New Search Index Patent Unifies Text and Image Queries
What if searching for a product photo and typing its name returned the exact same result — not just similar results, but the identical match? That's the core idea behind Microsoft's latest search patent.
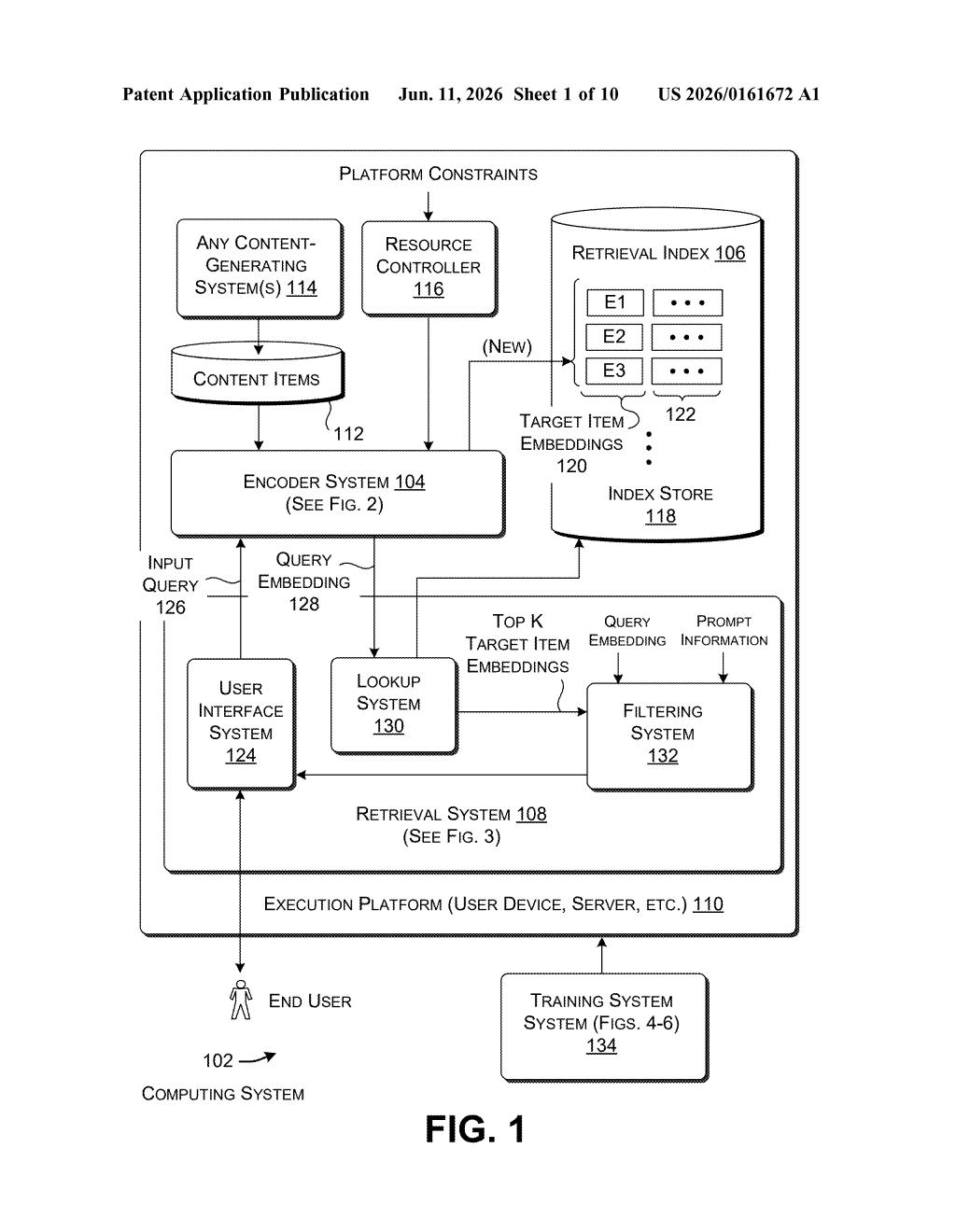
How Microsoft's unified search index actually works
Imagine you're looking for a specific piece of office furniture. You could type 'ergonomic standing desk,' snap a photo of one you like, or describe its color and dimensions — and a truly great search system would recognize that all of those are asking for the same thing. Today, most search engines treat a photo and a text description as fundamentally different inputs, which means you often get different results depending on how you ask.
Microsoft's patent describes a system that converts any form of input — text, images, or a mix of both — into a single, consistent representation stored in a search index. No matter how you phrase your query or what type of media you attach, the system maps everything to the same underlying point in its index.
The clever twist is that the most expensive part of this system — the large language model at its core — is kept frozen during training. Only the lighter surrounding pieces learn and adapt. That means you get the power of a sophisticated AI model without paying the full computational cost of retraining it every time.
How frozen language weights anchor the embedding pipeline
The patent describes a two-part architecture: an encoder system that builds the search index, and a retrieval system that answers queries against it.
The encoder takes any input item — say, a product listing with both a description and a photo — and routes each type of content through its own dedicated sub-model. The text goes through one machine-trained model, the image through another. Their outputs are then combined into a single unified representation, which is then passed through a language-based embedding-mapping system (think of it as a translator that converts any input into a standardized 'address' in the index). The key property: multiple different expressions of the same concept — a photo, a caption, a detailed description — all land at the same address.
The retrieval side works in two stages:
- First, it generates a candidate set of likely matches quickly (a broad net).
- Then it runs a more careful filtering pass to rank and narrow those candidates to the most relevant results.
The headline technical choice is that the language model weights are frozen — held constant during training. Only the surrounding, lighter components are updated. This is called a fixed-weight or frozen-backbone approach, and it dramatically reduces the compute needed to train the system while preserving the language model's broad knowledge. The system also monitors the hardware it's running on and throttles how much work it does based on available resources.
What this means for AI-powered enterprise search
For enterprise software — think Microsoft 365, SharePoint, or Azure AI Search — this kind of unified index is a significant practical improvement. Today, companies often maintain separate search indexes for documents, images, and structured data. A system that collapses those into one coherent index would simplify IT infrastructure and surface more relevant results across content types. You might eventually notice this as the search bar in your company's intranet getting noticeably better at finding things regardless of whether you type a keyword or paste an image.
The frozen-language-model angle is also strategically telling. Microsoft has invested enormously in large language models through its OpenAI partnership. A system that reuses those models' knowledge without retraining them is a cost-efficient way to extend that investment into specialized retrieval tasks — potentially making powerful AI search viable for mid-sized organizations that can't afford to fine-tune massive models from scratch.
This is quietly important infrastructure work. The 'freeze the language model, train only the edges' approach is a well-understood research strategy, but patenting a full production architecture around it — including the hardware-throttling angle — suggests Microsoft is actively engineering this for real deployment, not just publishing a research result. If this lands inside Azure AI Search or Microsoft 365 Copilot, it could meaningfully close the gap between how enterprise search works today and how it probably should work.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.