Google Patents the 'Teacher-Student' AI Training Method Behind Model Compression
Three of the biggest names in deep learning — Hinton, Dean, and Vinyals — are on a Google patent for knowledge distillation, the technique that lets a tiny model learn the 'wisdom' of a massive one. This isn't a new idea, but Google is now formally staking a claim on it.
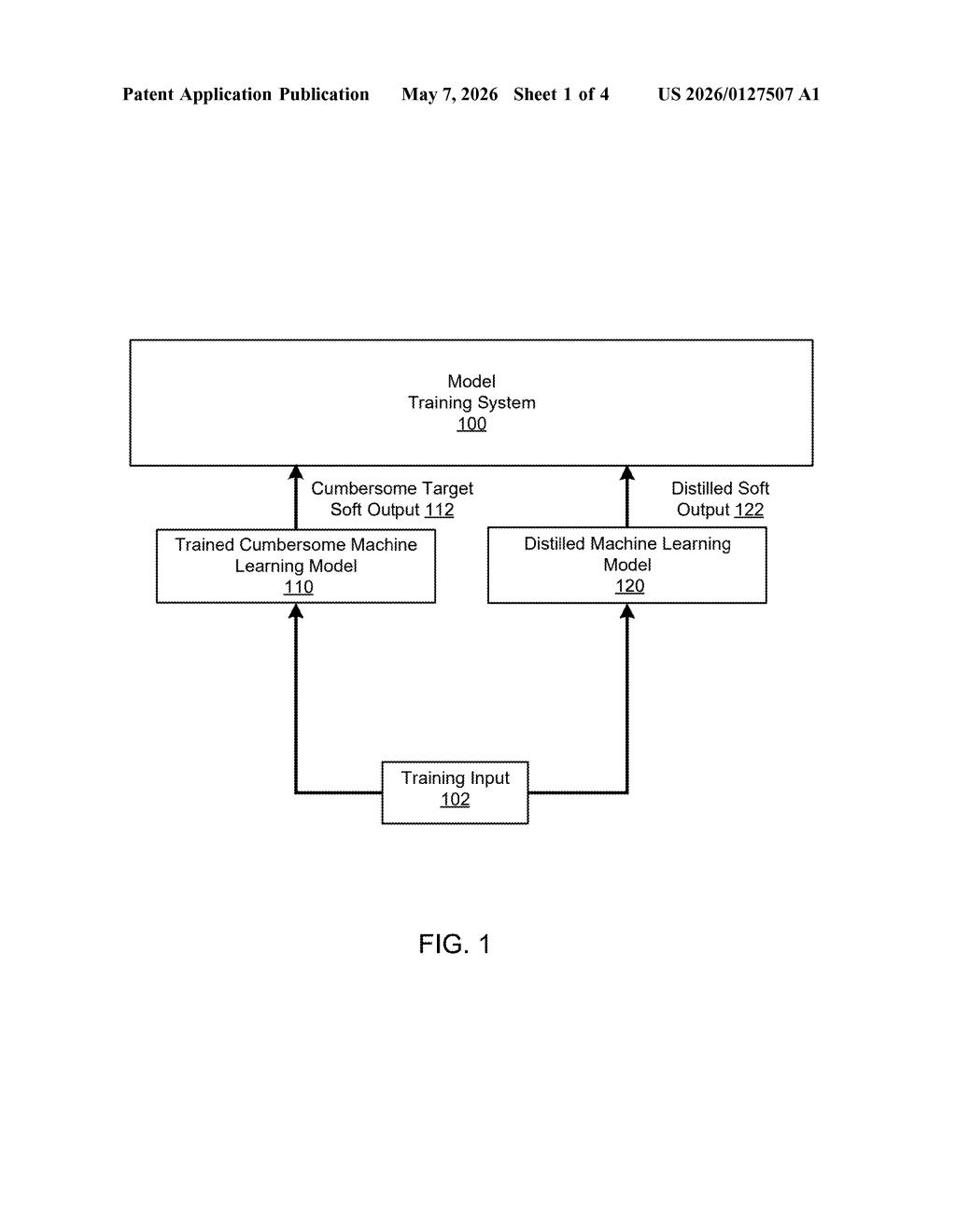
What Google's teacher-student model compression actually does
Imagine you want to teach a student by having them learn from a world-class expert, not just memorize the right answers from a textbook. That's exactly the idea here. Google's patent describes training a small, efficient AI model (the "student") by having it mimic a much larger, more capable model (the "teacher") — rather than just copying the original training data.
The trick is in what the student copies. Instead of learning only the final answer ("this image is a cat"), the student learns the teacher's full distribution of guesses — like "60% cat, 30% dog, 10% fox." That richer signal gives the student far more information to learn from.
The result: you get a compact model that punches above its weight, cheap enough to run on a phone or an edge device, but trained on the nuanced judgment of a giant model. This technique is already widely used across the industry, which makes the timing of this patent filing... interesting.
How the temperature parameter softens the teacher's output
The patent describes a two-stage training pipeline built around a teacher-student framework.
First, a large "teacher" model is trained in the conventional way on labeled data. It learns to assign probability scores across many output classes — say, thousands of image categories or word tokens. The key move: the teacher's output layer uses a temperature parameter (think of it as a "softening" dial) that spreads out its probability estimates instead of collapsing them into one sharp winner. A high temperature makes the model say "I'm 40% sure it's a cat, 35% sure it's a dog" rather than just "cat: 99%." Those spread-out guesses are called soft targets.
Then, a much smaller "student" model is trained to reproduce those soft targets — not just the hard correct labels. The student's objective function (the mathematical score it's trying to minimize) includes a term that penalizes disagreement between its own score distribution and the teacher's.
The key components are:
- Temperature scaling — controls how "soft" the teacher's outputs are
- Soft target matching — the student learns from probability distributions, not just labels
- Combined objective — the loss function can blend soft-target learning with standard label-based learning
The practical payoff: the student model can be dramatically smaller and faster than the teacher while retaining much of its accuracy.
What this means for running AI models on cheaper hardware
Knowledge distillation is one of the most widely deployed techniques in production AI today. If you've ever used a fast on-device ML feature — voice recognition, autocorrect, real-time translation — there's a good chance a distilled model is doing the work. The cost of running giant models at scale is enormous, and distillation is one of the primary tools companies use to bring that cost down.
What's notable here is who is on this patent. Geoffrey Hinton, Jeff Dean, and Oriol Vinyals are not filing routine infrastructure patents. Hinton co-authored the seminal 2015 paper that popularized this exact method. Google formally patenting it now — a decade later — raises eyebrows. Whether this is a defensive move, a licensing play, or just housekeeping, the AI industry will be paying attention.
This is one of the most significant foundational techniques in modern AI being formally patented by the people who arguably popularized it. The 10-year gap between the influential 2015 Hinton/Vinyals/Dean paper and this filing is conspicuous, and the industry should watch how Google chooses to enforce or license it. This isn't boring — it's potentially a very big deal for anyone training or deploying ML models at scale.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.