Nvidia Patents a System That Shrinks AI Models to Fit Your Hardware
What if an AI model could automatically trim itself down when running on a slower chip — and expand back when more power is available? That's the core idea behind Nvidia's latest patent.
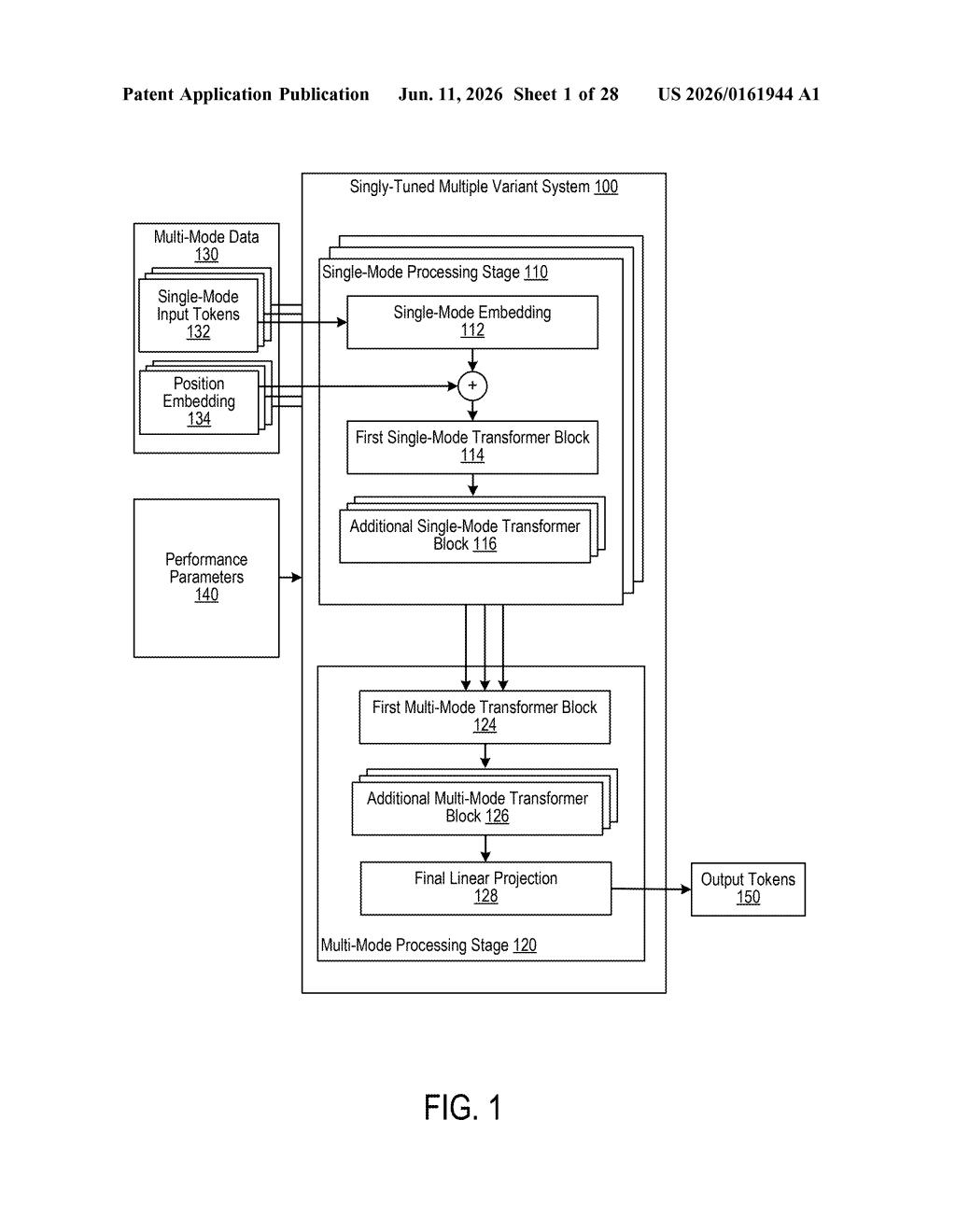
How Nvidia's on-the-fly AI resizing actually works
Imagine you're streaming a movie, and your internet slows down — so the service automatically drops from HD to standard definition to keep things playing smoothly. Nvidia's patent applies a similar idea to AI models.
The system lets a processor turn sections of an AI model on or off depending on how much computing power is available. A user or system administrator can set performance targets — like a speed limit or a power budget — and the AI adjusts itself to stay within those limits.
The practical upshot: the same AI model could run in a stripped-down version on a laptop or edge device, and at full capacity on a powerful server — without needing two completely separate models. You get flexibility without the maintenance headache.
How the processor decides which network sections to cut
The patent describes a processor architecture containing circuits that can selectively enable or disable portions of one or more neural networks at runtime. Rather than loading a fixed model that always uses the same number of computational steps, the system consults user-configurable performance indicators — essentially knobs or thresholds set in advance — to decide how much of the model to actually run.
Those indicators could represent things like available memory bandwidth, thermal limits, power draw caps, or target inference speed (how fast the model needs to produce an answer). When conditions are tight, whole sections of the network — layers, branches, or sub-modules — get switched off. When headroom opens up, they switch back on.
- Multiple variants in one: Instead of shipping separate lightweight and full-fat model files, a single model file contains all variants, with circuitry deciding which parts are live.
- User-configurable thresholds: Developers or IT admins can define what "acceptable performance" means for their deployment.
- Hardware-aware execution: The processor itself — not an external scheduler — drives the enable/disable decisions in real time.
This is related to a broader research area sometimes called dynamic inference or early-exit networks, but Nvidia's framing here is tightly coupled to the processor's own performance metrics rather than the confidence of the model's output.
What this means for AI on lower-powered devices
For Nvidia, this patent has obvious relevance to its increasingly broad hardware portfolio — from data center GPUs down to edge inference chips like the Jetson line. A single AI deployment that self-adjusts based on the chip it lands on would be a significant operational convenience for customers managing fleets of heterogeneous hardware.
For you as an end user, the downstream effect could be AI features that stay functional on older or lower-powered devices rather than being disabled outright. It also hints at better battery life on AI-powered gadgets — the model does less work when you don't need full accuracy, saving power without requiring you to think about it.
This is solid, practical infrastructure work — not flashy, but genuinely useful. The ability to ship one model that adapts to wildly different hardware is a real pain point for anyone deploying AI at scale, and Nvidia is well-positioned to bake this directly into silicon rather than leaving it to software workarounds. Worth watching as Nvidia pushes deeper into the edge and automotive AI markets.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.