Qualcomm's New Patent Pulls Motion Data from Inside Its Own Diffusion Model
Qualcomm is trying to extract motion data from a diffusion model's own internal steps — not as an afterthought, but as the core mechanism for generating coherent video.
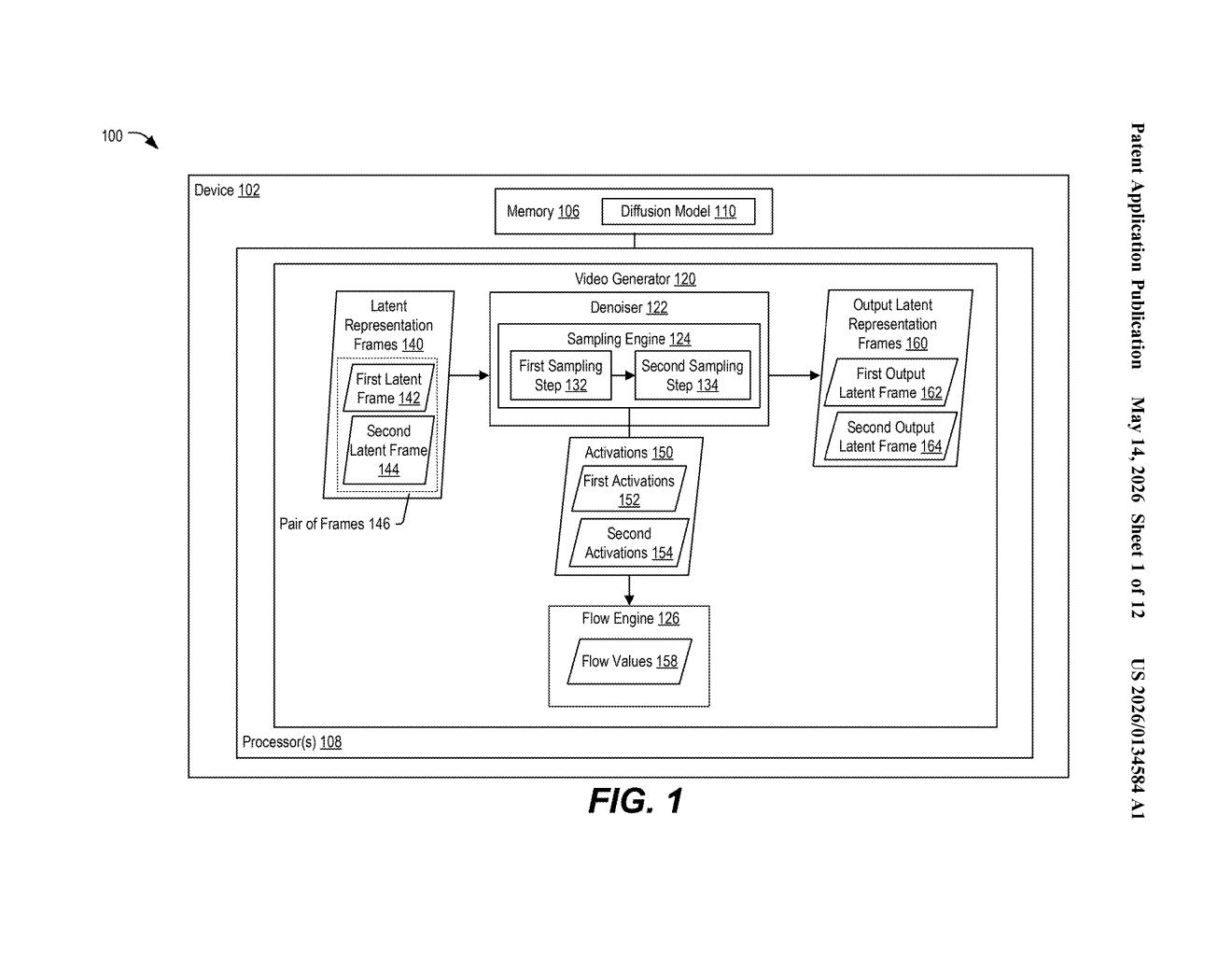
What Qualcomm's diffusion flow values do for video
Imagine you're watching a video that an AI generated, but the objects in it wobble or flicker between frames because the AI treated each frame almost independently. That's one of the central headaches in AI video today.
Qualcomm's patent describes a system that borrows a trick from the diffusion model itself — the same AI engine used to generate images — to figure out how things are moving between frames. Instead of bolting on a separate motion tracker, it watches what the diffusion model does internally as it processes pairs of frames, and pulls out flow values (basically a map of where pixels are going) from those operations.
Those flow values then feed a video generation step that can produce much more temporally consistent output — meaning objects stay coherent and motion looks smoother. It's a clever case of reusing computation you were already doing rather than adding a separate system.
How the denoiser's internals drive frame-to-frame motion
The patent describes a pipeline with three major components working together: a diffusion model (the image-generating neural network), a flow engine, and a video generator.
The process starts by taking multiple image frames and encoding them into latent representations — compressed numerical summaries that live in an abstract mathematical space rather than pixel space. Think of latents as a dense zip file that the neural network can manipulate directly.
The diffusion model then runs sampling operations on pairs of those latent frames. Diffusion sampling is the iterative denoising process (repeatedly removing noise from a signal) that turns a latent into a coherent output. Crucially, the patent's key insight is that the intermediate activations produced during those sampling steps already encode information about how content shifts between frames. The flow engine reads those activations and computes flow values — essentially optical-flow-like motion vectors (directional arrows saying "this pixel moved here") derived from the diffusion process itself rather than from a separate motion-estimation module.
- Latent frames are generated from input image frames
- Diffusion sampling runs on pairs of latent frames
- Intermediate activations from the denoiser are captured
- Flow values are derived from those activations
- Flow values guide the final video generation operation
What this means for on-device AI video generation
For Qualcomm, which designs the Snapdragon chips running in most Android flagship phones, this patent signals an interest in running on-device AI video generation efficiently. Extracting flow data from the diffusion process you're already running — rather than adding a separate optical flow network — means fewer redundant computations, which matters a lot on a mobile chip with tight power budgets.
More broadly, coherent video generation is one of the hardest open problems in generative AI right now. If reusing diffusion internals for motion estimation actually works well at scale, it's the kind of architectural shortcut that could meaningfully reduce the compute cost of models like those powering AI video tools — and make them feasible to run locally on your device rather than in the cloud.
This is a legitimately interesting architectural idea — using the diffusion model's own intermediate state as a motion estimator is elegant and compute-efficient. Whether it outperforms dedicated optical flow models in practice is an open empirical question, but the motivation is clear and the approach is non-obvious enough to be worth watching.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.