Google Patents a Diffusion-Based System for Labeling Every Pixel in Images and Video
Google is applying the same generative AI technology behind image synthesis tools to one of computer vision's hardest problems — identifying and tracking every single object in a scene, pixel by pixel, across entire videos.
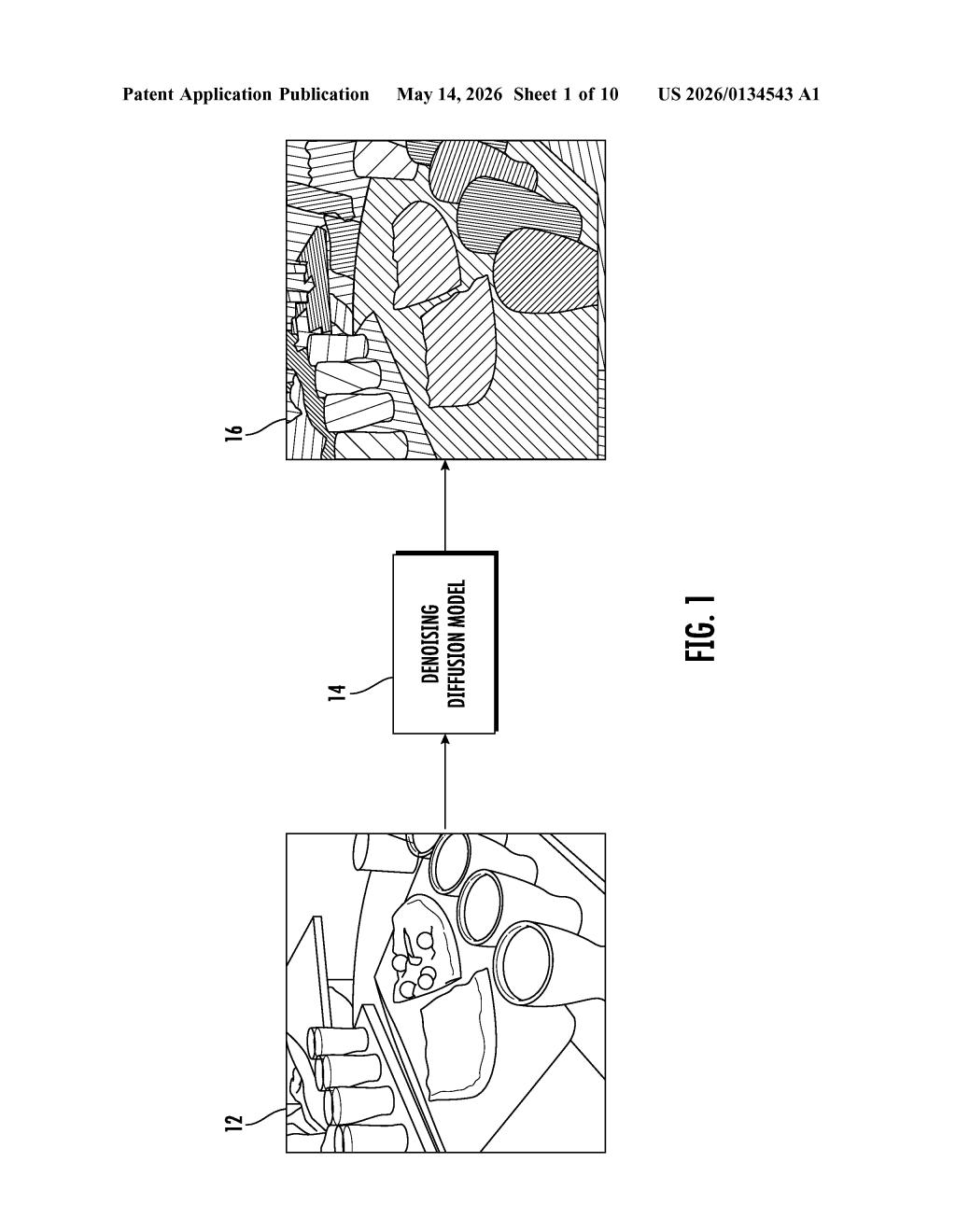
What Google's pixel-labeling diffusion model actually does
Imagine watching a busy street video and wanting a computer to tell you not just "there's a car" but exactly which pixels belong to which specific car — and to keep tracking that same car as it moves through every frame. That's a task called panoptic segmentation, and it's genuinely hard.
Google's patent describes a way to solve it using a denoising diffusion model — the same class of AI that powers image generators like Stable Diffusion. Instead of generating a pretty picture, the model generates a detailed map that assigns every pixel in your image a label ("road," "pedestrian") and an individual ID ("pedestrian #3," "car #7").
For video, the system uses predictions from earlier frames as extra context, so the model naturally learns to follow objects over time without any special tracking code bolted on. It's a single, unified approach to a problem that usually requires several separate tools working together.
How the denoising diffusion model generates panoptic masks
Panoptic segmentation combines two related tasks: semantic segmentation (what category does this pixel belong to — sky, road, person?) and instance segmentation (which specific individual does this pixel belong to — person #1 vs. person #2?). Most prior systems tackle these separately and merge the results, which introduces errors.
Google's approach reframes the whole problem as a conditional discrete data generation task — meaning the model learns to "generate" a correct segmentation mask the same way a diffusion model generates an image, by iteratively refining noisy guesses until it produces a clean answer. The mask is represented as an array of discrete tokens (think of it like a grid of category codes), conditioned on the input image.
For video, the patent adds a clever twist: predictions from previous frames are fed in as an additional conditioning signal. This means the model implicitly learns object tracking — it sees where objects were in the last frame and uses that as a prior when segmenting the current one. No separate tracking module required.
- Input: a single image or video frame
- Process: iterative denoising diffusion over a discrete token mask
- Output: a panoptic mask with per-pixel semantic and instance IDs
- Video extension: prior-frame predictions used as conditioning
What this means for AI video understanding at Google
Panoptic segmentation is a foundational capability for anything that needs to understand a scene in detail — autonomous driving, robotics, augmented reality, and video search. Using a single generalist diffusion model instead of a patchwork of specialized systems could make these pipelines simpler, more accurate, and easier to scale across new domains.
For Google specifically, this kind of technology feeds directly into products like Google Maps, YouTube video understanding, and the visual perception stack for Waymo. The fact that Geoffrey Hinton — one of the original "godfathers of deep learning" — is listed as a co-inventor signals this is serious research, not a routine filing. A unified model that handles still images and video tracking in one shot is exactly the kind of architectural simplification that tends to age well.
This is a genuinely interesting research patent, not an incremental tweak. Reformulating panoptic segmentation as a diffusion generation problem is a principled architectural bet — it trades the complexity of multi-module pipelines for the generalization power of a single trained model. Geoffrey Hinton's presence on the inventors list alone makes it worth reading the full paper when it surfaces.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.