Intel Patents an AI That Keeps Correcting Its Own Read of Your Body in 3D
Getting a computer to understand where your limbs are in 3D space from a single flat photo is surprisingly hard — and Intel thinks it has a smarter way to do it by repeatedly measuring and fixing its own mistakes.
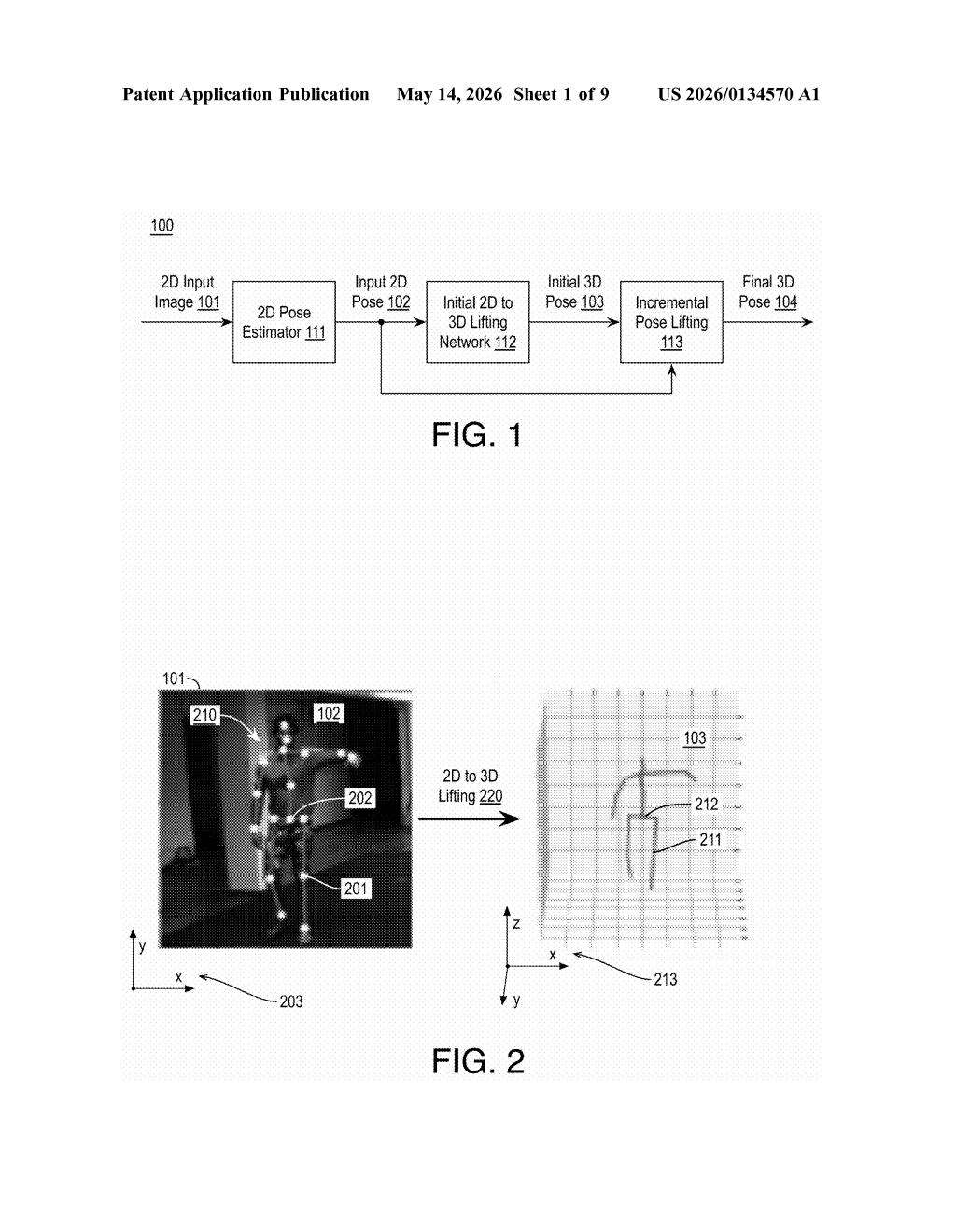
How Intel turns a flat photo into a 3D body position
Imagine you take a photo of someone doing a yoga pose. A computer tries to figure out not just where their arms and legs appear on screen, but exactly where they are in 3D space — how far forward that elbow is reaching, how the torso is twisted. That's human pose estimation, and it's trickier than it sounds because a flat image throws away a lot of depth information.
Intel's patent describes a system that makes an initial 3D guess, then checks its own work. It re-projects that 3D guess back down to 2D (like flattening it back onto paper) and measures how far off it is from the original detected 2D pose. That gap — the error — becomes the input for a second model that figures out exactly how to nudge the 3D estimate to be more accurate.
You keep iterating: guess, re-project, measure the gap, correct. Each pass brings the 3D pose closer to reality without having to re-run the expensive initial model. The result is a system that's both faster and more precise than doing a single heavy computation up front.
How the residual regressor closes the 2D-to-3D gap
The system works in two stages. First, a lifting network (a neural network that converts 2D joint positions to 3D coordinates) generates an initial rough 3D pose from the 2D keypoints detected in the image — things like wrist, elbow, shoulder, and hip positions.
Then comes the refinement loop. The current 3D pose estimate is re-projected back into 2D coordinates using a mathematical projection — think of shining a light through a 3D wireframe figure to cast a flat shadow. The system then computes the difference between that projected shadow and the original 2D pose detected in the image. This difference is the residual error.
A lightweight residual regressor (a model specifically trained to predict corrections rather than full outputs) takes that error signal as input and outputs a 3D pose increment — a small adjustment vector for each joint. That increment is added to the current 3D estimate, producing a better one.
- Initial 3D pose from lifting network
- Re-project to 2D, compute gap vs. detected 2D pose
- Run residual regressor on the gap to get a 3D correction
- Add correction to current estimate; repeat as needed
Because the corrective model only needs to learn small adjustments rather than the full 2D-to-3D mapping, it can be much smaller and faster than the original lifting network.
What this means for AR, gaming, and on-device AI
Human pose estimation is a core building block for augmented reality, fitness tracking apps, motion capture, sports analytics, and even safety systems that detect whether a person has fallen. The accuracy-vs-speed tradeoff has always been painful: heavier models are more accurate but too slow for real-time use on edge devices like phones or smart cameras.
Intel's incremental correction approach is architecturally elegant because it decouples the hard initial lift from the refinement. That means you could run the expensive lifting network once and then use a much lighter corrective loop to polish the result — potentially making high-accuracy 3D pose estimation viable on lower-power hardware, which matters a lot for wearables, robotics, and always-on computer vision at the edge.
This is solid, focused computer vision research with clear engineering value. The idea of iterative self-correction through residual regression isn't new in deep learning broadly, but applying it specifically to the 2D-3D lifting problem — and doing it incrementally rather than end-to-end — is a pragmatic improvement that could meaningfully reduce compute costs in real deployments. It won't make headlines, but it's the kind of patent that quietly ends up inside Intel's OpenVINO or AI PC toolkits.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.