Nvidia Patents a Hierarchical Image Generator That Refines and Upscales in Tandem
Nvidia's latest patent combines two popular AI image-generation tricks — masked prediction and progressive resolution scaling — into a single unified architecture that produces high-quality images in fewer steps than either approach alone.
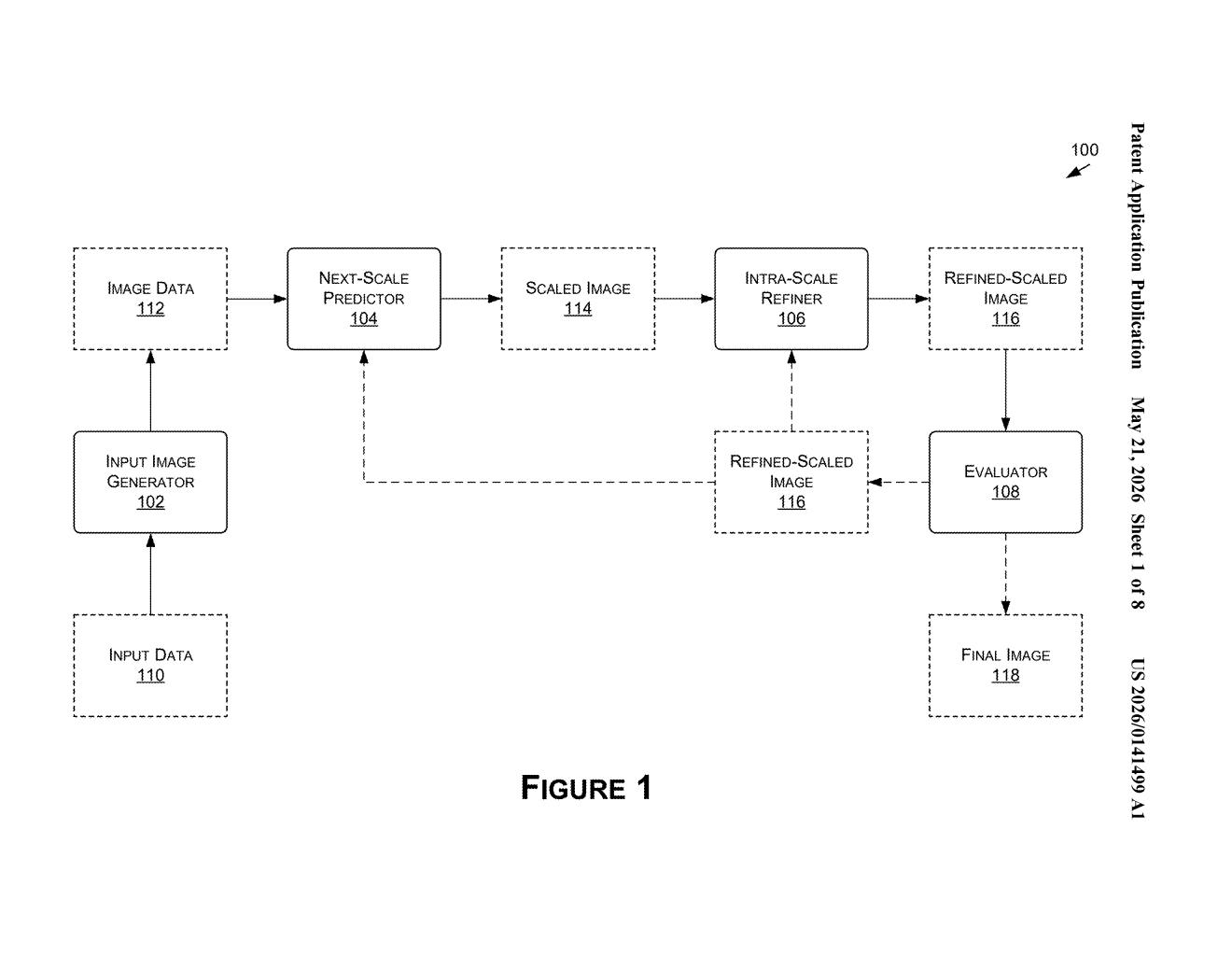
How Nvidia's HMAR system builds images from the ground up
Imagine building a jigsaw puzzle by starting with a blurry thumbnail, filling in the missing pieces, then zooming in and filling in more detail — over and over until you have a crisp, full-size picture. That's roughly what Nvidia's new system does.
Most AI image generators either work at a fixed resolution and refine the whole image at once, or they scale up piece by piece. Nvidia's patent describes a process that does both at the same time: start small, refine the fuzzy parts using the clear parts as context, then jump to the next resolution level and repeat.
The result, according to the filing, is a system that reaches a high-resolution final image in fewer computational steps than conventional approaches — which matters a lot when you're trying to run image generation quickly or cheaply, whether on a data center GPU or something closer to the edge.
How masking and next-scale prediction interleave in HMAR
The patent describes an architecture called HMAR (Hierarchical Masked Auto-Regressive) that fuses two distinct generation strategies:
- Next-scale prediction: the model starts with a low-resolution image and progressively generates higher-resolution versions, one level at a time — similar to how VAR (Visual Auto-Regressive) models work.
- Masked prediction: within each resolution level, portions of the image are masked (hidden), and the model reconstructs those missing regions using surrounding visible pixels — the same core idea behind masked image models like MAR.
The key technical move is reformulating the next-scale step as a Markovian process (meaning each resolution level depends only on the immediately preceding one, not the full history). This keeps computation tractable as the image scales up.
Between each upscaling step, the system runs an intra-scale refinement loop: it iteratively masks and reconstructs different patches of the image at the current resolution before committing to the upscale. Only once a resolution level is sufficiently refined does the model advance to the next scale.
The claimed method is intentionally general — mask a portion, refine it using the unmasked context, then generate a higher-resolution version. The architecture diagram in the filing shows three distinct modules: a next-scale predictor, an intra-scale refiner, and an image generator that combines their outputs.
What faster image generation means for Nvidia's AI stack
For Nvidia, this sits squarely inside the booming demand for fast, high-quality generative image models — used in everything from game asset pipelines to medical imaging to video production. Reducing the number of inference steps directly cuts the compute cost per image, which is real money at scale when you're running thousands of GPUs.
From a competitive standpoint, if this approach delivers on its speed claims, it could give Nvidia a proprietary architectural edge when bundling image generation into its software platforms (like Picasso or future NIM microservices). For developers, fewer steps means lower latency — which opens the door to more interactive, real-time creative tools that wouldn't be practical with today's slower diffusion pipelines.
This is genuinely interesting applied research — not a product announcement, but a real architectural contribution that tackles a known pain point in generative image models (too many inference steps, too slow). The combination of masked and next-scale prediction into a single Markovian framework is a clean idea, and if the quality-speed tradeoff holds up, expect to see versions of this show up in Nvidia's inference stack within a couple of years.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.