AI Patent Splits Video Content From Camera Motion Control
When you type a description into an AI video tool, the system has to figure out two very different things at once: what should appear on screen, and how the camera should move through the scene. Meta's new patent tries to handle those as separate problems.
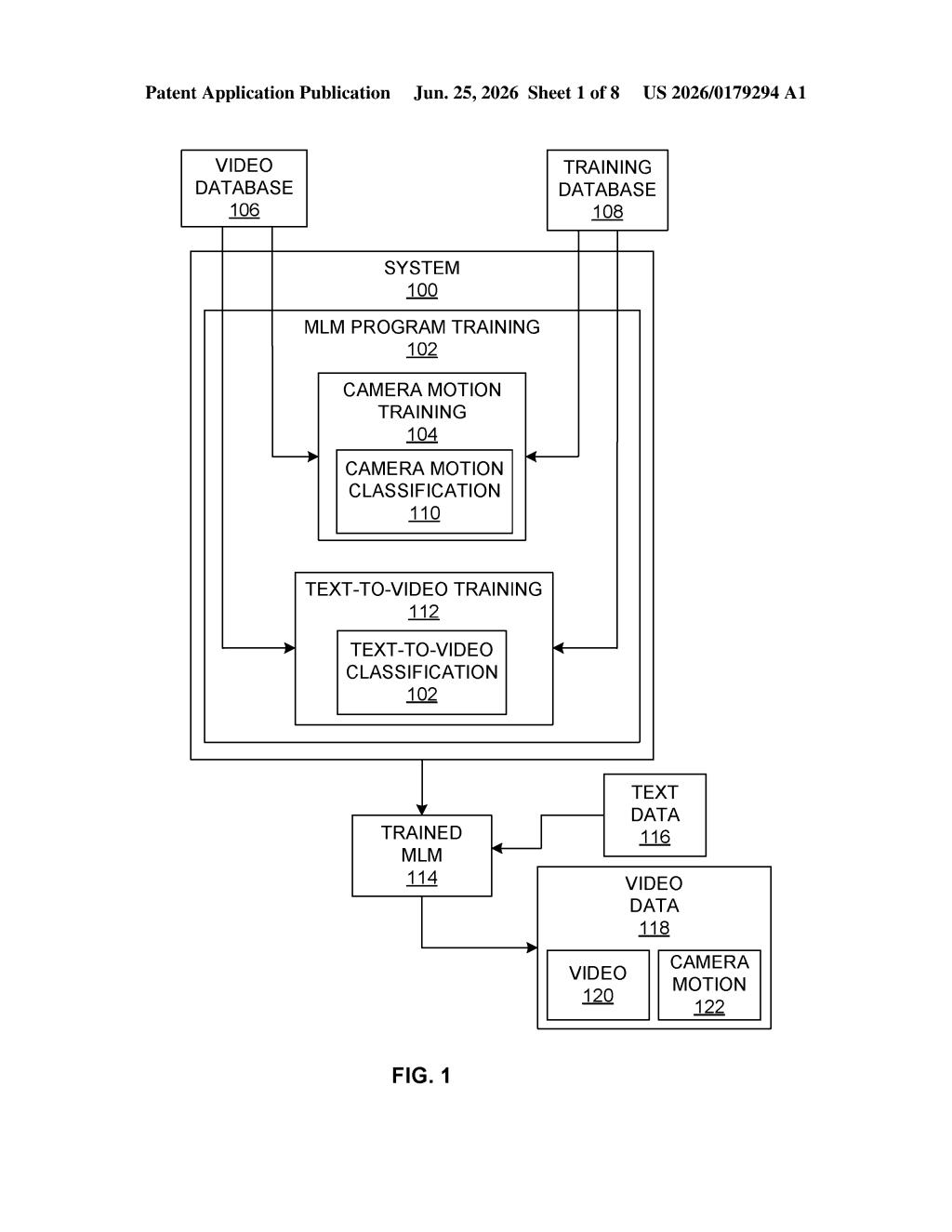
What Meta's text-to-video camera control actually does
Imagine typing 'a drone flies over a sunlit beach' into an AI video tool. Right now, most systems treat that whole sentence as one blob of instructions. The result can be inconsistent: the beach looks great, but the camera movement feels random or wrong.
Meta's patent describes a system that reads your text and automatically splits it into two distinct jobs. One part figures out what the video should show, the other figures out how the camera should move through that scene, things like panning left, zooming in, or holding steady.
The system learns these two skills separately by training on thousands of video clips, each labeled with descriptions of their camera movements. The idea is that if an AI knows 'this clip is a slow pan right' and 'this clip is a static overhead shot,' it can learn to apply that knowledge whenever your prompt implies a certain camera style, without you having to spell it out technically.
How one text prompt splits into two AI instructions
The patent describes a machine learning model trained on two types of data simultaneously: video clips and labels that describe the camera motion in each clip (think: 'zoom in,' 'tracking shot,' 'static wide angle').
When a user submits a text string (a plain-language description of a video), the model produces two separate outputs called prompts:
- A first prompt focused on the visual content of the video (what objects, scenes, and actions appear)
- A second prompt focused on the camera motion (how the virtual camera moves through or observes that scene)
The key insight is that these two prompts are derived from the same input text but optimized for different downstream tasks. By separating them, the system can apply camera motion logic more precisely than a single undivided prompt allows.
The training data includes labeled camera motion classifications, meaning the model learns associations between language patterns and specific cinematographic movements. When you write something like 'reveal the mountain slowly,' the model can infer a camera motion class without you naming it explicitly.
What this means for AI-generated video on Meta platforms
For people building AI video tools or using them creatively, camera control is one of the hardest things to get right. Most current text-to-video systems either ignore it or require very technical input. If Meta can make camera movement a first-class output derived automatically from natural language, the quality gap between AI video and real cinematography narrows considerably.
Meta runs several platforms (Instagram Reels, Facebook, and its generative AI products) where short-form video is central. A system that gives creators or automated tools finer control over how scenes feel, not just what they show, would be directly applicable to those products.
This is a focused, practical patent rather than a broad AI land-grab. Separating content generation from camera motion control is a genuinely useful architectural idea, and Meta filing it in late 2025 suggests they're actively building toward more cinematic AI video output. Whether the implementation delivers on the concept is a different question, but the problem being solved is real.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.