Adobe Patents an AI That Builds Visual Scenes From Your Asset Library
Type a description of a scene, and Adobe's patented system pulls matching assets from your library and drops them into an AI-generated visual, automatically. Then you can keep editing it.
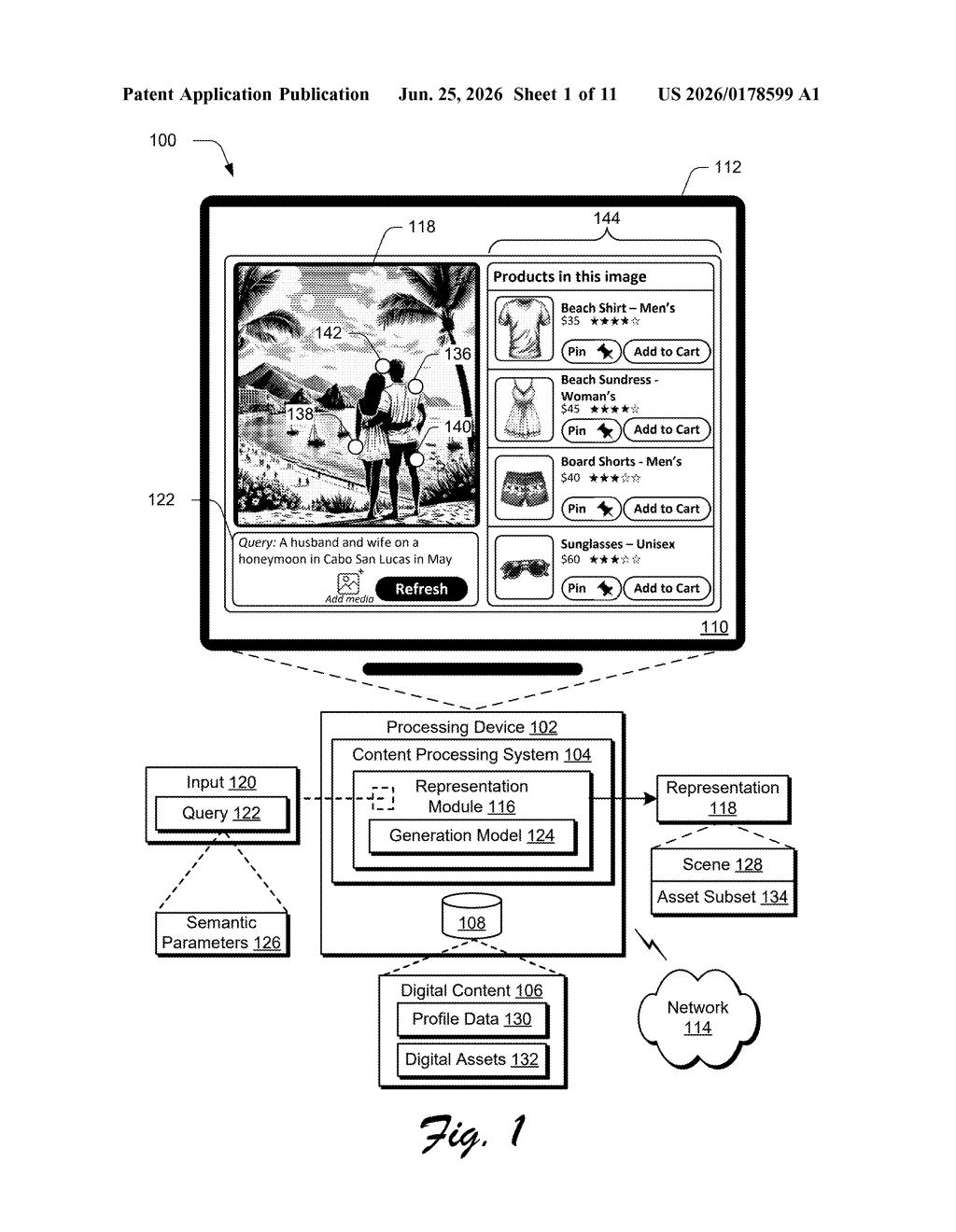
What Adobe's AI scene-builder actually does
Imagine you're a designer with hundreds of product photos, logos, and icons sitting in a folder. Instead of digging through all of them manually, you type something like "a cozy coffee shop with our branded mug on the counter" and the system finds the right assets and builds the scene for you.
That's the core idea in this Adobe patent. You describe what you want in plain language, the AI matches your words to files already stored in your library, then generates a composed visual with those specific assets placed inside the scene you described.
The system doesn't stop there. Once the image appears, you can interact with it, tweaking or adjusting, and it generates an updated version based on your changes. Think of it as a back-and-forth conversation with a design assistant that already knows your files.
How the system matches assets to your scene description
The patent describes a pipeline that connects natural-language input to an AI image-generation model, with a critical middle step: asset retrieval. When you submit a query, the system extracts semantic parameters (meaning: the concepts, context, and details your words imply) and uses those to search an asset database for relevant files.
Those matched assets are then packaged with a machine-learning prompt that instructs the model to generate an image incorporating those specific files into the described scene. The model doesn't just generate something generic; it's told to place your actual digital assets inside the output.
The interaction loop is the other notable piece. After the initial visual is generated, the system accepts follow-up inputs and produces updated versions, keeping the conversation going without starting from scratch. This is sometimes called an iterative refinement loop, common in newer AI tools but less common when tightly coupled to a private asset library.
The patent's claim is broad enough to cover text queries, though the multimodal framing suggests it could also accept image-based inputs alongside text.
What this means for designers using Adobe's tools
Adobe's existing tools like Firefly already let you generate images from text. What this patent adds is the asset-awareness layer: the AI works with your files, not just its training data. For brand teams and agencies, that's the meaningful gap. Generic AI generation is fast but often unusable in production because it doesn't know your logos, product shots, or style guides.
If this ships inside something like Adobe Express or Firefly for Enterprise, it could make compositing work significantly faster for non-designers. It also fits Adobe's broader push to position Creative Cloud as an AI-first platform rather than just a suite of manual tools.
This is a sensible, practical extension of what Firefly already does, not a dramatic leap. The asset-retrieval-plus-generation combo solves a real problem for brand and marketing teams who can't use generic AI output in professional work. Whether Adobe can execute the retrieval step accurately enough to be genuinely useful is the actual question, and the patent doesn't answer it.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.