Microsoft Patents a Sequence-Prediction Model That Drops Positional Encoding
Microsoft is filing a patent for a transformer-style neural network that predicts what a user will do next — and it deliberately rips out one of the standard components most people assume is essential to how these models work.
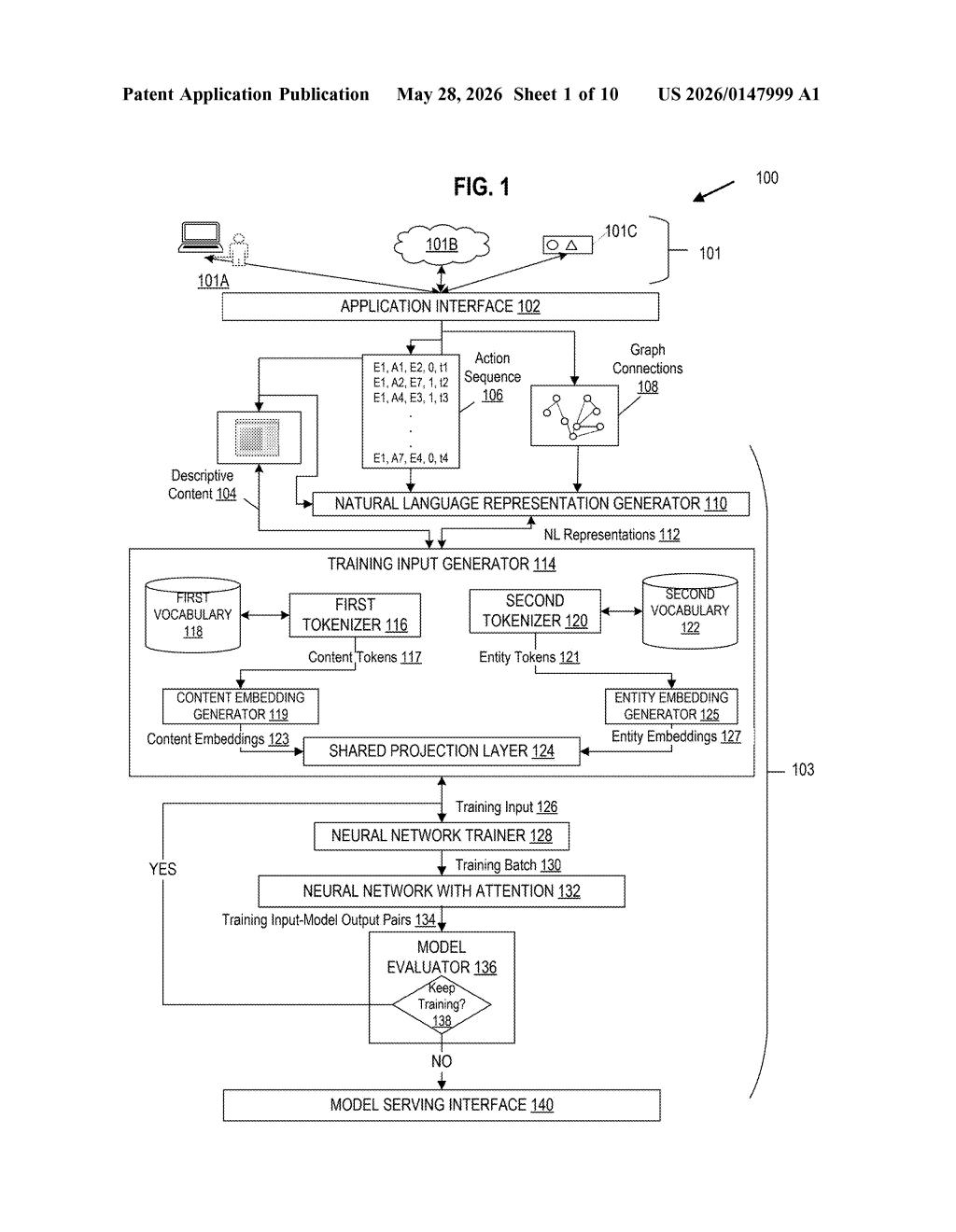
What Microsoft's action-sequence prediction model actually does
Imagine your work software quietly watches what you do — open a file, run a search, click a button — and learns to predict what you'll need next. That's the core idea here.
Microsoft's patent describes a neural network trained on sequences of user actions logged on a device. Instead of using standard language tokens (like words from a dictionary), it uses a custom vocabulary built specifically around app commands and reserved action words. Think of it like teaching the model to speak in "app-action language" rather than regular English.
The clever twist: Microsoft is intentionally leaving out the part of the model that tracks the order of events (called a "position encoder"). The bet is that for user behavior, what actions happened matters more than precisely where in a sequence they fell — so removing that component may actually make the model leaner and more effective for this specific job.
How the tokenizer and attention model process user actions
The patent centers on adapting a transformer-based neural network (the "neural network model with attention" — the same architecture behind GPT-style models) for a very specific task: predicting sequences of user actions on a device.
Two key design choices define it:
- Non-standardized tokenizer: Instead of a vocabulary built from natural language, the model uses a custom tokenizer that converts reserved words — essentially named commands or action labels logged by an app — into word-based tokens. This means the model's vocabulary is purpose-built for user behavior, not general text.
- Omitted position encoder: Standard transformers include a positional encoding layer that tells the model where each token sits in a sequence (first word, second word, etc.). This patent deliberately removes that layer. The reasoning implied is that user-action sequences may not have strict positional dependencies the way sentences do — the model can rely on the attention mechanism alone to find patterns.
The attention mechanism (the part that lets the model weigh relationships between any two tokens, regardless of distance) is kept intact. So the model can still detect that certain actions tend to cluster or follow each other — it just doesn't need an explicit counter tracking their position.
The training setup feeds the model action sequences from a first entity (a user or account), suggesting this is designed for personalized or per-entity behavioral modeling.
What this means for behavioral AI in Microsoft products
Predicting what a user will do next is valuable across a huge range of Microsoft products — from Copilot suggestions in Office to anomaly detection in enterprise security tools like Microsoft Sentinel. A lightweight model that strips out unnecessary components could run more efficiently at scale, or on-device, without sacrificing much accuracy for this narrow task.
The positional-encoding removal is the genuinely interesting engineering call here. If it holds up empirically, it suggests a class of behavioral prediction problems where co-occurrence matters more than strict sequence order — which could influence how other teams build similar models. For enterprise customers, a model that understands action patterns could quietly power smarter workflow suggestions or faster threat detection.
This is quiet infrastructure work, not a flashy AI announcement — but the deliberate omission of positional encoding is a real architectural claim worth scrutiny. If Microsoft can show that attention alone is sufficient for user-action sequence modeling, that's a useful data point for anyone building behavioral AI. The patent is narrow and highly technical, but it hints at ongoing investment in personalized, on-device behavioral prediction that could surface in Copilot or security products.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.