Microsoft's New Patent Teaches AI to Work Less Hard on Easy Tasks
What if an AI could tell when it's confused by incoming data — and automatically simplify its own internal math to compensate? That's the core idea in Microsoft's latest training patent.
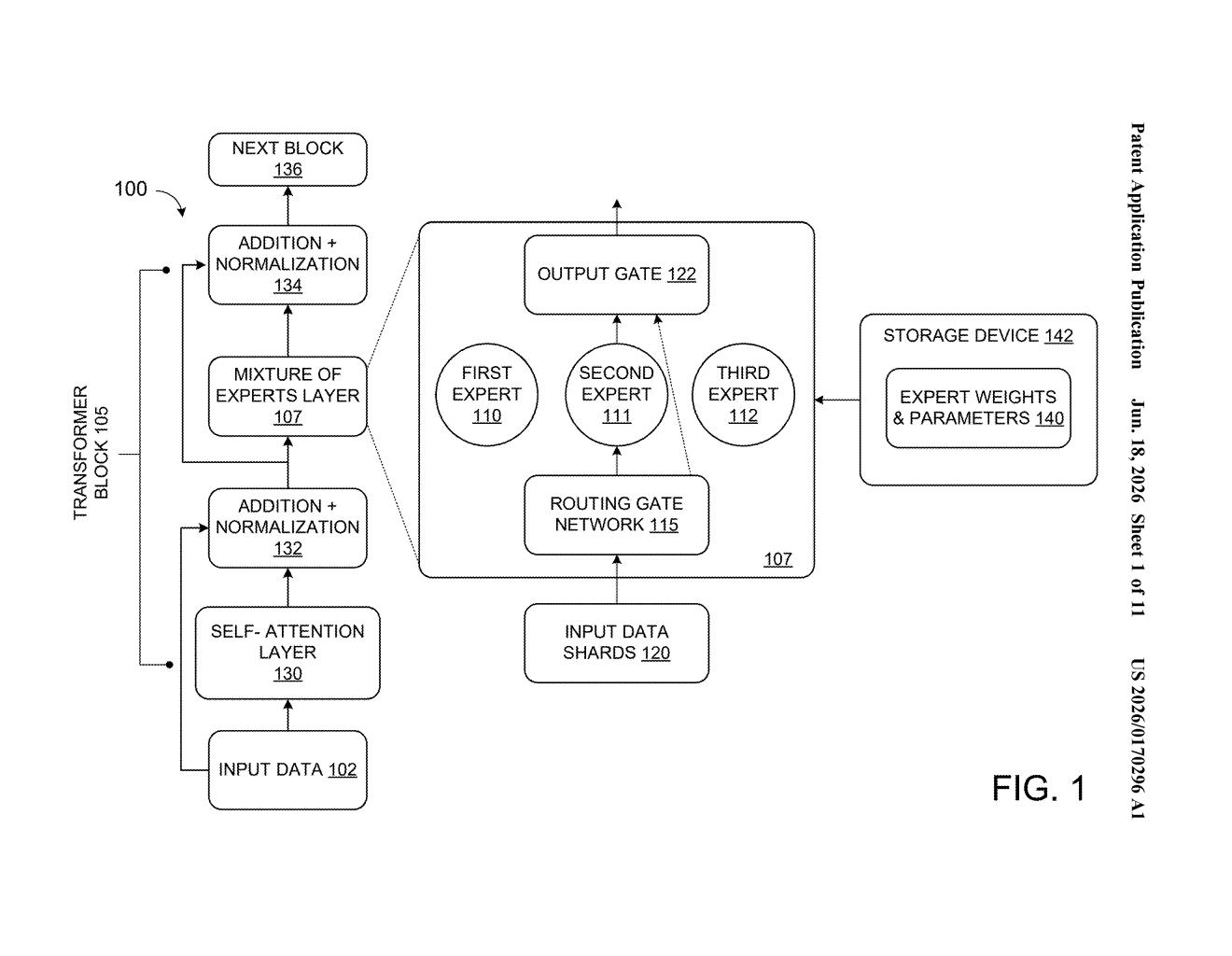
How Microsoft's perplexity-based AI training actually works
Imagine a student who breezes through easy homework with half their brain, but concentrates fully on the hard stuff. Microsoft's patent applies that same logic to AI training.
Large AI models like the ones powering chatbots are built from many layers of processing, each staffed by specialized sub-networks called "experts." This patent proposes measuring how confused — or "perplexed" — the model is by each chunk of incoming data. When the data is straightforward, the system uses a simpler, lighter version of the expert to process it. When the data is complex or unpredictable, it brings a fuller, more capable version to bear.
The result is a training process that wastes less computation on easy inputs and reserves heavy lifting for the inputs that actually need it. That's not just an academic nicety — it translates directly into faster training runs and, potentially, lower cloud computing bills for whoever is building the model.
How perplexity scores drive sparsity in the weight matrices
The patent describes a training method for a specific class of AI architecture called a Mixture of Experts (MoE) transformer — think of it as an AI where different specialist sub-networks (the "experts") handle different types of input, rather than one monolithic network handling everything.
The key innovation is an auxiliary classifier — a small side-module that measures perplexity (a statistical score for how surprising or unpredictable a given piece of data is to the model) after each layer processes the input. High perplexity means the model is struggling; low perplexity means the data is routine.
Based on that perplexity score, the system generates a sparsified weight matrix — essentially a version of the expert's internal math table with many values zeroed out. The higher the perplexity (harder input), the less sparsification is applied, preserving more of the expert's capacity. For easy inputs, more values are zeroed out, cutting computation. Training then runs the standard loop:
- Forward pass: the expert makes a prediction
- Backpropagation: the system calculates how wrong the prediction was
- Weight update: the sparse matrix is adjusted to reduce that error
This means the model is training on a dynamically-sized brain depending on how hard the question is.
What this means for the cost of running large AI models
Training large AI models is one of the most expensive computing operations on the planet. Anything that reduces unnecessary computation during training — without hurting accuracy — has real financial and environmental consequences. Microsoft, which has committed enormous resources to OpenAI and its own Copilot infrastructure, has a direct incentive to make model training cheaper and faster.
For you as a user, this kind of efficiency work is what eventually keeps AI products affordable and responsive. It also signals that Microsoft is thinking carefully about the architectural layer beneath the models — not just what the AI says, but how cheaply and quickly it learns to say it.
This is infrastructure work — not a flashy feature announcement — but it's exactly the kind of deep efficiency research that compounds over time. Microsoft is clearly trying to own the optimization layer of AI training, and a perplexity-guided sparsity mechanism is a concrete, defensible approach to doing that. Worth following if you care about where AI compute costs go in the next few years.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.