Nvidia Patents an API That Stores Compressed Video With Its Own Decompression Instructions
Nvidia is patenting a way for a GPU to store compressed video data together with a built-in recipe for how to decompress it — turning the memory allocation step itself into a self-describing operation.
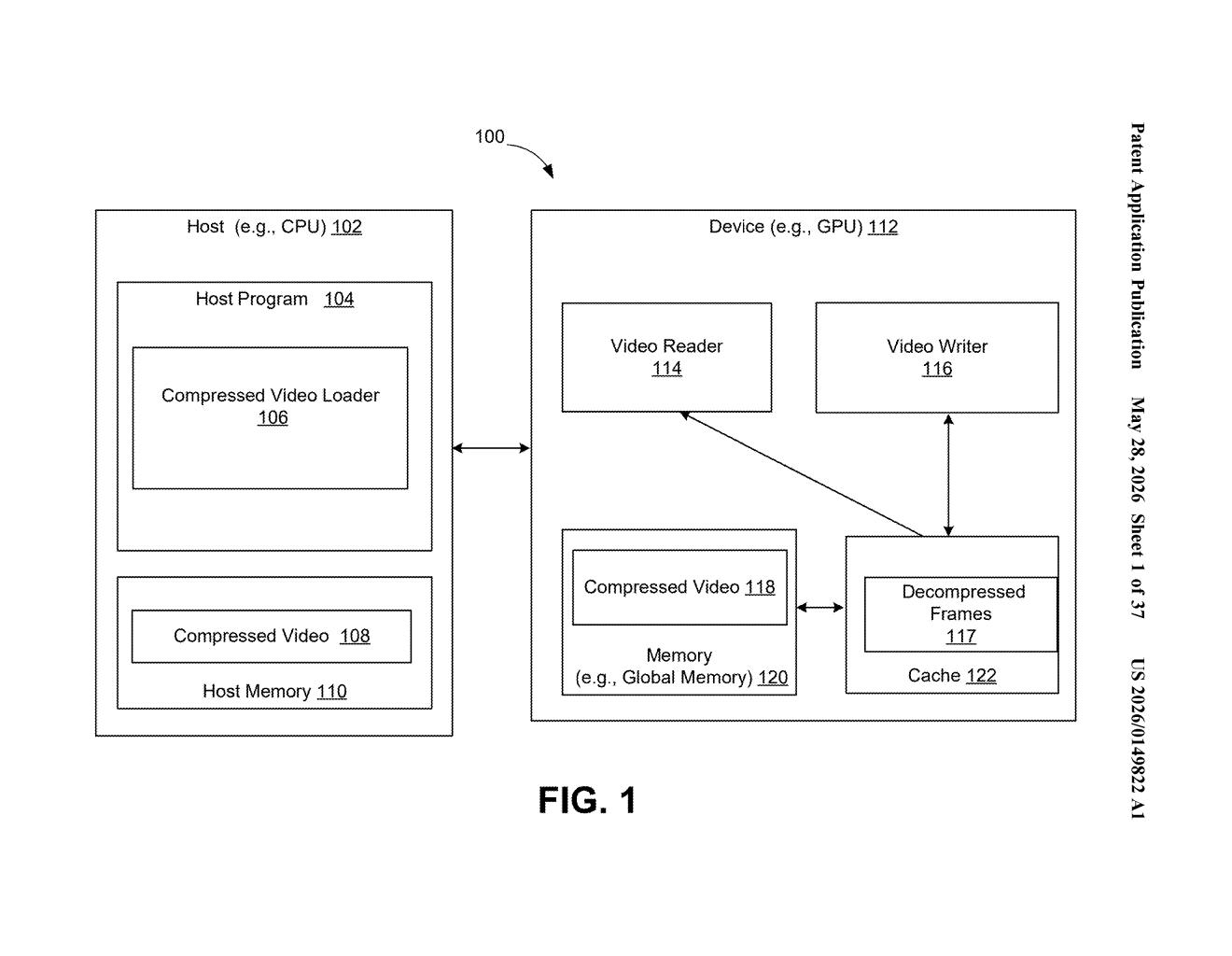
What Nvidia's compressed-video API actually stores
Imagine downloading a ZIP file that came with its own unzip program baked right into the archive. You'd never have to hunt for the right tool — it's already there. That's roughly the idea behind this Nvidia patent.
When a GPU needs to work with compressed video, it typically has to track separately which algorithm was used to compress it so the right decompressor can be applied later. This patent describes an API — a standardized programming interface that developers call from their code — that bundles compressed video data and a pointer to the correct decompression algorithm together in one memory allocation step.
The result is that any software reading that memory block knows exactly how to unpack it, without needing external bookkeeping. For developers writing GPU video pipelines, that's one fewer thing to manage manually.
How the GPU pairs video data with decompression metadata
At its core, this patent describes a processor (specifically targeted at GPU hardware like Nvidia's own devices) that responds to an API call by doing two things simultaneously: storing the compressed video payload and storing metadata indicating which decompression algorithm or algorithms apply to that payload.
The claim is intentionally broad — it doesn't lock down a specific codec or memory layout. Instead, it describes a general mechanism where the act of allocating memory for compressed video automatically associates that allocation with decompression instructions. Think of it like a typed memory buffer: instead of a plain blob of bytes, you get a blob that knows its own type.
The system diagram in the patent shows a typical GPU video pipeline:
- A Video Reader ingests compressed video
- The GPU's global memory stores both the compressed frames and decompression algorithm indicators
- A Video Writer outputs decompressed frames
The key insight is that the API call — the hook a developer uses to trigger memory allocation — becomes the integration point where compression metadata gets attached, rather than requiring a separate bookkeeping layer in application code.
What this means for GPU video memory efficiency
GPU memory is a finite, expensive resource, and video workloads — especially at high resolutions or in multi-stream inference pipelines — burn through it fast. By keeping video compressed in memory and tagging it with decompression instructions at allocation time, Nvidia's approach could let developers write cleaner, less error-prone GPU video code. It reduces the chance that data and its decoding context get out of sync.
For Nvidia, this has obvious relevance to its video codec hardware (NVENC/NVDEC) and to AI inference workloads that increasingly process video at scale. If this API pattern gets baked into CUDA or a video SDK, it would nudge the whole ecosystem toward a more structured, self-describing approach to compressed media on the GPU.
This is a fairly narrow infrastructure patent — it's not describing a new compression algorithm or a new GPU architecture. It's patenting a specific API contract: the idea that an allocation call should co-locate compressed data with its decompression metadata. That's a sensible software engineering pattern, and filing a patent on it is more about defensive positioning in the GPU video pipeline space than staking out genuinely novel technical ground.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.