Intel Patents a Faster Way to Track Which CPU Cores Still Have Room
Scheduling work across dozens of CPU cores sounds simple — until you have to do it thousands of times per second without bottlenecks. Intel's new patent describes a smarter bookkeeping system that tracks resource usage at every level of a processor hierarchy simultaneously.
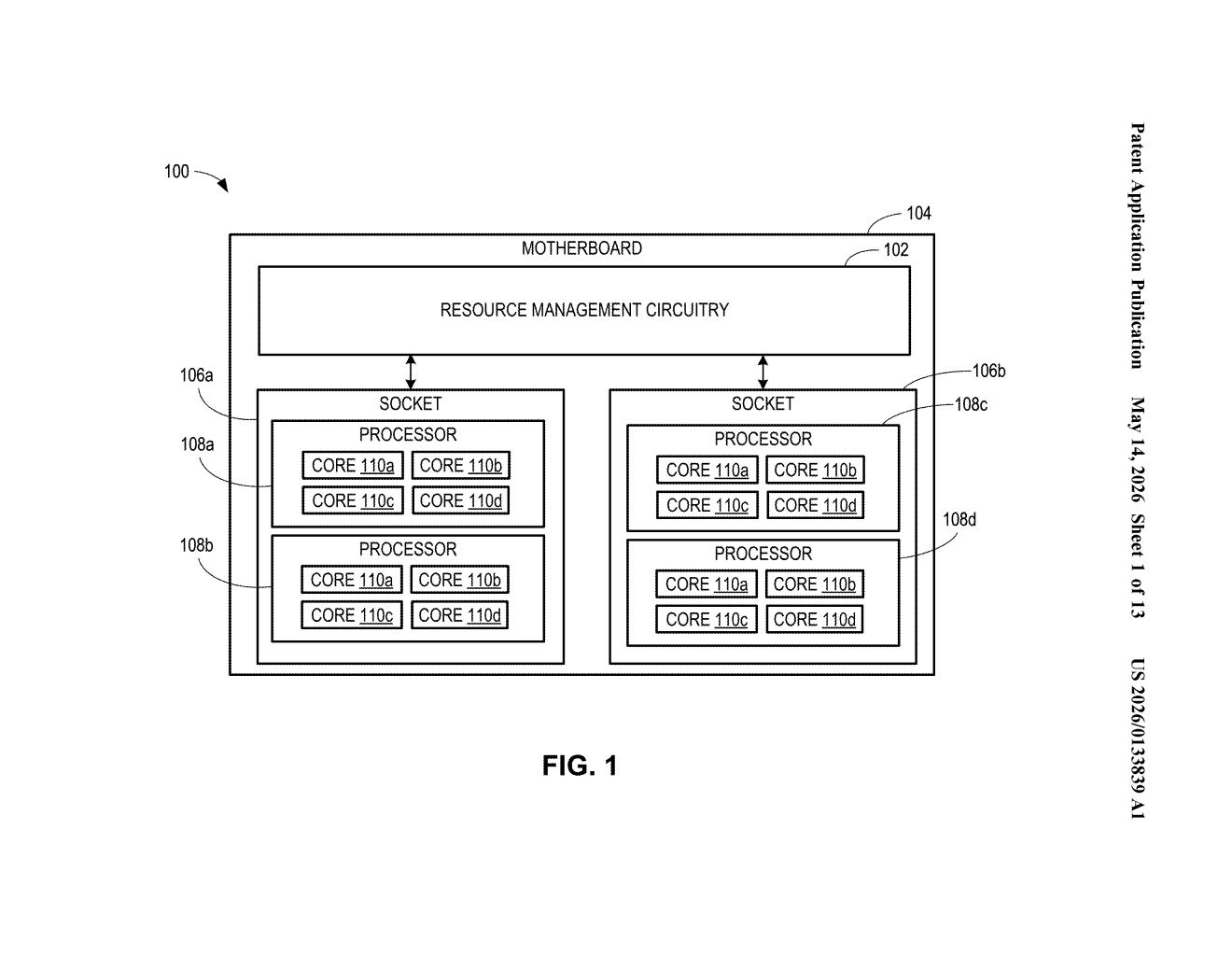
How Intel's tree-based CPU tracking actually works
Imagine a busy office building where you need to find an available conference room. You could check every single room one by one, or you could check a board at each floor that summarizes which floors still have open rooms, and only drill down where there's capacity. Intel's patent applies that same idea to CPU scheduling.
When your computer needs to assign a task to a processor core, something has to decide which core gets it — and keep track of how loaded each core, each socket, and the whole system is at once. That bookkeeping is harder than it sounds at scale.
Intel's approach uses a tree-shaped data structure where each node tracks its own utilization and rolls up a summary for its parent. When a task gets assigned anywhere in the tree, counters update at the child level, the middle level, and the root level — all in one pass. This means the scheduler always has a fast, accurate picture of the whole system without scanning every core individually.
Inside Intel's node counter update chain
The patent describes a resource management system built around a three-level hierarchy: a root node (representing the whole system or motherboard), intermediate nodes (representing sockets or NUMA regions), and child nodes (representing individual processor cores).
Each node carries two counters:
- A local utilization counter — tracking resources directly assigned to that node
- A sub-node utilization counter — a rolled-up summary of all utilization below it in the tree
When a new request (a task or thread) arrives, the scheduler first checks whether any intermediate node under the root can satisfy it. If yes, the task is assigned and both the root's local counter and the relevant intermediate node's counter are updated immediately. A second, more granular request then checks whether a specific child node (a core) can satisfy the work — and if so, updates the child's counter, the intermediate node's sub-node counter, and the root's sub-node counter in sequence.
This cascading update model means the system never needs a separate pass to reconcile totals. Every level of the hierarchy stays current after each assignment, which keeps scheduling decisions fast and consistent even across large multi-socket server configurations.
What this means for multi-socket server scheduling
In modern servers with dozens of cores spread across multiple sockets, the overhead of tracking what's busy can itself become a performance bottleneck. A scheduler that has to scan every core to find a free one doesn't scale — you want it to make that decision in microseconds, not milliseconds.
Intel's hierarchical counter approach is squarely aimed at high-core-count workloads — think cloud VMs, HPC clusters, or heavily threaded data-center applications running on Xeon-class hardware. By keeping pre-aggregated utilization summaries at every level of the tree, the scheduler can prune its search quickly, which reduces contention and latency when thousands of tasks are being dispatched per second.
This is classic Intel infrastructure work — unglamorous, but the kind of thing that quietly determines whether a 128-core server scheduler is fast or frustratingly slow. It's not a headline feature, but accurate hierarchical resource tracking is foundational to everything from thread pinning to NUMA-aware memory allocation. Worth paying attention to if you care about what's happening under the hood in Intel's next-gen server software stack.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.