice digitally.
The expressiveness component is the more interesting wrinkle. A lot of voice-cloning systems nail the tone of a voice but flatten out the personality. By explicitly modeling prosody (the rhythm and emphasis patterns of speech) as a separate input, Google is trying to make cloned voices feel less like a mask and more like the real thing.
This is solid, incremental AI infrastructure work rather than a dramatic reveal. The adapter-based approach to voice cloning is a well-established research direction, and Google is essentially patenting a specific architectural implementation of it. The expressiveness embedding angle is the most interesting piece and the one most likely to show up in a real product. Worth tracking if you follow voice AI, but not a surprise move.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.