Adobe Patents a Two-Tier Knowledge Graph System for Focused AI Answers
Before a generative AI model even tries to answer your question, it needs to know where to look. Adobe's new patent proposes a two-level knowledge graph system that first figures out which data source is relevant, then dives into that source's own graph to find the right details — rather than searching everything at once.
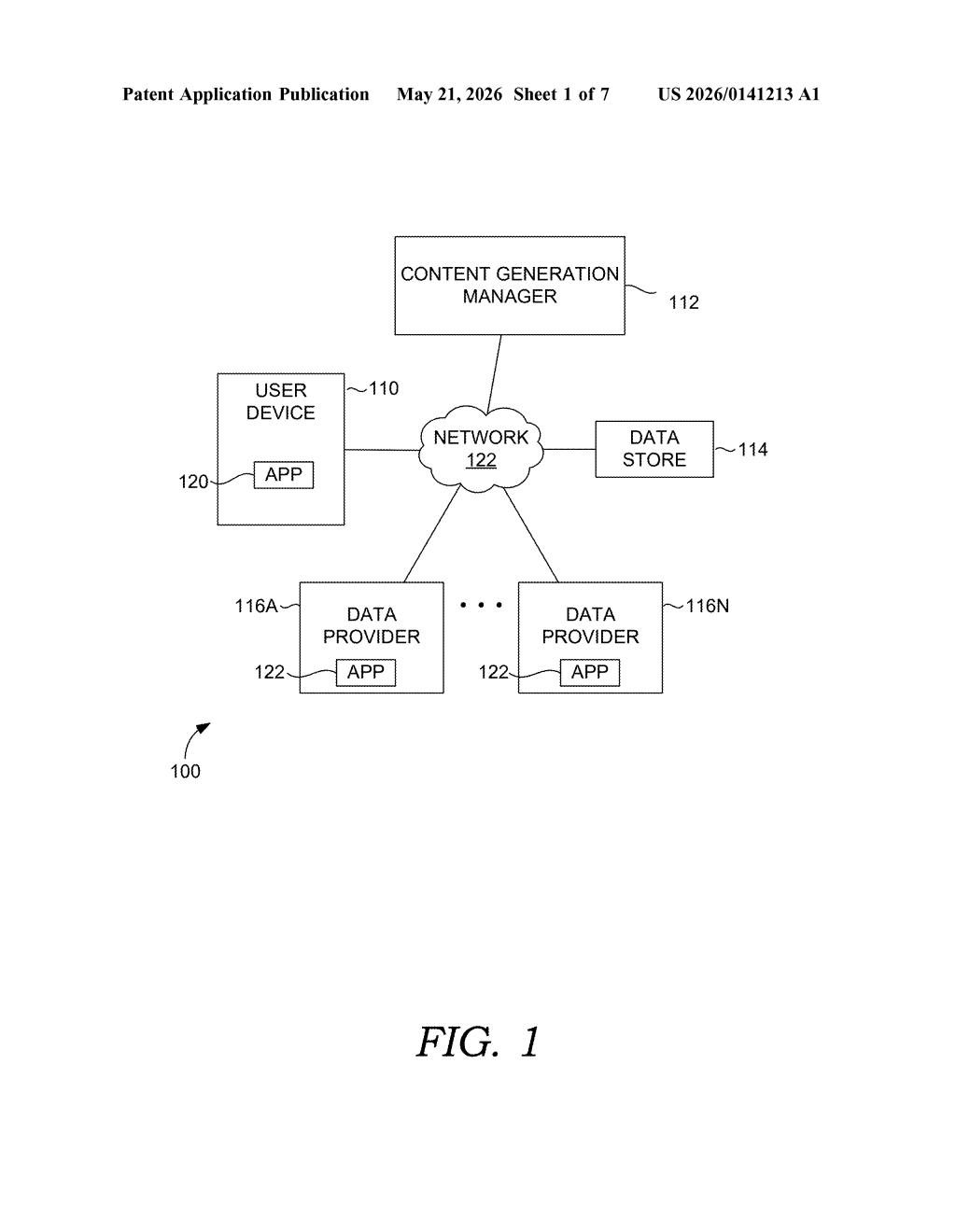
How Adobe's layered knowledge graphs narrow AI searches
Imagine asking your company's AI assistant a question about last quarter's marketing spend. Instead of rummaging through every database your company owns — product catalogs, HR files, legal docs — a well-organized system would first figure out "this is a finance question," then go straight to the finance data to find a real answer.
That's essentially what Adobe's patent describes. There's a high-level "root" knowledge graph that acts like a table of contents: it figures out which data source is relevant to your question. Then a second, more detailed "data" knowledge graph for that specific source is used to pinpoint the exact information needed.
The result gets handed to a generative AI model, which uses both your original question and those relevant data points to write a response — displayed right in a graphical interface. It's a structured take on retrieval-augmented generation (RAG), the approach where AI answers are grounded in real data rather than just the model's training.
How the root graph hands off to a data-specific graph
The patent describes a hierarchical retrieval pipeline with two distinct knowledge graph layers working in sequence.
Step one — the root knowledge graph: When a query arrives, a top-level graph (the "root") is consulted to identify which data source is most relevant. Think of this as a high-level ontology (a structured map of concepts and their relationships) that knows "this question is about invoices" or "this question is about customer churn" — without yet touching the actual data.
Step two — the data knowledge graph: Once the right data source is identified, a corresponding data knowledge graph — one of potentially many, each scoped to a specific source — is selected. This graph encodes the structure and relationships within that data source, enabling more precise retrieval of the relevant subset of records or content.
- The query and the retrieved data are then passed to one or more generative AI models to produce a synthesized response.
- That response is surfaced via a graphical user interface for the end user.
- The hierarchical design keeps each knowledge graph manageable in scope, rather than building one monolithic graph over all enterprise data.
This is Adobe's structured spin on RAG (retrieval-augmented generation) — the technique of grounding LLM outputs in retrieved documents — but with routing logic baked in at the graph level rather than relying solely on vector similarity search.
What this means for enterprise RAG and Adobe's AI tools
For enterprises with data scattered across dozens of systems — CRMs, asset libraries, analytics platforms — the hardest part of deploying AI assistants isn't the generation step, it's the retrieval step. Finding the right data fast, without noise from irrelevant sources, is what separates a useful AI tool from one that hallucinates or gives stale answers. Adobe's two-tier graph approach is a direct attempt to solve that routing problem at scale.
For Adobe specifically, this fits squarely into its push to make generative AI features in products like Experience Cloud actually trustworthy for business users. If your AI assistant can reliably route "what's our campaign performance?" to the right analytics data graph instead of guessing, that's a meaningful reliability improvement — and a competitive angle against generic LLM wrappers.
This is solid, unglamorous infrastructure work — the kind of retrieval-routing problem that every enterprise AI vendor is wrestling with right now. Adobe isn't claiming a fundamentally new idea here; hierarchical RAG and knowledge graph routing are active research areas. But filing a patent on a specific two-tier implementation signals that Adobe is building this into its platform products, not just experimenting in a lab.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.