Google Patents a Learnable Sparsity Mask Technique for Efficient ML Models
Most AI models carry a lot of dead weight — literally. Google's new patent describes a way to teach a model, during training, to figure out which of its own parameters it doesn't actually need.
How Google trains leaner AI models without losing accuracy
Imagine a library where 80% of the books are never checked out. You could save a lot of shelf space — and find things faster — if you just removed the ones nobody uses. Neural networks have the same problem: they're full of numerical values called weights that contribute almost nothing to the final answer.
Google's patent tackles this by adding a second layer of learnable values called mask weights. During training, the system figures out which model weights are worth keeping and which can be zeroed out — that's the sparsity mask. Instead of guessing upfront which weights to prune, the model learns on its own which ones matter.
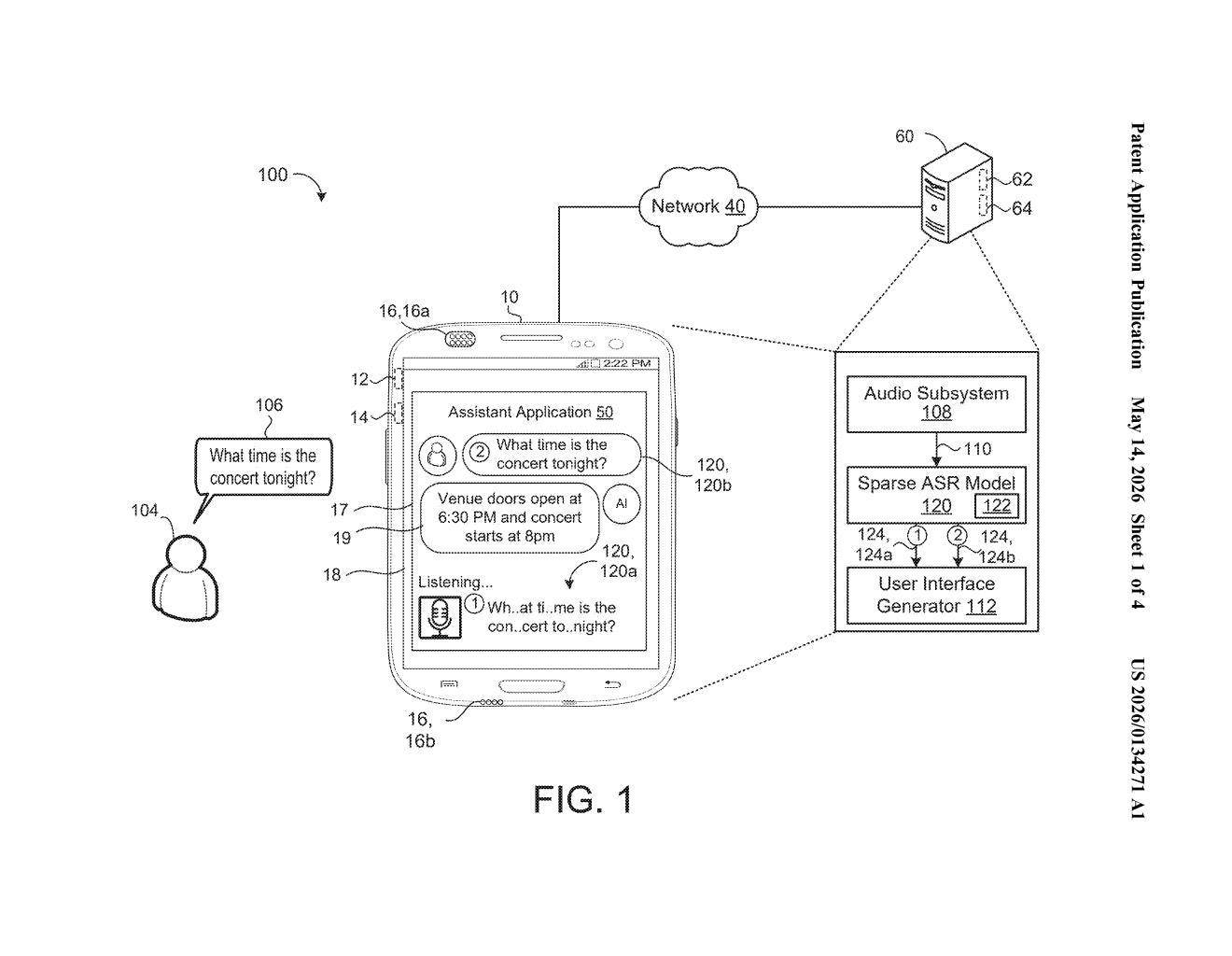
The practical payoff is a sparse model — one that's smaller, faster, and cheaper to run, especially on devices with limited memory and battery. The abstract specifically mentions a sparse ASR (automatic speech recognition) model, so this looks aimed squarely at making voice AI run better on phones and smart devices.
How the sparsity mask and Top-K estimator work together
The patent describes a training procedure with two interleaved sets of learnable parameters: the standard model weights (the numbers that define what the neural network knows) and a new set of mask weights (numbers that determine which model weights get used at all).
Here's the loop:
- A sparsity mask is derived from the mask weights — think of it as a binary on/off switch for each model weight.
- The mask is applied to the model weights, producing masked model weights where zeroed-out parameters don't contribute to computation.
- The masked model processes each training example and generates a prediction.
- A loss (a measure of how wrong the prediction was) is calculated against the known correct answer.
- Both the model weights and the mask weights are updated via backpropagation (the standard gradient-descent feedback loop).
The key insight is that the mask isn't fixed before training — it's learned jointly with the model itself. The title references a Top-K estimator, a technique for approximating which weights rank in the top-K most important ones in a differentiable way (meaning gradients can flow through the selection process, which normally would be a non-differentiable hard cutoff).
The filing's figures reference a sparse ASR (automatic speech recognition) model inside an audio subsystem, suggesting the primary application is compressing speech-recognition models for edge deployment.
What this means for on-device speech and AI inference
On-device AI is only as good as how much you can cram into a phone's memory and power budget. Sparse models — ones where large fractions of weights are exactly zero — run faster on modern hardware accelerators that are specifically designed to skip zero-multiplications. Google's approach makes the sparsity itself a learned outcome rather than a post-hoc pruning step, which typically preserves more accuracy.
For you as a user, this is the kind of unglamorous plumbing that makes voice assistants respond faster offline, or makes Pixel's on-device speech recognition snappier without draining your battery. It's also a technique that, if it works well, could apply far beyond ASR — to any large model Google wants to shrink for deployment.
This is foundational ML efficiency work, not a flashy consumer feature — but it's exactly the kind of infrastructure patent that ends up quietly shipping in Google's on-device AI stack. The Top-K estimator trick for making discrete masking differentiable is a genuinely interesting research contribution, and the explicit ASR reference in the filing suggests this isn't purely theoretical.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.