Microsoft Patents a Mixed-Precision Dot Product Pipeline for ML Training
Matrix multiplication is the heartbeat of every AI training run — and Microsoft is patenting a way to make the underlying arithmetic cheaper and faster by mixing number formats inside the same hardware pipeline.
What Microsoft's shared-exponent math trick actually does
Imagine you're doing a huge spreadsheet calculation where nearly every number in a column shares the same scale — like they're all in the range of thousandths. Instead of writing out the full scale for every single number, you write it once at the top of the column and only store the unique part for each entry. That's essentially what shared-exponent number formats do for AI math.
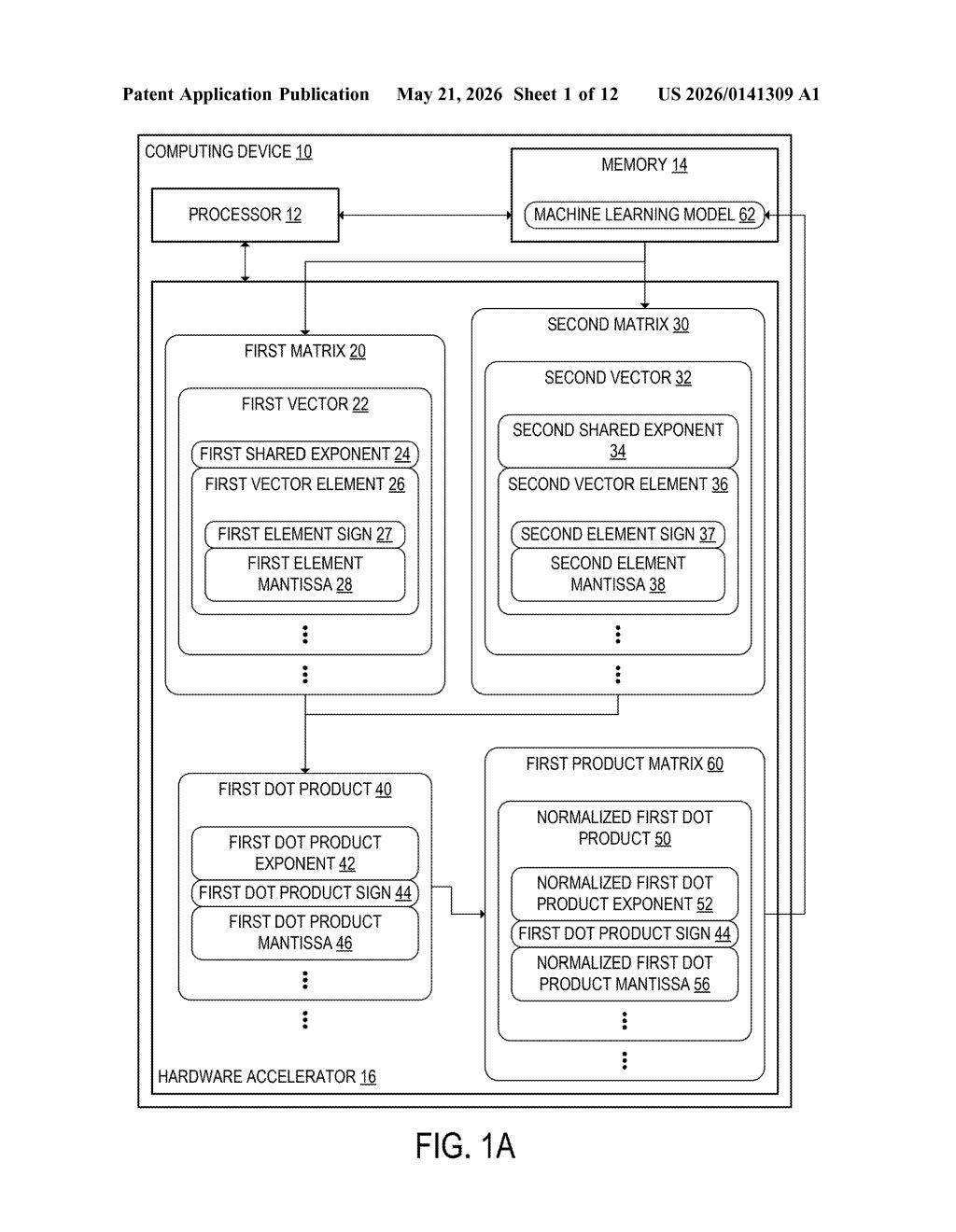
Microsoft's patent describes a hardware accelerator — think a specialized chip like a GPU or a custom AI processor — that trains machine learning models by chewing through enormous matrix multiplications. The key idea is that different stages in the chip's pipeline can use different number formats: some stages use the compact shared-exponent format, and others use a traditional format where each number carries its own scale. This lets the chip pick the right tool for each part of the job.
The practical payoff is that you can pack more numbers into memory and move them around faster when the shared format applies, without sacrificing precision in the stages where it matters more. It's a plumbing upgrade for the most expensive operation in AI training.
How the pipeline stages split shared vs. unshared exponents
The patent centers on a pipelined matrix multiplication accelerator — a chip design where several multiplier stages are wired in series, each crunching a different batch of matrix operations simultaneously (like an assembly line).
Each stage receives two matrices. The rows of one matrix and the columns of the other are organized as vectors with a shared exponent — meaning all elements in that vector share a single scale factor (the exponent), with each element only storing a sign bit and a mantissa (the significant digits). This is the Block Floating Point (BFP) or MX (Microscaling) number format family, which Microsoft has been actively involved in standardizing.
For each pair of vectors, the accelerator computes a dot product (multiply each element pair, sum them all up). The result is expressed as its own exponent, sign, and mantissa — a full floating-point-style output.
The critical architectural wrinkle: some pipeline stages run in shared-exponent mode (compact, fast, lower memory bandwidth) while other stages run in unshared-exponent mode (standard floats, more precise). This means the hardware can handle heterogeneous workloads — for example, forward passes in compressed format and gradient computations in full precision — without needing entirely separate hardware paths.
What this means for AI training chip efficiency
AI training is dominated by matrix multiplications, and the cost of those operations is largely determined by how many bits each number takes up. Shared-exponent formats like MX4 or MX6 can cut memory bandwidth and compute energy dramatically compared to FP16 or BF16 — but not every layer of a neural network tolerates the precision loss equally. A pipeline that can mix formats stage by stage is a meaningful architectural answer to that tension.
This patent sits squarely in the same space as AMD's and Nvidia's MX-format hardware support, and Microsoft's own Azure Maia AI accelerator program. If this design ships inside custom silicon for Azure, it could reduce the cost per training token — which at the scale Microsoft runs, translates directly to dollars. For you as a user, the downstream effect is faster or cheaper AI services.
This is a solid, specific chip-architecture patent rather than a broad land-grab. The insight — letting different pipeline stages use different number formats in the same multiply-accumulate hardware — is a real engineering tradeoff worth patenting. It's not flashy, but it's exactly the kind of work that determines whether your AI accelerator is competitive in two years.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.