Google's New Patent Stops Attackers from Poisoning Its AI with Bad Data
If you can figure out exactly what data an AI was trained on, you can feed it carefully crafted junk to break it. Google's new patent is designed to make that kind of attack a lot harder.
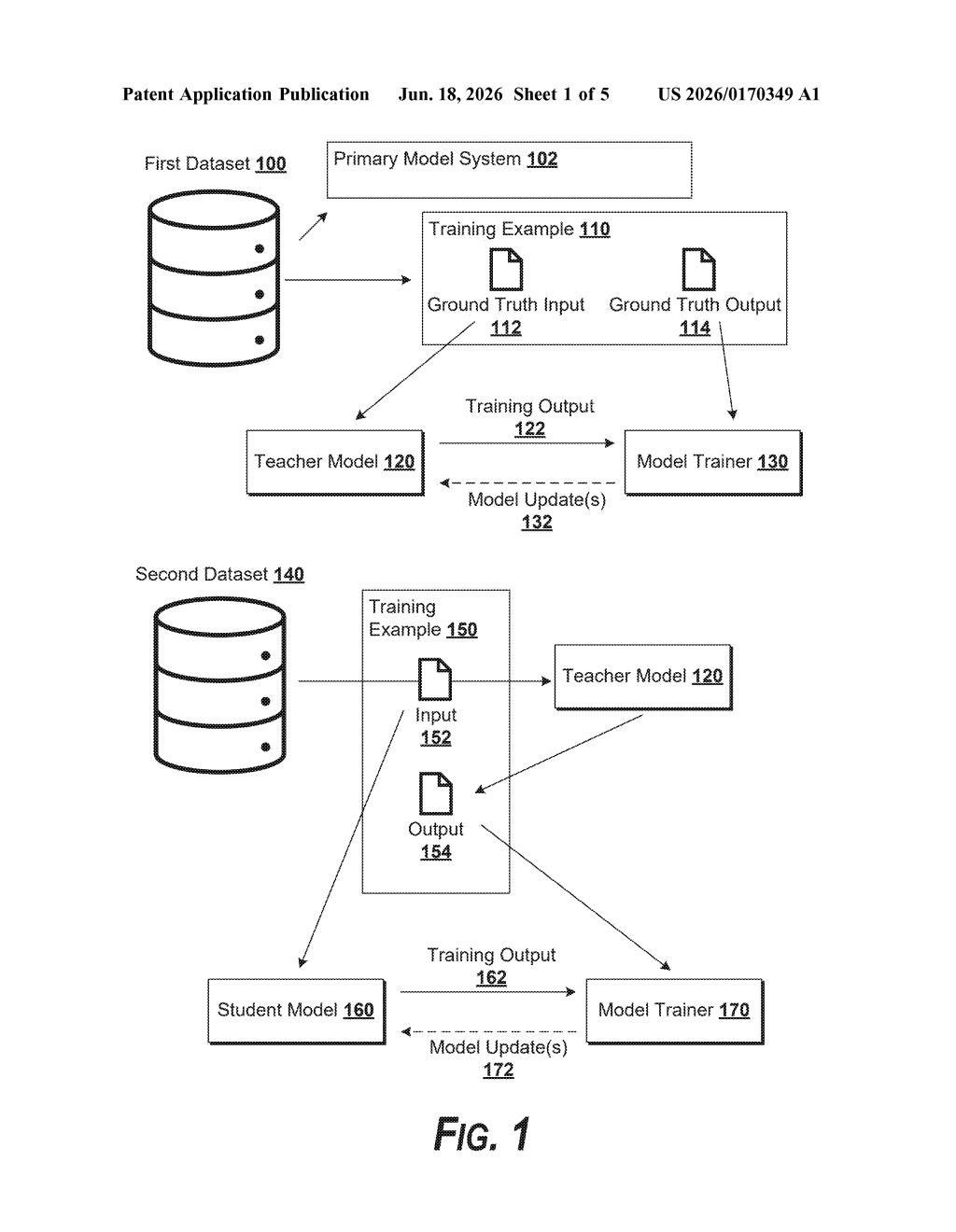
What Google's AI training firewall actually does
Imagine a criminal who knows exactly what examples a fraud-detection AI studied — they could craft transactions that look just normal enough to slip past it. That's called a data poisoning attack, and it's one of the more serious threats to AI systems in the real world.
Google's patent describes a two-step training process that acts like a firewall. A powerful teacher AI first learns from the original data. Then a second, lighter student AI is trained — but instead of learning from that original data directly, it only sees outputs the teacher produced on a carefully shuffled set of inputs. The student never sees the real training distribution, so an attacker can't reverse-engineer it.
The result is a student model that behaves a lot like the teacher — but whose decision-making logic is harder to probe or manipulate, because its own training history is obscured from the outside.
How the teacher-student gap blocks data poisoning
The patent describes a technique called knowledge distillation with obscured data distribution — a mouthful, but the core idea is straightforward.
Normally, when a smaller "student" model is trained to mimic a larger "teacher" model, both models train on data drawn from the same distribution (meaning the same kinds of inputs, in the same proportions). That shared history is a vulnerability: an attacker who knows the source dataset can craft adversarial inputs tuned to confuse the student.
Google's method breaks that link. The student's training dataset is assembled by pulling inputs from a broader data corpus, deliberately shuffling the proportions so the mix no longer reflects the teacher's original training data. The teacher then labels those inputs — essentially saying "here's how I'd answer this" — and the student trains on those teacher-generated answers.
- Teacher model: trained normally on real source data
- Distillation dataset: sampled to obscure the original data distribution
- Student model: trained only on the teacher's outputs, never touching source data directly
Because the student's decision boundaries (the lines it draws between correct and incorrect answers) emerge from a different data mix, they don't perfectly mirror the teacher's — which means attacks calibrated against the teacher won't automatically work on the student.
Why AI data poisoning is a real security problem
AI systems are increasingly used in high-stakes settings — content moderation, fraud detection, medical triage — where bad actors have strong incentives to probe and manipulate them. The ability to reconstruct a model's training data from its outputs is a known attack vector, and the standard knowledge distillation process inadvertently makes that easier by preserving the original data's fingerprint.
This patent is Google's attempt to bake adversarial resistance into the training pipeline itself, rather than bolting on defenses afterward. If it works at scale, it could make deployed AI systems noticeably harder to fool — which matters for your experience every time you rely on a Google product to filter spam, flag harmful content, or surface search results.
This is a genuine security patent, not a vague AI filing. The teacher-student distillation setup is well-established, and Google is doing something specific and defensible: breaking the data-distribution link that makes distilled models easy to attack. It's the kind of infrastructure-layer security work that doesn't get headlines but quietly makes AI deployments more trustworthy.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.