Nvidia Patents a Two-Stage Neural Network System for Audio Noise Removal
Noise-cancellation systems have a dirty secret: when they're aggressive enough to kill background noise, they sometimes delete bits of your voice too. Nvidia's new patent uses a second neural network specifically to recover the speech that the first one accidentally erased.
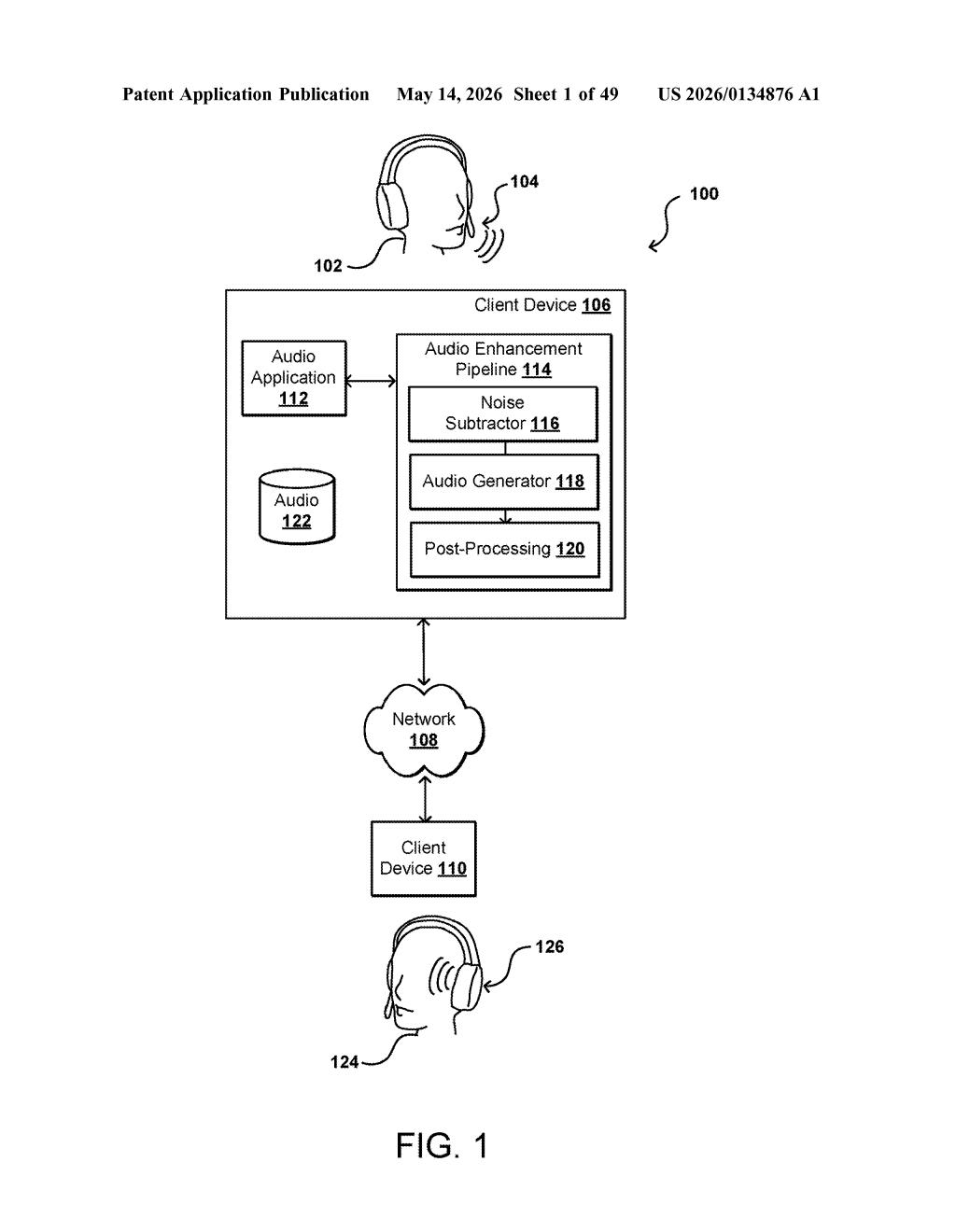
How Nvidia's dual-network audio cleaner recovers lost speech
Imagine you're on a video call and your microphone picks up a loud fan, street traffic, and your own voice all at once. A noise-cancellation system tries to strip away everything that isn't speech — but when noise and voice overlap in the same frequencies, the cleaner can accidentally chop off parts of what you're saying, making you sound clipped or robotic.
Nvidia's patent tackles this with a two-step approach. The first neural network does the heavy lifting: it filters out background and foreground noise from the raw audio signal. But instead of stopping there, a second neural network reviews what was removed and tries to reconstruct any speech that got caught in the crossfire.
The recovered speech fragments are then blended back into the cleaned audio, so the output sounds more complete and natural. Think of it like a spell-checker that runs after autocorrect — catching the mistakes the first pass introduced.
How the second network reconstructs deleted speech fragments
The system is built around a sequence of neural networks working in pipeline fashion on incoming digital audio. The first network — acting as a noise subtractor — processes the raw input signal and produces a filtered version with both background noise (like air conditioning or ambient room sound) and foreground noise (like a barking dog or a nearby conversation) stripped out.
The critical insight is what happens next. Rather than treating the filtered signal as the final product, a second neural network performs inference (meaning it makes probabilistic predictions) on the portions of the audio that were removed by the first network. Its job is to identify whether any of that discarded audio contained legitimate speech fragments that got caught up in the noise removal pass.
If the second network finds such fragments, the system reintegrates those inferred speech segments back into the cleaned audio stream. A downstream audio generator stage then handles any additional enhancement or restoration of the primary audio signal before producing the final output.
The architecture is described as supporting a full pipeline:
- Input raw audio with mixed noise and speech
- First network removes background and foreground noise
- Second network infers and recovers lost speech from the discarded portion
- Audio generator enhances the recombined signal
- Clean, restored audio is output
What this means for real-time voice and conferencing tools
For anyone who uses video conferencing, voice assistants, or real-time communication tools, aggressive noise cancellation has always come with a trade-off: the better it is at killing noise, the more likely it is to mangle your speech. Nvidia's approach — using a dedicated recovery network to audit what was thrown away — directly addresses that compromise without forcing a softer noise filter.
Nvidia already ships its RTX Voice and Broadcast software, which use GPU-accelerated noise suppression. A patent like this fits squarely into that product line and could also apply to cloud-based conferencing infrastructure or on-device voice processing in consumer hardware. The filing dates back to a 2019 original application, meaning this technology has been in development for years.
This is a genuinely clever architectural move: instead of trying to build a single perfect noise filter, Nvidia separates the problem into 'remove noise' and 'recover collateral damage' — two tasks that different networks can specialize in. The 2019 original filing means this has likely already shaped real products. Worth paying attention to if you follow audio AI or the competitive noise-cancellation space.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.