Samsung Patents a Central LLM That Delegates Tasks to On-Device Sub-Models
Samsung is patenting an AI architecture where a large 'orchestrator' model breaks down your requests into sub-tasks, farms them out to smaller specialized models on individual devices, and then stitches the results back into a single coherent answer.
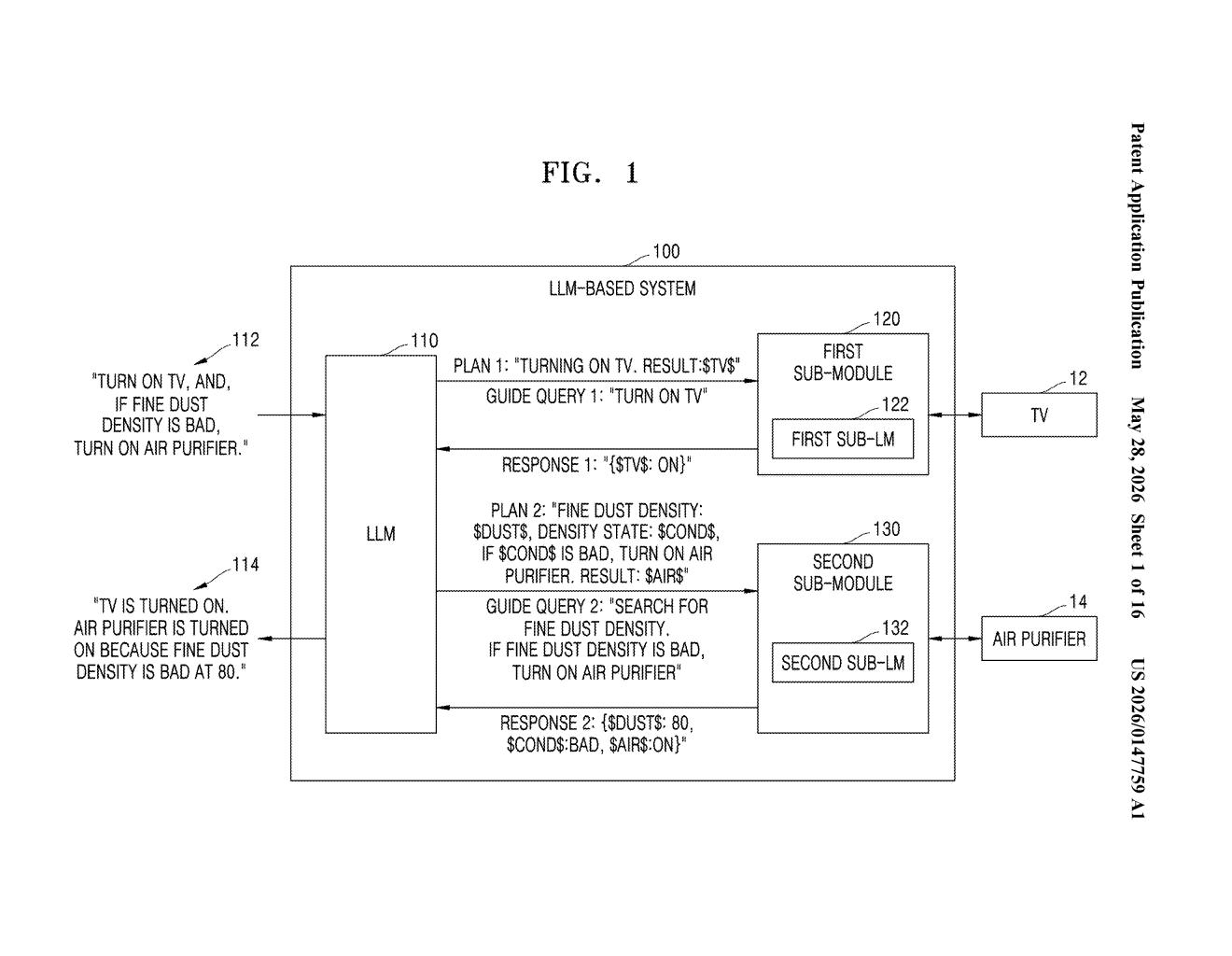
How Samsung's LLM boss-and-specialist system works
Imagine you tell your phone, "If the air quality is bad, turn on the air purifier; otherwise, turn on the TV." Today, making that kind of conditional, cross-device request work smoothly is tricky — your phone would need to understand home automation, sensor data, and natural language all at once.
Samsung's patent describes a smarter division of labor. A central large language model (LLM) acts like a project manager: it reads your request, writes a "plan" that contains blank slots for information it doesn't yet have, and sends those blanks to the right specialist models on the right devices. The TV's model fills in its blank; the air purifier's model fills in its blank.
Once all the blanks are filled in, the central LLM collects those answers and generates your final response. You ask one question, a whole ecosystem of AI models collaborates behind the scenes, and you get one clean answer back.
How the plan query and blank-filling mechanism operates
The patent describes a hierarchical query-processing pipeline with two tiers of AI models working together.
At the top sits a central LLM that receives your original input query. Rather than trying to answer everything itself, it generates what the patent calls a "plan query" — essentially a structured task plan that contains blank placeholders (e.g., $TV$, $AIR_PURIFIER$) representing values that need to be fetched from specialized sub-modules.
For each sub-module (think: a smaller, task-specific language model living on or near a particular device or service), the LLM sends three things:
- A request to fill in the blank values
- A relevant portion of the plan query so the sub-model understands the broader context
- A "guide query" — a focused re-framing of the original request scoped specifically to that sub-module's domain
Each sub-language model (sub-LM) processes its guide query in context and returns a response with the filled-in values. The central LLM then aggregates all those responses to produce the final answer. The architecture is explicitly designed to handle conditional logic ("if X, do Y; else do Z") across multiple devices or services.
What this means for Samsung's multi-device AI strategy
Samsung makes an enormous range of connected products — TVs, refrigerators, phones, air purifiers, washing machines — all under the SmartThings ecosystem. An orchestration layer like this would let a single natural-language request ripple intelligently across all of them without every device needing a full-scale LLM on board. Smaller, cheaper models on each device do the local work; one smart coordinator handles the reasoning.
This is also a direct play in the ongoing debate about on-device vs. cloud AI. By keeping sub-models local and only using the central LLM for planning and synthesis, Samsung could reduce latency, protect privacy, and cut cloud costs — all at once. Whether this shows up in Galaxy AI, SmartThings, or something new is an open question, but the architecture is clearly built with a heterogeneous device fleet in mind.
This is a genuinely interesting systems patent, not a trivial filing. The 'plan query with blank slots' idea is a clean formalization of LLM-as-orchestrator patterns that researchers have been exploring, and Samsung is one of the few companies with a hardware ecosystem diverse enough to actually need this at scale. The real test will be whether the sub-LM responses are reliable enough that the central model doesn't hallucinate when stitching them together — that's the hard unsolved problem here.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.